SearchSwarm - Towards Delegation Intelligence in Agentic LLMs for Long-Horizon Deep Research [2026]
Introduction
LLM이 점점 더 복잡하고 long-horizon한 실제 task의 agent로 쓰이고 있음. 이런 task는 context 요구량이 끝없이 늘어날 수 있으나, 모델의 context window는 본질적으로 유한함. 기존의 context 관리 방식(일정 길이를 넘으면 history를 요약하거나, tool output 일부만 남기는 방식)은 passive함 — 사전 계획 없이 context budget이 바닥날 때까지 기다렸다가 잘라냄.
이에 대한 더 active한 대안이 main-distributes, sub-executes 패러다임. main agent가 task를 미리 분해하고 bounded subtask를 subagent에 위임한 뒤, subagent의 요약된 실행 결과만 회수함. 이를 잘 수행하려면 delegation intelligence가 필요함: (1) 복잡한 task를 분해하고, (2) 언제 무엇을 위임할지 판단하며, (3) 돌아온 결과를 진행 중인 workflow에 통합하는 능력. 문제는 이런 능력을 학습할 데이터가 자연 텍스트에 거의 없고, 오픈소스 진영에서 이런 데이터를 어떻게 합성하고 학습시킬지가 거의 탐구되지 않았다는 점.
연구진은 대표적인 long-horizon task인 deep research를 대상으로, inference 시점에 고품질 delegation 행동을 끌어내는 harness를 설계하고, 그 trajectory를 SFT 데이터로 정제해 모델 가중치에 내재화함. 결과 모델 SearchSwarm-30B-A3B는 BrowseComp 68.1, BrowseComp-ZH 73.3으로 동급 규모 모델 중 최고 성능을 달성함.
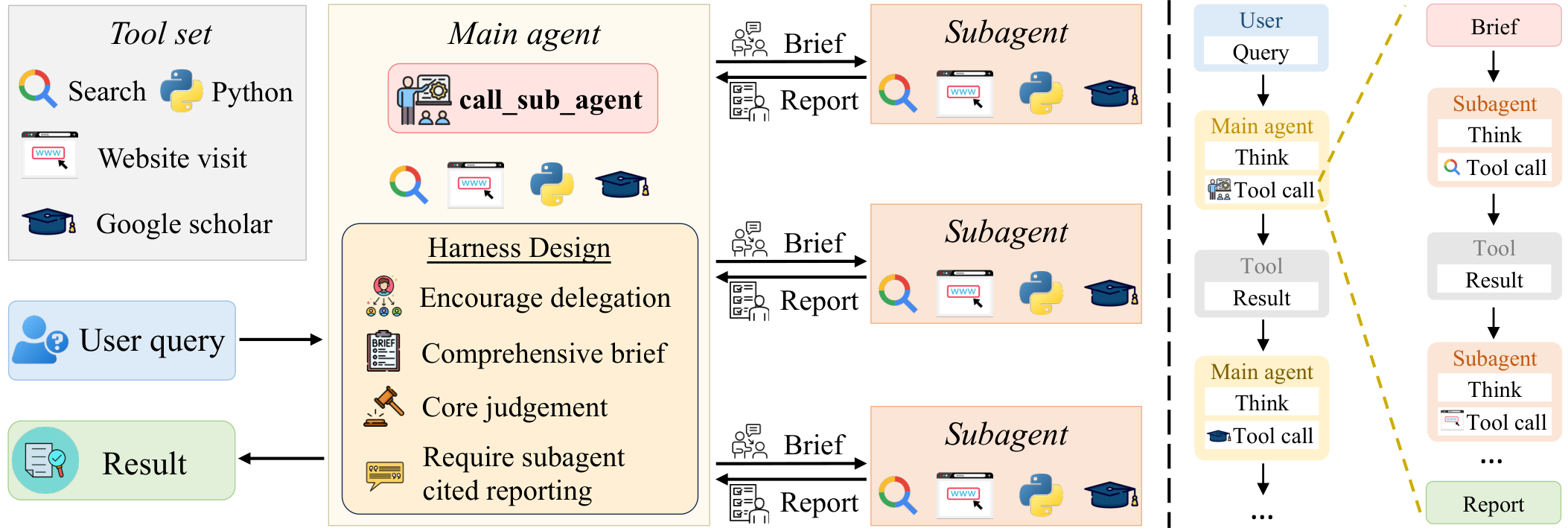
Method
main-distributes, sub-executes
ReAct framework를 채택해 각 step을 Thought / Action / Observation으로 구성. main agent의 tool set은 search, visit, google_scholar, python에 더해 핵심 위임 도구인 call_sub_agent로 이루어짐. call_sub_agent(b)를 호출하면 brief $b$를 받은 subagent가 독립된 context에서 자체 multi-turn으로 subtask를 수행하고 압축된 report $r$만 반환함. main agent는 subagent의 중간 과정은 보지 못하고 최종 report만 관찰함. subagent는 동일한 standard tool을 갖지만 call_sub_agent는 없어 위임은 single-level로 제한됨.
흥미로운 관점은 이 구조가 multi-agent가 아니라 single-agent context management라는 것. subagent는 별도 모델이 아니라 동일 모델을 fresh context로 다시 부른 것이며, brief와 report는 모두 모델이 생성함. 즉 고정 규칙 기반의 truncation/summarization 대신, 모델이 생성한 brief·report를 content-aware compression으로 사용해 스스로 context를 더 똑똑하게 관리하는 셈. 덕분에 기존 context 관리 기법들과 동일 선상에서 공정한 비교가 가능함.
Harness Design
harness는 main/subagent용 tool set과 system prompt로 구성되며 4가지 원칙으로 delegation을 유도함:
- Encourage delegation — main agent의 context는 유한하므로, 토큰은 많이 쓰지만 인지적으로 얕은 정보 수집은 subagent에 넘기고, main agent의 주의는 planning·verification·synthesis 같은 고수준 조율에 집중시킴.
- Comprehensive briefing — brief는 subagent가 context를 받는 유일한 통로. 단순 지시만 주면 subagent가 헤매거나 이미 확인된 사실을 재조사함. 따라서 “새로 합류한 협업자에게 설명하듯” subtask의 의의, 지금까지 확립된 것, 불확실한 것, 시도했거나 배제한 방향까지 brief에 담게 함.
- Main agent retains core judgment — 전체를 조망하는 유일한 주체는 main agent. 어떤 가설을 추구할지, 언제 종료할지, 상충하는 report를 어떻게 조정할지 등 방향성 결정은 모두 main agent가 내리고, subagent는 증거 수집·가설 검증에 집중함.
- Citation-grounded reporting — main agent는 subagent의 중간 과정을 볼 수 없으므로, report의 모든 핵심 결론에 출처 URL inline citation을 달게 해 검증 가능성을 확보. 최종 응답에도 citation을 전파해 end-to-end traceability를 제공.
Supervised Fine-tuning
RedSearcher·OpenSeeker 쿼리에 harness를 적용해 deep research를 수행시키고, thinking·tool call·환경 반환을 포함한 전체 trajectory를 학습 데이터로 수집. 두 가지 config를 섞음: (1) 동일 모델이 main·sub를 모두 맡아 양쪽 trajectory를 모두 보존, (2) 강한 모델을 main, 약한 모델을 sub로 두고 main trajectory만 보존 — 신뢰도 낮은 subagent 결과가 main agent로 하여금 mainline을 더 엄격히 통제하게 만들어, 더 신중한 분해와 검증이 담긴 trajectory가 나옴.
필터링은 최종 답이 맞은 main trajectory만 남기고(대응하는 main이 맞을 때만 sub도 보존), 반복된 동일 tool call·존재하지 않는 출처를 인용하는 hallucination·tool 오용 같은 패턴을 제거. 학습은 environment masking next-token prediction으로, loss는 모델 출력(thinking·tool call)에만 걸고 환경 반환은 마스킹함.
\[\mathcal{L} = - \sum_{t=1}^{T} \sum_{j=1}^{|a_t|} \log p_\theta \left( a_t^{(j)} \mid a_t^{(<j)}, \tau_{<t} \right)\]Experiments
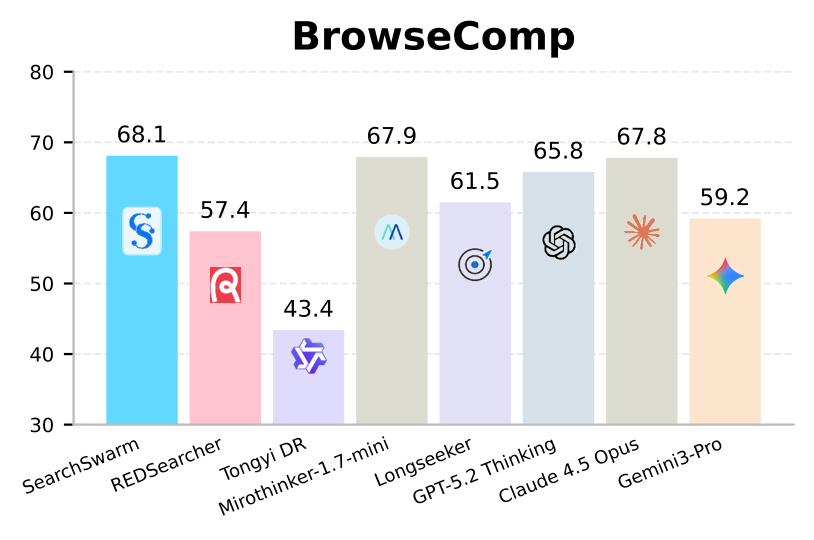
base model은 Tongyi DeepResearch-30B-A3B이며, BrowseComp·BrowseComp-ZH·GAIA·xbench-DeepSearch-2505 네 벤치마크로 평가함. (judge model은 DeepSeek-V4-Flash, 판정은 수기 검증)
| Model | Size | BrowseComp | BrowseComp-ZH | GAIA | xbench-DS |
|---|---|---|---|---|---|
| GPT-5.2-Thinking | – | 65.8 | 76.1 | – | – |
| Claude-4.5-Opus | – | 67.8 | 62.4 | 71.5 | – |
| Gemini-3.0-Pro | – | 59.2 | 66.8 | 74.8 | – |
| DeepSeek V3.2 | 671B-A37B | 67.6 | 65.0 | 75.1 | 78.0 |
| MiroThinker-1.7-mini | 30B-A3B | 67.9 | 72.3 | 80.3 | – |
| Tongyi DeepResearch (base) | 30B-A3B | 43.4 | 46.7 | 70.9 | 75.0 |
| SearchSwarm (Ours) | 30B-A3B | 68.1 | 73.3 | 82.5 | 80.8 |
SearchSwarm은 30B-A3B 규모 모델 중 네 벤치마크 모두에서 SOTA. 특히 context 관리가 없는 base model(BrowseComp 43.4) 대비 +24.7점의 절대 향상으로 delegation intelligence의 효과를 입증함. 나아가 10배 이상 큰 모델과도 경쟁력을 보여, BrowseComp에서 DeepSeek V3.2(671B-A37B, 67.6)와 대등하고 GPT-5.2-Thinking(65.8)을 능가함.
harness의 효과
200문항 BrowseComp subset에서 DeepSeek V3.2로 ablation을 수행: (1) 원래 Tongyi DeepResearch framework 47.7 → (2) call_sub_agent 도구를 schema만 알려준 경우 50.0 (+2.3) → (3) full harness 57.7 (+10.0). 도구만 제공하면 향상은 미미하고, 위임 장려·포괄적 brief·citation 보고 같은 설계 원칙을 갖춘 full harness에서 큰 폭의 향상이 나옴.
주목할 점은 harness만으로는 delegation이 생기지 않는다는 것. harness를 학습 없이 base model에 그대로 적용한 Tongyi DR Swarm은 call_sub_agent를 단 한 번도 호출하지 않고 base model과 동일하게 행동함. 즉 delegation 행동은 명시적 학습이 필요함.
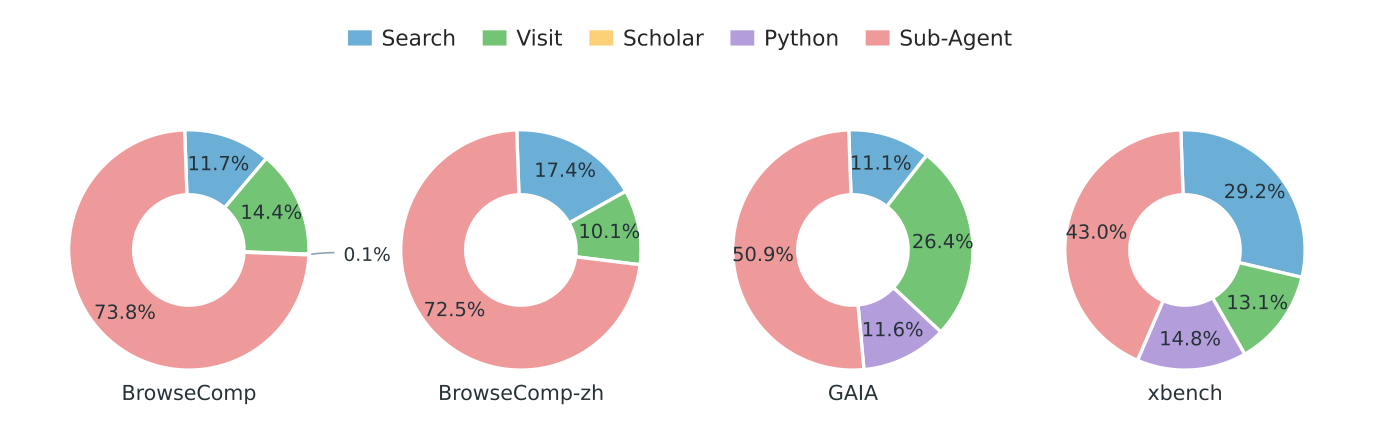
tool 사용 분포를 보면 SearchSwarm은 실제로 위임을 적극 활용함 — BrowseComp에서는 전체 tool 호출의 73.8%가 Sub-Agent 호출일 정도로, 학습을 통해 delegation이 행동으로 내재화됐음을 확인할 수 있음.
정리
SearchSwarm은 (1) main-distributes·sub-executes 패러다임을 위한 harness를 설계하고, (2) 그 harness로 고품질 delegation trajectory를 합성해 SFT로 모델에 내재화함으로써, 30B-A3B 경량 모델이 frontier 시스템과 경쟁하는 deep research 성능을 달성함. delegation을 별도의 multi-agent 시스템이 아니라 단일 모델의 능동적 context management로 재해석한 관점이 인상적이며, harness·weights·data를 모두 오픈소스로 공개함.