Full Attention Strikes Back: Transferring Full Attention into Sparse within Hundred Training Steps [2026]
Introduction
Long-context inference는 full attention의 quadratic cost에 발목 잡힘. 이를 줄이기 위한 기존 efficient 대안은 크게 두 갈래 — Kimi Delta Attention·DeepSeek Sparse Attention처럼 native sparse training을 하거나, heuristic하게 token을 eviction하는 방식. 둘 다 efficiency·training cost·accuracy 사이의 바람직하지 않은 trade-off를 만듦.
이 논문의 주장은 도발적임 — full attention으로 학습된 LLM은 이미 본질적으로 sparse하며, 최소한의 수술(minimal surgery)만으로 고도로 sparse한 모델로 전환할 수 있다. sparsity는 head level(대부분 head는 local 정보에 의존)과 token level(각 query마다 소수 token만 큰 attention mass를 받음) 모두에서 나타남. 그렇다면 핵심 질문은 “full-attention 모델을 능력 손실 없이 sparse하게 바꾸는 데 필요한 최소한의 수술은 무엇인가?”
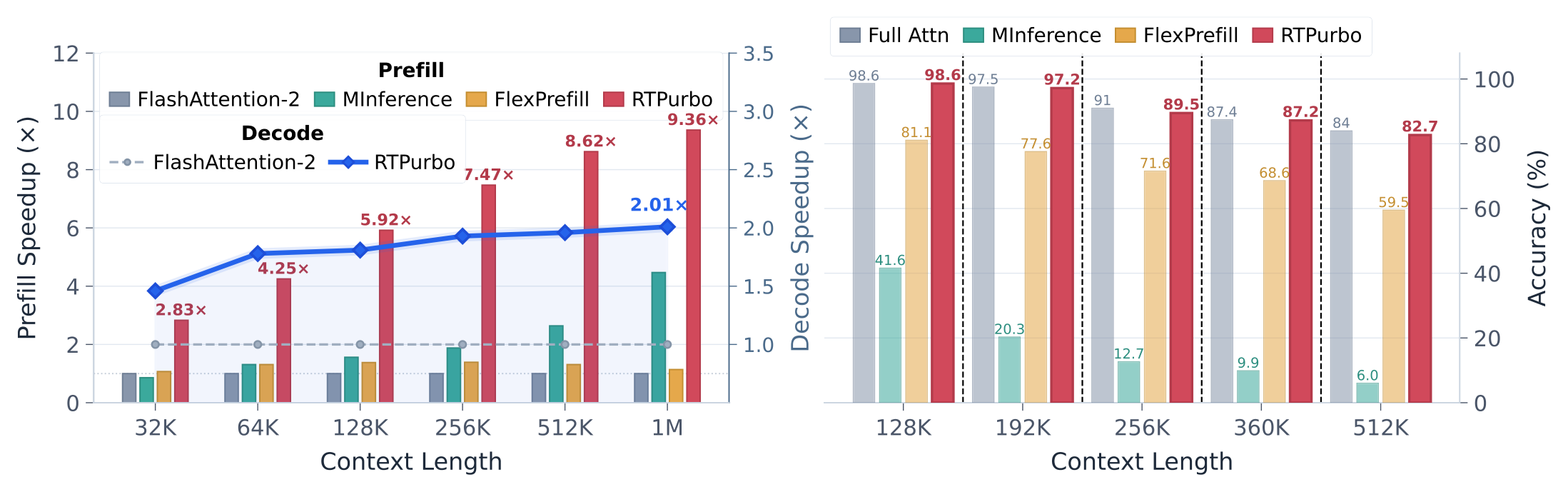
연구진은 세 가지 challenge를 짚음 — (1) full-context가 정말 필요한 head를 식별하는 head selection, (2) 필요한 token을 효율적으로 찾는 token indexing, (3) query마다 다른 token 수에 대응하는 adaptive sparsity. 제안 방법 RTPurbo는 retrieval head에만 full KV cache를 유지하고 경량 token indexer를 도입해 이 셋을 해결하며, 수백 step 학습만으로 near-lossless 압축을 달성함 — custom kernel과 함께 prefill 최대 9.36×(1M context), decode 약 2.01× speedup.
Insight: 왜 RTPurbo가 동작하는가
1. Head Specialization — 일부 head만 retrieval을 담당
사전학습된 LLM의 attention head는 동질적이지 않고 기능적으로 분화돼 있음. 멀리 떨어진 관련 내용을 검색하는 소수의 head(retrieval head)가 있고, 나머지는 주로 local 정보를 처리함. retrieval head는 의미적으로 관련된 과거 context에 강한 attention을 두는 information-retrieval 패턴을 보임. 아래 layer-head heatmap을 보면 retrieval score가 높은 head가 전체 중 소수에 집중돼 있음을 확인할 수 있음.
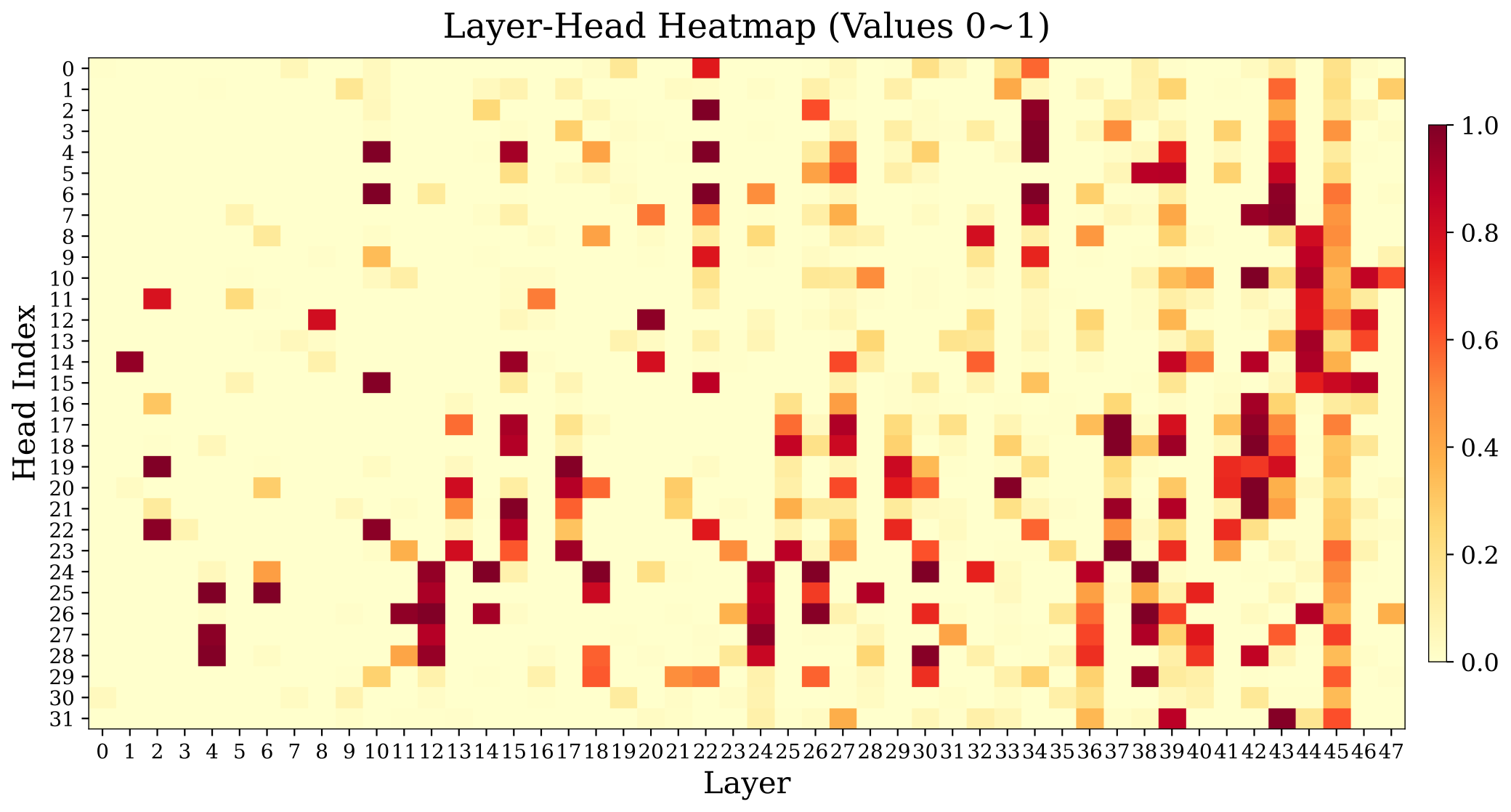
따라서 모델이 이미 형성해 둔 sparsity 구조를 그대로 활용 가능 — retrieval head에만 full KV cache를 유지하고, 이미 본질적으로 sparse한 나머지 head는 remote token을 안전하게 버림.
2. RoPE가 만드는 압축 가능한 geometry — low-dim subspace
retrieval head는 멀리 있어도 의미적으로 관련된 token에 높은 attention을 줘야 하는데, 이는 언뜻 RoPE와 상충하는 것처럼 보임. position $m$, $n$의 query·key score는 relative offset $\Delta = m - n$에만 의존함:
\[s(m, n) = q_m^\top k_n = \sum_{i=1}^{D} \left[ a_i(q,k)\cos(\theta_i \Delta) + b_i(q,k)\sin(\theta_i \Delta) \right]\]여기서 high-frequency 성분은 $\Delta$에 따라 빠르게 변해 long-range에서 distance-sensitive해지는 반면, low-frequency 성분은 부드럽게 변해 retrieval signal을 잘 보존함. 즉 retrieval-head attention을 훨씬 낮은 차원의 공간에서 재구성할 수 있음. 실제로 학습된 low-dim projector로 단 16차원에서 90% 이상의 recall을 달성함.
3. Dynamic Thresholding — token budget은 query에 따라 다르다
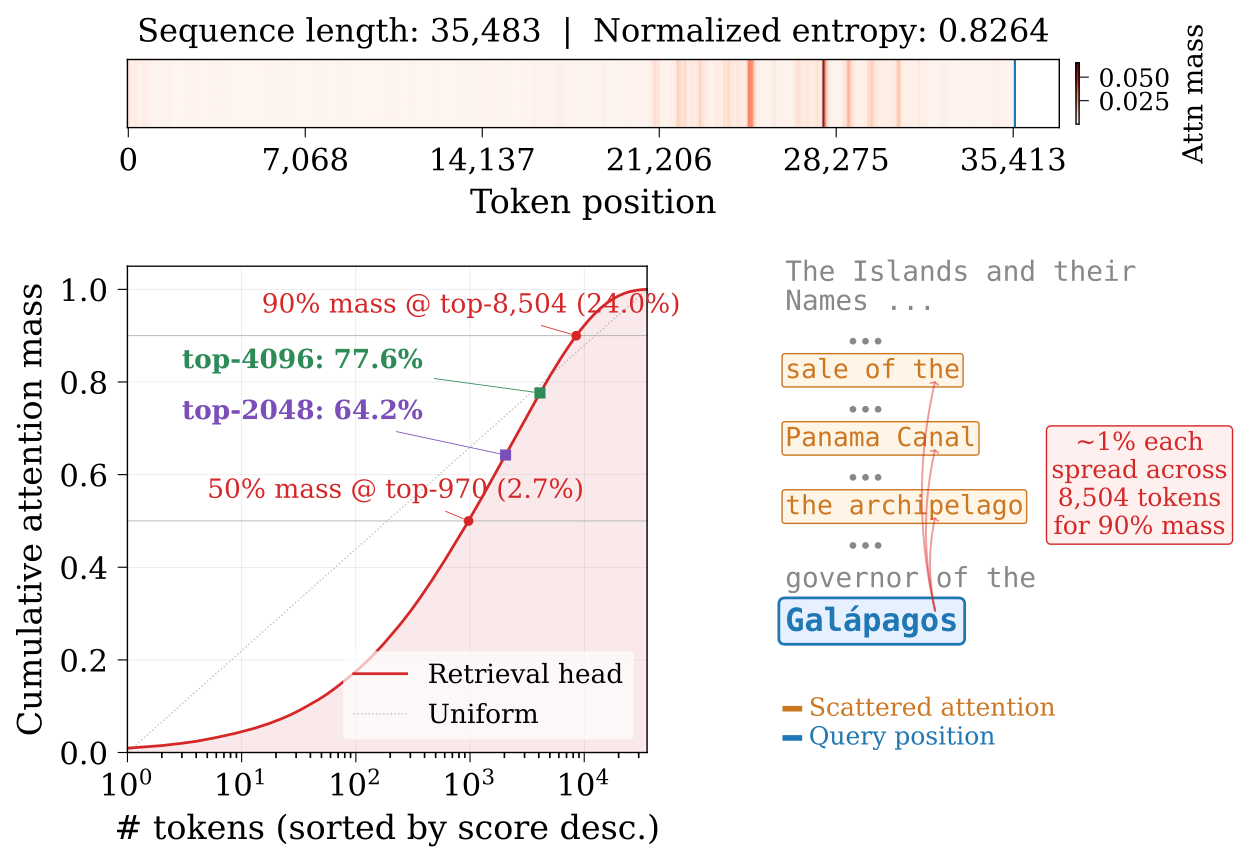
retrieval head가 보존해야 할 token 수는 본질적으로 query-dependent함. 어떤 query는 많은 distant token에 걸친 broad retrieval을 유발하고(“Galápagos” 같은 광범위한 의미장), 어떤 query는 단 하나의 key fact에만 집중함(needle-in-a-haystack). 따라서 fixed top-k는 부적합 — $k$가 작으면 diffuse query에서 attention mass를 너무 적게 회수하고, 크면 충분히 sparse하지 못해 연산을 낭비함. 논문의 Table 1에 따르면 top-16k는 dynamic top-p보다 attention mass를 3.8%만 더 회수하면서 약 8k token을 더 계산함. 어떤 고정 $k$도 query-dependent한 특성에 맞지 않음 → dynamic top-p가 해법.
Method
Offline head-wise calibration
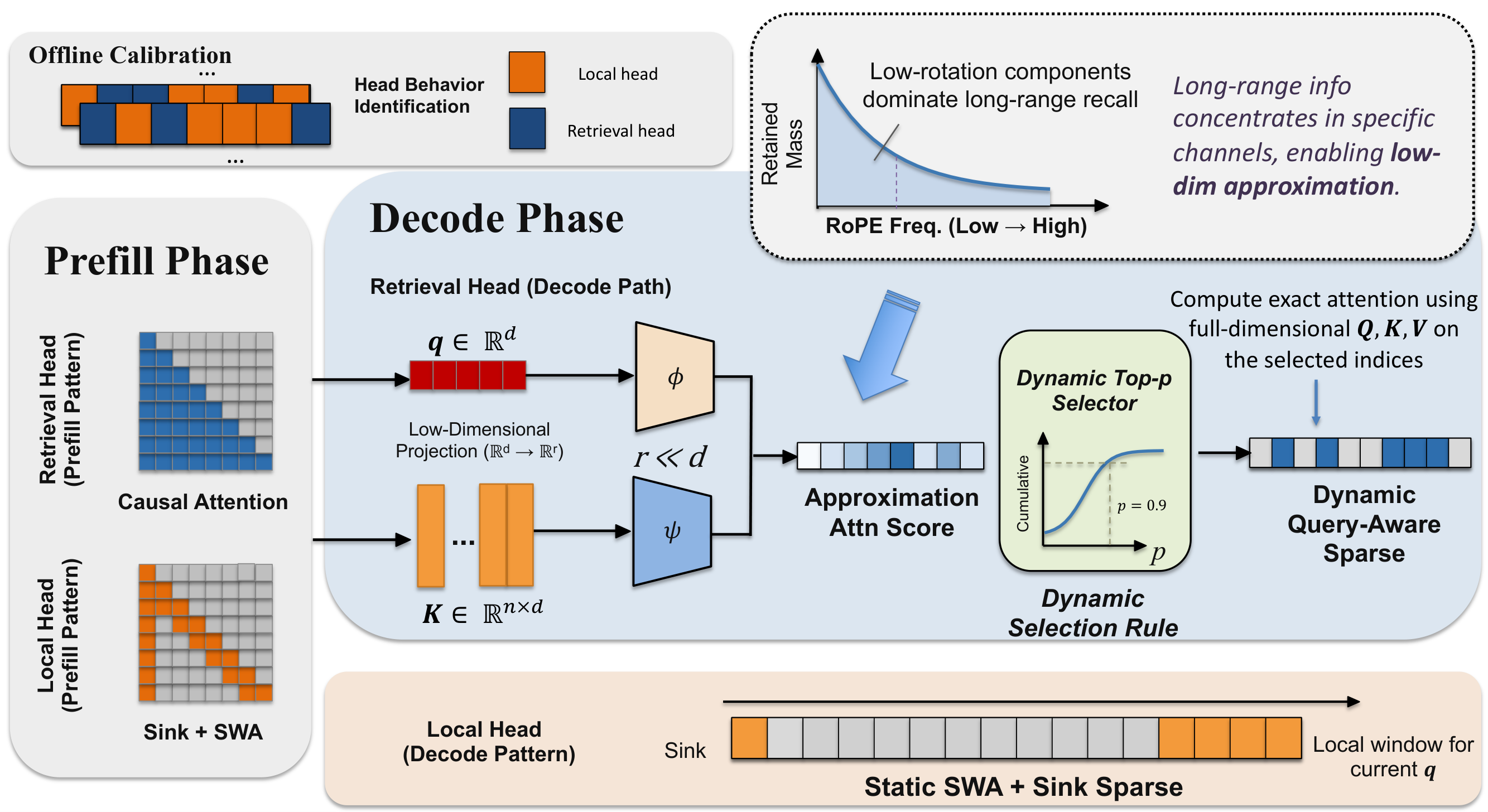
retrieval head를 식별하기 위해, FineWeb에서 뽑은 긴 문서의 앞·뒤에 동일한 “needle” span을 삽입한 calibration sequence를 만듦. 뒤쪽 needle에서 앞쪽 needle로 향하는 attention mass로 head의 retrieval score $R_h$를 측정함. head의 retrieval 행동은 매우 안정적이고 input-agnostic해서, 단 하나의 긴 시퀀스로 한 번만 calibration하면 모든 query head를 retrieval set $H_\text{ret}$와 local set $H_\text{loc}$로 robust하게 분할 가능.
Adaptive sparse attention
local head는 prefill·decode 모두에서 sliding window + attention sink를 적용함. retrieval head는 prefill에선 full dense attention으로 KV cache를 완성하고, decode에선 query-aware dynamic sparse selection으로 전환함. high-frequency RoPE 성분의 간섭을 피하기 위해, RoPE 주입 이전(pre-RoPE) feature에 low-rank projection $W^Q_h, W^K_h \in \mathbb{R}^{r \times d_h}$ ($r \ll d_h$)을 적용해 relevance를 추정함:
\[s_h(m, n) = (W^Q_h q^\text{pre}_{m,h})^\top (W^K_h k^\text{pre}_{n,h}), \quad S_h(m) = \text{Top-}P(s_h(m, \cdot), p)\]이 low-rank projection은 효율적인 routing 용도로만 쓰이고, 실제 token 생성은 full feature space와 정확한 relative positional geometry를 그대로 보존함.
Low-cost two-stage training
- Stage 1: backbone을 freeze하고, retrieval head별 low-dim projection $W^Q_h, W^K_h$만 독립적으로 학습. 원본 exact attention 분포와 projected score 분포 간 KL divergence를 최소화.
- Stage 2: 학습된 projection을 끼우고 sparse mode로 전환해 end-to-end self-distillation. sparse 모델(student)이 dense teacher의 next-token 예측을 따라가며, 연산을 줄이기 위해 top-10 logit만 정렬함. self-distillation은 SFT와 달리 특정 dataset 분포의 부작용을 우회해 data mixture 튜닝이 불필요. 이 정렬은 평균 48K 길이 corpus에서 약 600 step(~1M label token)이면 충분함.
Hardware-aware top-p decoding kernel
block-wise top-p sparse decoding을 위한 custom GPU kernel을 구현함. (1) sort-free top-p — 정렬 없이 256-bin histogram(head당 1KB, seq length 무관)에 atomic하게 점수를 쌓고, 마지막 CTA가 histogram을 스캔해 cumulative mass가 $p_\text{top}$에 도달하는 threshold를 찾아 block mask를 작성. scoring과 selection을 단일 kernel launch로 융합. (2) bandwidth-optimized decoding — single-warp CTA로 state를 register에 유지하고 vectorized load로 memory-bound 구간을 최적화.
Experiments
H20 GPU(Python 3.14 / CUDA 12.8 / PyTorch 2.8)에서 lm-eval로 평가함. long-context엔 Qwen3-Coder-30B-A3B, reasoning엔 Qwen3-30B-A3B-Think를 사용. 주요 config는 retrieval head ratio 15%, sliding window 8192, sink 4, low-dim size 16, top-p 0.9. baseline은 RazorAttn·Minference·FlexPrefill·Quest·SnapKV이며, dynamic budget의 이점을 격리하기 위해 static top-k($k$=4096) 변형도 직접 구현함.
정확도 — near-lossless
| Method | LongBench Avg. | RULER 32K | RULER 64K |
|---|---|---|---|
| Full Attn | 53.80 | 89.65 | 86.23 |
| RazorAttn | 52.98 | 88.69 | 85.11 |
| Minference | 48.39 | 83.58 | 65.61 |
| FlexPrefill | 49.42 | 83.40 | 77.77 |
| Quest | 50.69 | 78.97 | 70.60 |
| SnapKV | 50.74 | 83.43 | 75.81 |
| RTPurbo (top-k) | 53.30 | 84.36 | 70.53 |
| RTPurbo (top-p) | 54.24 | 90.06 | 85.49 |
RTPurbo(dynamic top-p)는 sparse 방법 중 모두 1위이며, LongBench(54.24)·RULER 32K(90.06)에선 Full Attention조차 근소하게 상회함. 특히 RULER 64K에서 top-p는 85.49로 near-lossless인 반면 top-k 변형은 70.53으로 급락 — query-dependent budget이 충분한 attention mass를 보존하는 데 결정적임을 보여줌. reasoning task에서도 AIME에서 dense baseline과 동일한 86.67을 기록하고 MMLU-PRO 전 subject에서 full-attention과 거의 차이가 없음.
효율 & ultra-long robustness
prefill에선 sparsity가 결정적(deterministic) — retrieval head 15%만 dense, local head 85%는 sink 4 + window 8192만 봄. decode에선 dynamic top-p가 작동해, Qwen3-Coder-30B-A3B의 Layer 25를 프로파일하면 32K에서 niah-S는 468.8 active token만 유지하지만 multi-K에선 2462.1로 동적으로 확장됨(5× 변동). 이렇게 on-the-fly로 적응하면서 attention mass >0.93을 유지하고 64K에서 최대 89.2% sparsity를 달성함. ultra-long(최대 512K)에서 MInference·FlexPrefill이 catastrophic하게 붕괴하는 동안 RTPurbo는 정확도를 robust하게 유지함.
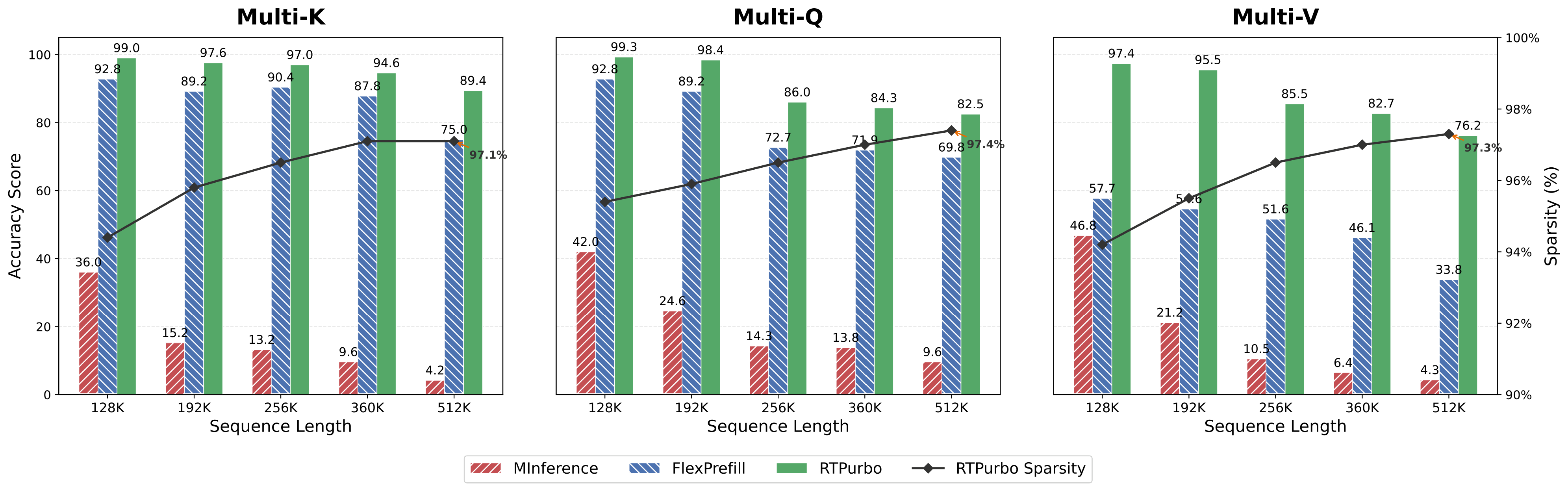
정리
RTPurbo는 (1) retrieval head에만 full KV cache를 유지하는 head-wise 설계, (2) RoPE 저주파 구조를 이용한 16-dim indexer, (3) query-dependent한 dynamic top-p, (4) 경량 self-distillation을 결합해, full-attention 모델을 수백 step만에 near-lossless sparse 모델로 전환함. 핵심 메시지는 명확함 — 값비싼 native sparse pretraining 없이도 표준 full-attention 학습 모델에서 강력한 sparse inference를 끌어낼 수 있으며, 따라서 full-attention training은 여전히 경쟁력 있는 실용적 선택지라는 것.