The Power of Scale for Parameter-Efficient Prompt Tuning [2021]
Introduction
ELMo 이래로 언어모델의 패러다임이 model tuning(=fine-tuning)으로 바뀌게 되었음. 더 최근에 prompt design(=priming)은 text-prompt를 통해 GPT-3 모델의 결과를 놀라울 정도로 효과적으로 만들어줬음. 프롬프트는 전형적으로 task description이나 몇몇의 canonical 예시로 구성되어있음. 특히 모델 사이즈가 계속해서 커져가는 추세에 이런 사전학습모델을 고정하는 방법론은 다소 매력적임. 각 downstream task에 맞춰 각각의 모델을 단순 copy 하는 방식보다 단일의 generalist model을 통해 동시다발적으로 다양한 task를 serving하는 방법론은 더 효율적임.
그러나 prompt-base 적용방식은 다소 몇가지 애로사항이 존재함. Task-description은 오류 발생이 쉽고 사람의 개입이 필요하며, 프롬프트의 효과는 모델의 input에 conditioning text가 얼마나 적합할 수 있는지에 따라 효과가 제한됨.
Li and Liang (2021)에서 “pre-fix tuning”을 연구했고 이는 일반적인 task에서 꽤나 강력한 결과를 보여줬음. 이 방법론은 모델의 파라미터를 freeze하고 input-layer, encoder stack에서 각각의 레이어 앞에 활성화함수를 prefix하여 model-tuning하는 동안 오류를 back-propagate함. 또한 Hambardzumyan et al. (2021)의 연구에선 masked-LM의 in-output sub-networks의 학습시킬 수 있는 파라미터를 제한하는 방법론을 보여줬으며 이는 classification-task에서 꽤나 이상적인 결과를 도출할 수 있었음.
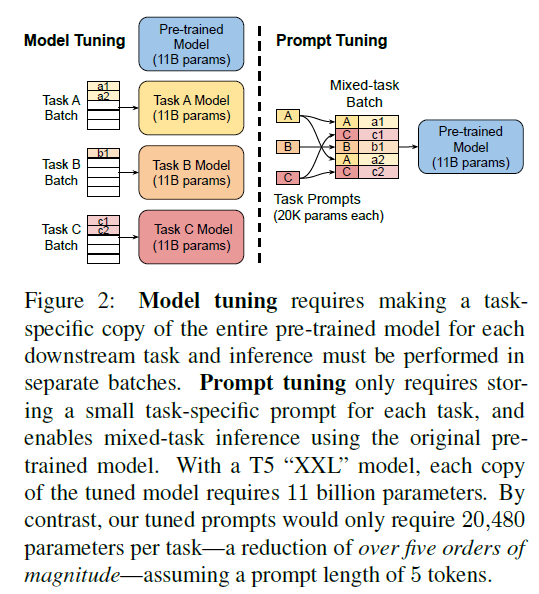
이번 연구에선, prompt tuning 제안. 사전훈련된 전체 모델을 동결하고 downstream-task당 추가로 K개의 조정 가능한 토큰만 input-text 앞에 붙일 수 있도록 허용함. 이 soft-prompt는 end-to-end 방식으로 학습되었고 완전히 labeled dataset으로부터 signal을 압축할 수 있음. 이러한 방법론을 통해 few-shot prompts의 성능을 향상시키고 model-tuning과의 gap을 줄일 수 있었음. 동시에 단일의 사전학습된 모델은 모든 downstream-task에서 다시사용될 수 있으며 연구진은 동결된 모델들의 효율적인 serving benefits을 재학습시켰음.
작업별 매개 변수와 일반적인 언어 이해에 필요한 ‘일반’ 매개 변수를 명시적으로 분리하면 다음과 같은 다양한 추가 이점이 있습니다.
해당 논문의 key point
- LLM분야에서의 model-tuning과 더불어 prompt-tuning의 경쟁력
- prompt design별로 성능 비교 / 모델 scale이 향상됨에 따라 성능 확인
- domain-shift problem에서 prompt-tuning이 model-tuning 능가
- prompt-ensembling의 제안과 이의 효율성
Prompt Tuning
Prompt-tuning은 prompt $\theta$로부터 파라미터화된 prompt $P$의 한계를 제거합니다. 대신 프롬프트에는 업데이트할 수 있는 전용 매개 변수인 $\theta_{P}$가 존재합니다. 프롬프트 디자인에는 고정된 임베딩 어휘에서 프롬프트 토큰을 선택하는 작업이 포함되지만, 프롬프트 튜닝은 특수 토큰으로 구성된 고정 프롬프트를 사용하는 것으로 생각할 수 있으며, 이러한 프롬프트 토큰의 임베딩만 업데이트할 수 있습니다.
Results
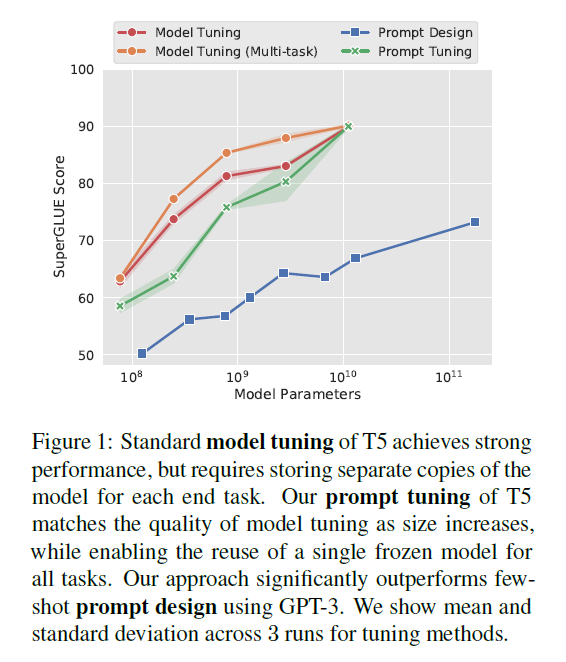
모델은 T5 계열 사용. SuperGLUE benchmarking, model-tuning의 경우 baseline과 multi-task로 분리하여 성능 측정. 실험결과는 FIgure1.
Ablation Study
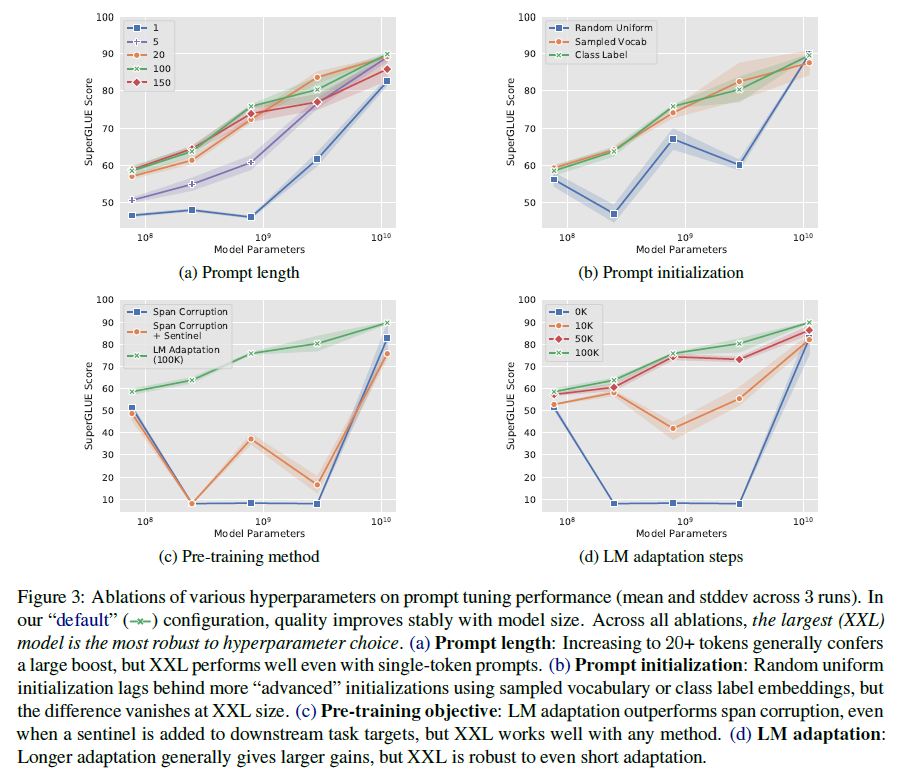
Prompt Length 모델 크기별로 prompt 길이를 다르게하여 학습하였음. length = {1, 5, 20, 100, 150} (Figure3-(a))
Prompt Initialization 샘플 vocab에서 Initialization할 때, T5의 Sentence-Piece vocab에서 가장 일반적인 5000개의 토큰으로 제한하였음. Class-label의 경우, 각 클래스의 문자열 representation에 대한 embeddings을 가져와 이를 사용하여 prompt의 토큰 중 하나를 초기화하였음. class-label이 multi-token일 때, 토큰임베딩을 평균화하였음. 프롬프트 길이가 길어지면 프롬프트 토큰을 모두 초기화하기 전에 클래스 레이블이 부족해지는 경우가 많습니다. 이 경우 프롬프트를 채우기 위해 샘플 어휘 전략을 사용하여 프롬프트를 채웁니다. (Figure3-(b))
Pre-training Objective
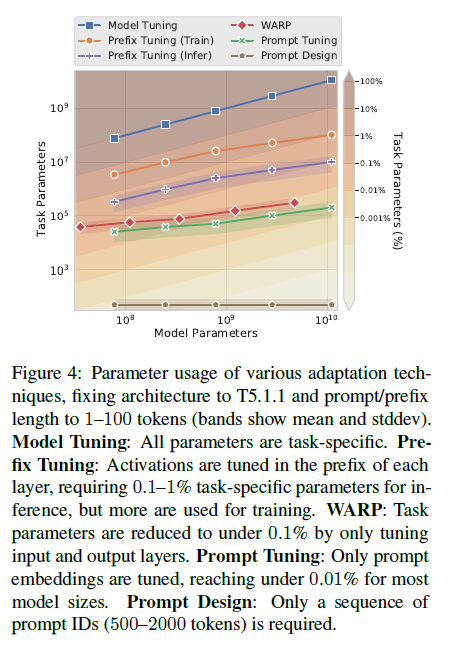
Resilience to Domain Shift
핵심 언어 모델 파라미터들을 고정시킴으롰꺼 prompt-tuning은 모델의 일반적인 언어 이해를 수정하는 것을 방지합니다. 대신에 prompt representation은 간접적으로 input의 representation을 조절합니다. 이는 특정한 언어신호나 비논리적인 상관관계를 기억함으로써 데이터에 과적합하는 능력을 줄여줍니다. 이러한 제한은 prompt-tuning이 도메인이 바뀌었을 때도 robustness를 향상시켜 줄 것입니다.
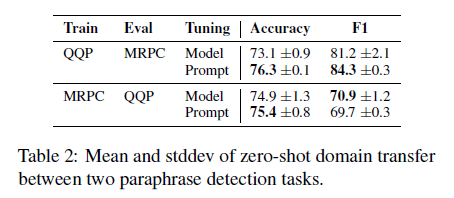
이에 연구진은 2가지 task(QA, paraphrase detection)에서 zero-shot domain transfer를 조사합니다. QA task: MRQA, SQuAD Paraphrase detection: GLUE, QQP, MRPC
Prompt Ensembling
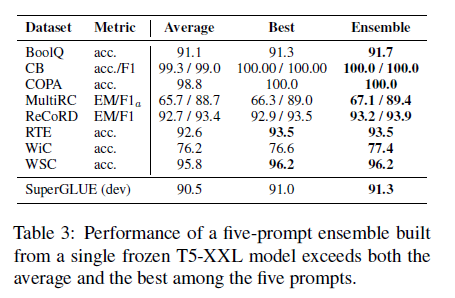
프롬프트 튜닝은 사전 훈련된 언어 모델의 다양한 적응을 앙상블로 구성하는 더 효율적인 방법을 제공합니다. $N$개의 prompt를 같은 task에서 학습함으로써, $N$개의 분리된 모델들을 만들 수 있습니다. 저장소 공간을 급격하게 줄여줄 뿐만 아니라 prompt-ensemble은 추론을 더 효과적으로 할 수 있게 만들어줍니다. 하나의 예제를 처리할 때, $N$개의 다른 모델의 포워드 패스를 계산하는 대신, 배치 크기가 $N$인 단일 포워드 패스를 실행하여 배치 전반에 예제를 복제하고 프롬프트를 다양화할 수 있습니다. 이러한 절약은 Figure2에서 다중 작업을 위해 본 절약과 유사합니다.
Interpretability
이상적으로 해석 가능한 프롬프트는 수행해야 할 작업을 명확하게 설명하는 자연어로 구성되어야 하며, 모델에게 어떤 결과나 행동을 명시적으로 요청하고, 프롬프트가 모델로부터 그러한 행동을 유발한 이유를 이해하기 쉽게 만들어야 합니다.
프롬프트 튜닝이 이산 토큰 공간이 아닌 연속 임베딩 공간에서 작동하기 때문에 프롬프트를 해석하는 것이 더 어려워집니다. 학습된 소프트 프롬프트의 해석 가능성을 테스트하기 위해, 정지 모델의 어휘에서 각 프롬프트 토큰의 가장 가까운 이웃을 계산합니다. 유사도 지표로 어휘 임베딩 벡터와 프롬프트 토큰 표현 사이의 코사인 거리를 사용합니다.
연구진이 관찰한바에 의하면, 주어진 학습된 프롬프트 토큰에 대해 상위 5개의 가장 가까운 이웃들은 밀접한 의미적 클러스터를 형성합니다. 예를들어 언어 그 자체로 비슷한 클러스터 {Technology / technology / Technologies / technological / technologies} 뿐만 아니라 다양하지만 그 의미가 매우 비슷한 클러스터 {entirely / completely / totally / altogether / 100%}. 이러한 클러스터의 특성은 프롬프트가 실제로 “단어와 유사한” 표현을 학습하고 있음을 시사합니다. 우리는 임베딩 공간에서 무작위로 추출한 벡터가 이러한 종류의 의미적 클러스터링을 보여주지 않는다는 것을 발견했습니다.
프롬프트를 “클래스레이블(classlabel)” 전략으로 초기화할 때, 학습 중에도 클래스 레이블이 지속되는 경우가 종종 있습니다. 구체적으로, 프롬프트 토큰을 특정 레이블로 초기화하면, 튜닝 후 학습된 토큰의 가장 가까운 이웃 중에 해당 레이블이 자주 포함됩니다. “랜덤 유니폼(Random Uniform)” 또는 “샘플링된 어휘(Sampled Vocab)” 방법으로 초기화할 때에도 프롬프트의 가장 가까운 이웃에서 클래스 레이블을 찾을 수 있지만, 여러 프롬프트 토큰의 이웃으로 나타나는 경향이 있습니다. 이것은 모델이 프롬프트에 예상되는 출력 클래스를 참조로 저장하는 것을 학습하고 있으며, 프롬프트를 출력 클래스에 초기화하면 이를 더 쉽고 중앙집중적으로 만드는 데 도움이 된다는 것을 시사합니다.
길이가 더 긴 프롬프트(예: 크기 100)를 조사할 때, 여러 프롬프트 토큰이 같은 가장 가까운 이웃을 갖는 경우가 종종 발견됩니다. 이는 프롬프트에 과잉 용량이 있거나 프롬프트 표현에 연속적 구조가 부족하여 모델이 특정 위치에 정보를 국한시키는 것이 어렵다는 것을 시사합니다.