K-BrowseComp - A Web Browsing Agent Benchmark Grounded in Korean Contexts [2026]
Introduction
Frontier 모델 평가의 무게중심이 instruction following·reasoning 같은 foundational 능력에서 tool calling·multi-turn을 아우르는 compositional·agentic 능력으로 옮겨가고 있음. 그러나 한국어 agentic 벤치마크는 사실상 부재한 상태로, 한국어 커뮤니티는 여전히 정적(static) 벤치마크에 머물러 있음.
연구진은 그 첫걸음으로 web browsing agent에 주목함. 이유는 두 가지:
- Browsing agent는 본질적으로 지역·문화적 지식에 의존함. 웹에서 region-specific 정보를 검색하는 게 핵심 기능이라, 한국어와 영어 중심 맥락 사이의 격차가 사용자에게 직접적인 영향을 미침 (AI sovereignty 관점).
- Browsing agent는 instruction following·tool calling·multi-turn interaction을 동시에 요구하는 compositional task라, 한국어 agentic 능력을 종합적으로 측정하는 testbed가 됨.
이렇게 제안된 K-BrowseComp은 총 400문제로 구성됨 — 원어민이 수작업으로 만들고 검증한 K-BrowseComp-Verified 300문제와, LLM으로 적대적으로 생성한 Synthetic 100문제. 핵심 결과를 미리 보면, GPT-5.5·DeepSeek-V4-Pro·GLM-5.1 같은 frontier 모델조차 Verified subset에서 30.00~45.67%에 그치고(BrowseComp 대비 큰 폭의 하락), 정부 ‘Proprietary AI Foundation Model(PAF)’ 사업으로 공개된 한국어 LLM들은 0.00~10.33%에 머묾.
각 질문은 시간이 지나도 변하지 않는(temporally stable) 단일 short answer를 가지며, 공개된 웹 증거로 뒷받침됨. 그리고 두 가지 reasoning format을 가짐: Parallel-branching(여러 독립 제약의 교집합으로 유일 답을 특정)과 Multi-hop(중간 결과를 이용해 다음 증거를 검색).
K-BrowseComp 구성
K-BrowseComp-Verified (300문제)
17명의 원어민 annotator가 다음 3원칙으로 문제를 작성함:
- 질문은 Korean context에 기반하고 공개된 textual web evidence로 뒷받침될 것.
- 직접 검색으로는 풀기 어렵지만, 답을 찾으면 검증은 쉬울 것 (browsing task 특유의 information asymmetry).
- multi-hop reasoning 또는 parallel constraint satisfaction을 요구하며, 최소 4개의 step 또는 constraint를 가질 것.
LLM으로 문제를 만드는 것은 금지했고, private·paid·downloaded·non-textual source에 의존하는 문제도 배제함. 답은 유일하고 시간에 안정적이어야 함. 작성된 모든 항목은 저자들이 수작업으로 검증해, gold answer·중간 entity·인용 출처가 공개 웹 증거에서 복구 가능한지 확인하고, 접근 불가·불충분·불일치 증거를 가진 항목은 재작성을 위해 반려함.
통계적으로 Verified는 160개 multi-hop(53.3%), 140개 parallel(46.7%)로 구성되며, 가장 큰 카테고리는 Entertainment/Media 109개(36.33%), 그다음이 Places/Regions 48개(16.00%)임.
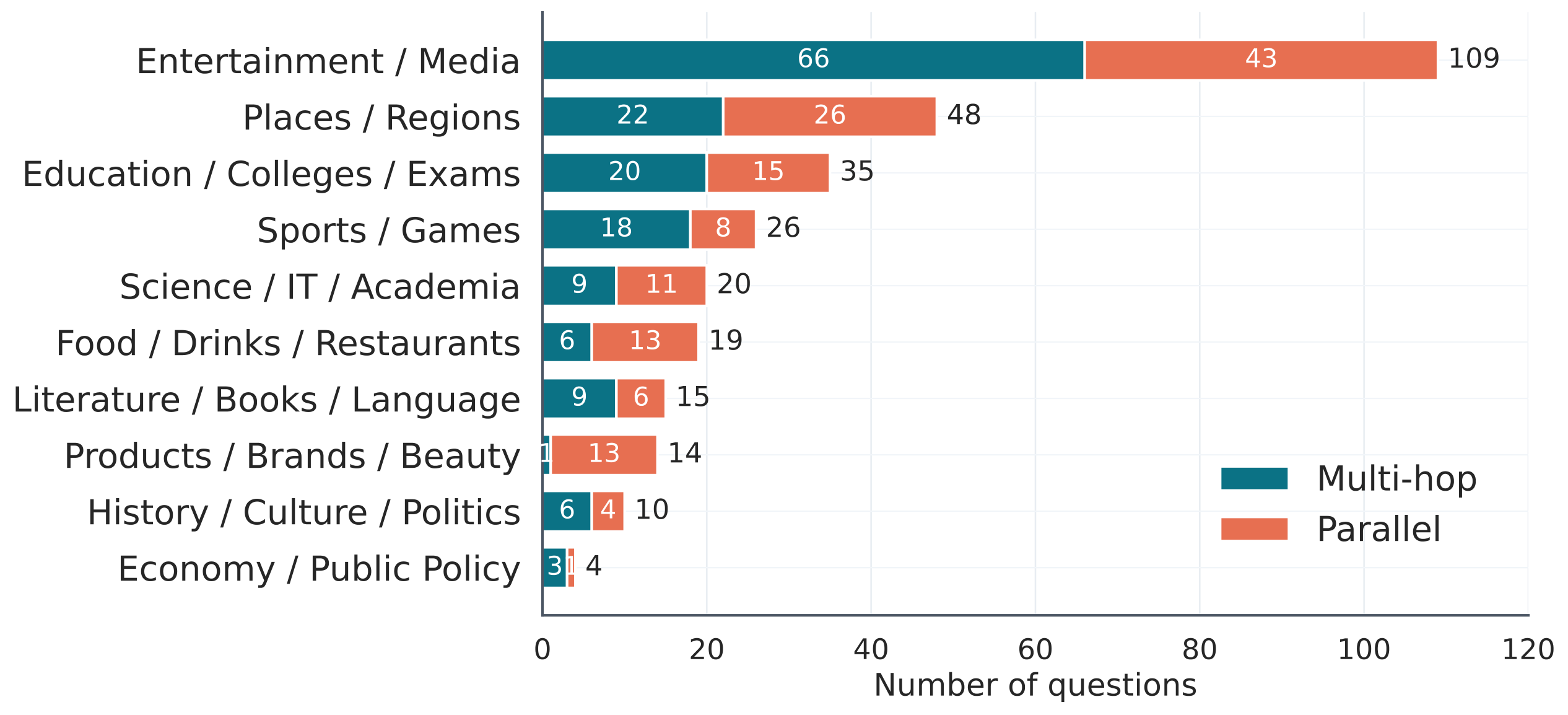
Failure-mode taxonomy (F0~F8)
각 문제는 검색 쿼리 생성 → 후보 증거 검색 → 결과 선택 → semi-structured 출처 해석 → 다단계/병렬 정보 결합 → 최종 답 도출의 긴 과정을 요구함. 연구진은 모델 오류를 수작업 분석해 trajectory-level failure taxonomy를 정의했는데, 이게 뒤의 Synthetic 생성의 핵심 재료가 됨.
| Mode | 정의 |
|---|---|
| F0 | Incomplete trajectory / malformed output — 불완전한 trajectory, 형식 오류, 유효한 최종 답 없음 |
| F1 | Ineffective initial search direction — 유용한 초기 검색 전략 실패 |
| F2 | Search-access structure failure — 어려운 페이지 구조 뒤의 증거 접근 실패 |
| F3 | Cross-source hopping failure — 약하게 연결된 출처·entity 맥락 간 증거 연결 실패 |
| F4 | Semi-structured parsing failure — 표·리스트·랭킹·DB·기관 페이지 오독 |
| F5 | Search-result selection failure — 관련 증거를 찾았으나 잘못된 출처·후보 선택 |
| F6 | Sparse entity normalization failure — 희귀 이름·별칭·표기 변형·옛 이름 해소 실패 |
| F7 | Constraint-tracking failure — 부분 후보는 찾았으나 모든 제약 만족 실패 |
| F8 | Intermediate reasoning failure — 날짜 연산·정렬·계산·비교·필터링 실패 |
Synthetic split (100문제) — 이 논문의 핵심 기여
이 논문의 기술적 핵심은 나머지 100문제를 LLM으로 구축하는 방법론에 있음. Browsing task의 정의적 특성인 information asymmetry(문제를 푸는 건 어렵지만, 증거 경로를 알면 답 검증은 비교적 쉬움)에서 출발해, 연구진은 구축 측면의 유사한 질문을 던짐 — “푸는 게 어렵다면, 만드는 것도 어려운가?”
웹 browsing LLM agent를 17명의 human annotator와 동일한 포맷의 proposer로 사용함. 단순 지시로는 frontier 모델이 풀어버리거나 ill-defined한 문제가 나왔지만, (i) 어려운 사람 작성 문제를 few-shot exemplar로 제공하거나 (ii) 분석에서 식별한 failure mode를 targeting하게 하면 품질·난이도가 크게 올라감.
생성 파이프라인: Verified의 gold source page를 seed로, F1~F8을 target(F0은 content-level 실패가 아니라 제외)함. 각 seed page를 Claude Code(claude-opus-4.7, maximum effort)에 주고, 페이지를 먼저 연 뒤 거꾸로(backwards) 한국어 질문을 구성하게 함 — 답·그 paraphrase, source URL·도메인, 가장 식별성 높은 entity 이름을 숨기고 지정된 failure mode를 겨냥. agent는 draft → test → revise를 4회 iteration 반복함.
3단계 순차 필터(하나라도 실패하면 수정으로 회귀):
- Searchability — 웹 쿼리를 던져 gold answer가 검색 결과에 이미 나오면 너무 쉬운 것으로 보고 재작성.
- Well-formedness — reference solver에게 전체 source page와 질문을 주고 답을 복구하게 해, 답이 페이지에서 유일하고 충실하게 추출 가능한지 확인.
- Adversarial difficulty — search-only solver(웹 검색만 허용, 페이지 직접 접근 불가)가 풀게 해, target 모델(gpt-5.4-mini, gemini-3-flash-preview)이 모두 실패(오답 또는 명시적 기권)할 때만 채택. 실패는 F1~F8 중 하나에 귀속되어야 함.
통계: 생성한 268개 후보 중 100개가 필터를 통과(37.3% yield). 채택 문제는 1~4회차에 각각 55·32·10·3개. failure mode 분포는 F4(59)·F7(21)·F2(14)·F8(13)·F3(13)·F6(8)·F5(6)·F1(1)로, semi-structured parsing(F4)과 constraint accumulation(F7)이 가장 자주 악용된 약점. 반려된 168개는 대부분 seed page가 이미 검색에 완전히 노출된 경우였음. Synthetic split은 reasoning format 균형(53.0% multi-hop / 47.0% parallel)은 유지하나, Entertainment/Media 비중이 36.3%→9.0%로 줄고 Science/IT/Academia가 6.7%→33.0%로 늘며, 평균 길이도 174.46→248.40자로 길어짐(두 split을 질문 텍스트만으로 분류 시 ROC AUC 0.8873).
실험
Setup
평가는 search_evals 프레임워크(Perplexity)의 deep-research agent로 수행하고, search backend는 Perplexity Search. 비교 가능성을 위해 각 agent에 질문당 10회 search call 예산을 부여(프레임워크 기본값). 각 모델은 Verified 300문제를 1회씩 평가하며, GPT-5.4-mini로 최종 답을 추출해 gold와 매칭(BrowseComp 방식). 단일 실행 정확도가 곧 pass@1.
baseline은 세 부류: closed(GPT-5.5, GPT-5.4-mini, Gemini-3.1-Flash-Lite), open-weight global(DeepSeek-V4-Pro, GLM-5.1, Qwen3.6-35B-A3B, Gemma-4-31B-it), Korean open-weight(K-EXAONE-236B-A23B, A.X-4.0, HyperCLOVAX-SEED-Think-32B, Kanana-2-30B-A3B-Thinking).
Main results
| Model | Access | Verified Acc. | Calib. Err. | Synthetic Acc. |
|---|---|---|---|---|
| GPT-5.5 | Closed | 45.67 | 31.86 | 26.00 |
| GPT-5.4-mini | Closed | 30.67 | 37.88 | 0.00† |
| GLM-5.1 | Open | 30.67 | 27.07 | 19.00 |
| DeepSeek-V4-Pro | Open | 30.00 | 17.72 | 22.00 |
| Gemma-4-31B-it | Open | 23.33 | 23.66 | 17.00 |
| Qwen3.6-35B-A3B | Open | 12.00 | 47.89 | 15.00 |
| Gemini-3.1-Flash-Lite | Closed | 11.33 | 56.55 | 11.00 |
| K-EXAONE-236B-A23B | Open | 10.33 | 24.09 | 13.00 |
| A.X-4.0 | Open | 5.33 | 47.89 | 1.00 |
| HCX-SEED-Think-32B | Open | 2.33 | 77.37 | 2.00 |
| Kanana-2-30B-A3B-Think | Open | 0.00 | – | 0.00 |
† GPT-5.4-mini의 Synthetic 0.00은 이 모델이 적대적 필터링에 쓰였기 때문(별도 취급).
GPT-5.5가 45.67%로 최고지만, 이는 원 BrowseComp에서의 84.4%(DeepSeek-V4-Pro는 83.4% → 여기선 30.00%)에 비하면 큰 폭의 하락. 즉 영어 browsing은 풀어도 한국어 맥락의 browsing은 못 푼다는 의미. 한국 open 모델들은 K-EXAONE 10.33%, A.X-4.0 5.33%, HCX-SEED 2.33%로 글로벌 모델과 뚜렷한 격차를 보임. calibration error(confidence 5-bin 기준 mean confidence와 실제 정확도의 가중 평균 격차)는 HCX-SEED가 77.37%로 특히 높아, 정확도뿐 아니라 confidence 보정에서도 취약함을 드러냄.
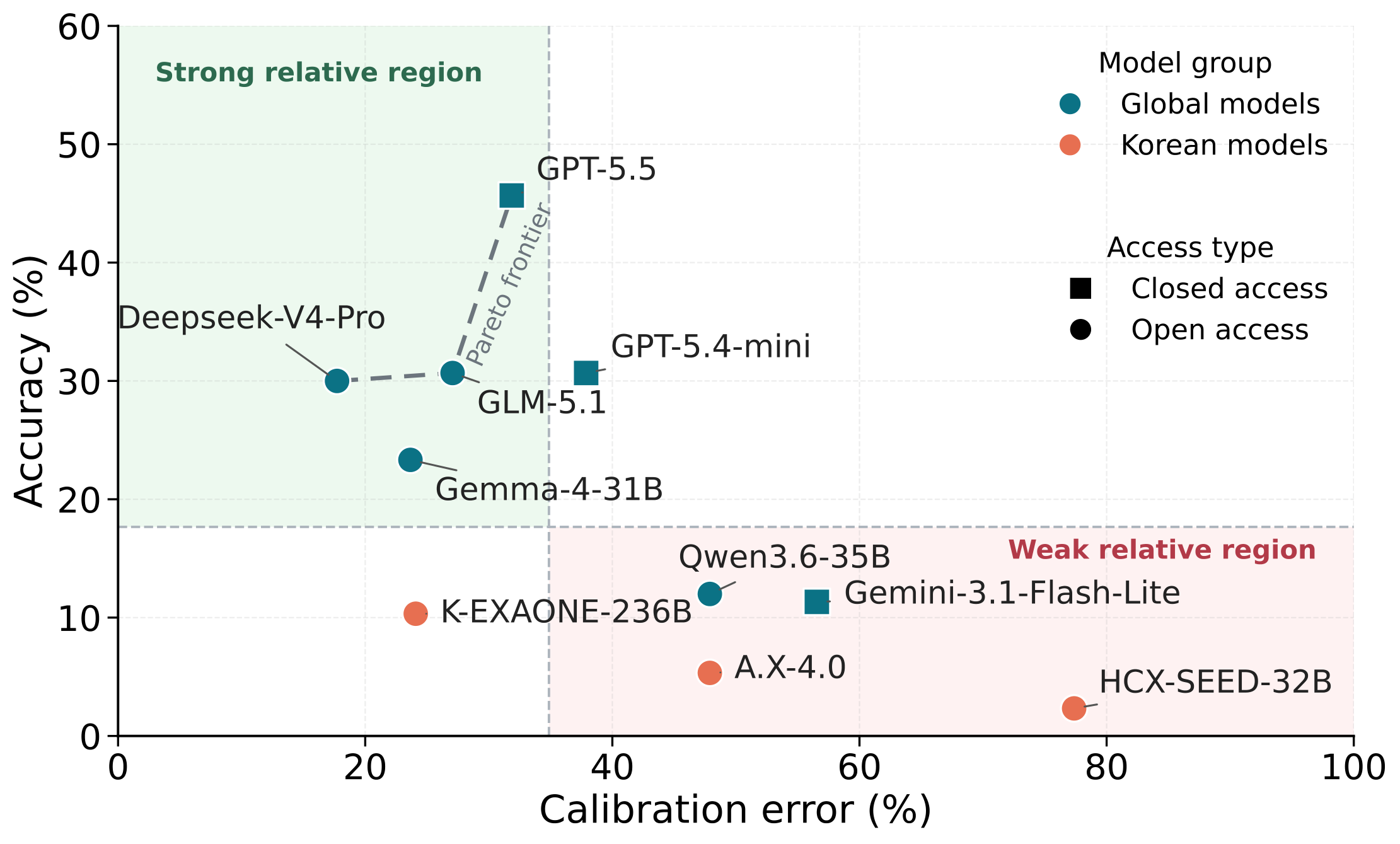
Synthetic 결과
Synthetic split에서는 모든 모델이 0.00~26.00%로, 어느 모델도 30%를 넘지 못함. Verified에서 강했던 GPT-5.5·DeepSeek-V4-Pro·GLM-5.1조차 26.00·22.00·19.00%로 떨어짐. 즉 failure-mode를 겨냥한 적대적 생성 방법이 실제로 어려운 진단용 split을 만들어냈음을 보여줌(필터링 자체가 구축 과정의 일부라 Verified 점수와 합산하지 않고 별도 stress test로 보고).
분석: 실패는 “검색 이후”에 발생한다
Trajectory-level failure patterns
많은 오류가 이미 부분적으로 관련된 증거를 찾은 뒤에 발생함 — step-level 오류가 여러 step에 걸쳐 누적되는 패턴.
- Candidate capture (F5+F7): 상위 제약을 모두 검증하기 전에 그럴듯한 entity에 조기 confirm. 이후 검색은 선택한 후보의 증거 공간 안에서만 이뤄지는 확인용이 됨.
- Unmerged evidence branches (F7): 여러 제약을 따로 검색하지만, 각 쿼리가 별도 branch를 만들 뿐 공유 후보 집합에 대한 filter로 합쳐지지 않음. K-pop 그룹 병렬 제약 문제에서 gold는 Ladies’ Code이나 모델은 제약을 위반한 Winner를 반환.
- Misbound evidence chains (F3): 중간 결과를 잘못된 role에 binding. entity type이 step마다 바뀌는 질문에서, role(지역·기관·노래·가사)을 보존하지 못하면 visibility 높은 엉뚱한 entity가 정답 자리를 차지함.

종합하면 retrieval이 성공한 뒤에는 F0·F3·F5·F7이 지배적 실패 모드. K-BrowseComp에서의 진전은 candidate·constraint·role binding·final-answer state를 여러 turn에 걸쳐 유지하는 메커니즘에 달려 있음.
Search effort과 failure persistence
낮은 성능이 단순히 search 예산 부족 때문인지 확인하기 위해, 정답·오답 trial의 search call 사용량을 비교함(Table 3). 대부분 모델에서 오답 trial이 정답 trial보다 search call을 더 많이 쓰며 10회 예산에 근접함 — 예: GPT-5.5(7.08 vs 9.30), DeepSeek-V4-Pro(7.47 vs 9.80), Gemma-4-31B-it(5.20 vs 8.10). 즉 오류는 retrieval 부족이 아니라, 증거를 찾고도 제약을 병합하지 못하거나 entity role을 보존하지 못하거나 답을 commit하기 전에 후보를 검증하지 못한 데서 옴(예외적으로 A.X-4.0은 양쪽 모두 search가 적어 shallow search·조기 종료가 의심됨).
정리
K-BrowseComp은 (1) 한국어 맥락에 기반한 첫 web browsing agent 벤치마크를 17명 원어민의 수작업으로 구축하고, (2) browsing의 information asymmetry를 역이용해 failure-mode targeting + hard few-shot으로 적대적 문제를 합성하는 방법론을 제시함. frontier 모델도 45.67%에 그치고 한국어 모델은 10% 안팎에 머무는 큰 난이도와 격차를 드러냈으며, 무엇보다 실패의 본질이 검색 능력이 아니라 multi-turn 상태 관리(candidate·constraint·role·finalization)에 있음을 trajectory 분석으로 짚어낸 점이 인상적임. data·code는 공개됨.