VERA - Vector Based Random Matrix Adaptation [2024]
Introduction
대언어모델시대에 효율적인 학습방법, GPU 메모리요건 등에 대해 언급하고 있습니다.
GPT-4와 같은 SOTA모델들이 급증하고 있는 상황에서 LoRA와 같은 파인튜닝 기법은 여전히 효과적이고 메모리를 줄일 수 있는 방법으로 소개되고 있습니다. GPT-3의 경우, query나 value 레이어에 Rank 16의 LoRA를 적용하면 최소 288MB의 메모리를 요구하나, single-precision으로 저장할 경우, 사용자당 약 배만 개의 미세조정된 가중치가 있을때 275TB에 달합니다.
개인화된 어시스턴트, edge devices, 이와 같은 유사한 application의 확산속에서 모델의 효율적인 접근 방식은 다른 무엇보다 중요합니다. 이에 연구진은 novel한 효율적인 접근방법에 대해 언급하고자 합니다. 이전 연구 (Aghajanyan et al., 2021)에서 사전학습된 모델 features의 본질적인 낮은 dimensionality에 대해 강조하였습니다. 이 연구에서 LoRA보다 더 적은 학습가능한 파라미터를 통해 학습하는 방법을 발표하였고 이는 해당 분야에 있어 개선의 여지가 있음을 시사합니다.
이와 동시에, 최근 연구에서는 random weights와 projection을 사용하는 모델의 놀라운 효과를 보여주었습니다 (Peng et al., 2021; Ramanujan et al., 2020; Lu et al., 2022; Schrimpf et al., 2021; Frankle et al., 2021). 본 연구진이 제안한 solution은 VeRA로 이러한 모델들의 베이스에 근간하며 파인튜닝하는 동안 가중치 matrices를 재-파라미터화함으로써 학습 파라미터를 최소화하는 방법론을 소개합니다. 특히 연구진은 scaling vectors를 차용하여 고정된 무작위 행렬값들의 pair를 공유된 layer 사이에 적용하는 방법을 사용했습니다. 이 접근법을 사용하면 더 많은 버전의 모델을 단일 GPU의 제한된 메모리에 저장할 수 있습니다.
Summary
- 연구진은 추가적인 inference time cost 없는 novel finetuning 방법론을 소개. 본 방법론은 LoRA보다 파라미터를 더 적게 사용.
- VeRA를 LoRA 또는 다른 파라미터 효율적인 적용 방법론과 비교하였으며 언어모델은 GLUE, E2E, instruction-following / 비젼모델은 Image Classification task에 benchmarking 하였음.
- VeRA의 각각의 구성요소에 대한 performance를 살펴보기위한 Ablation study 진행
Related Work
Low-Rank Adaptation (LoRA)
LoRA는 LLM의 파인튜닝에 대한 문제점을 해결할 수 있는 혁신적인 solution이었습니다. LoRA는 파인튜닝하는동안 낮은차원의 matrices를 근사치의 weight와 바꾸는 방법론을 사용하였습니다. 이를 통해 학습되는데 필요한 파라미터의 숫자는 효율적으로 줄일 수 있었죠. 이러한 이점들 사이에서 LoRA는 파인튜닝에 필요한 하드웨어적 재원(GPU)을 상당수 줄일 수 있었습니다. 이는 또한 양자화 모델 가중치와 함께 동작할 수 있으며 더 많은 메모리를 줄일 수 있습니다. 게다가 LoRA 모듈은 쉽게 바꿀 수 있으며 효율적이고 더 적은 자원으로 task-switching도 가능합니다. 더 중요한 것은 다른 목적으로 파인튜닝된 어댑터를 적용할 경우 (Houlsby et al., 2019; Lin et al., 2020; Pfeiffer et al., 2021; R¨uckl´e et al., 2021),, 학습가능한 행렬들이 고정된 가중치와 함께 통합되기에 LoRA는 추가적인 inference time이 소요되지 않습니다.
이러한 연구에 힘입어, AdaLoRA (Zhang et al., 2023b)는 LoRA 방법론을 확장시켜 파인튜닝할떄 low-rank matrices을 위한 dynamic rank adjustment 방법론을 만들었습니다. 핵심 아이디어는 중요도 지표를 기반으로 행렬의 중요도가 낮은 요소들을 선택적으로 가지치기하여 파라미터 예산을 최적으로 분배하는 것입니다.
Parameter Efficiency in Existing Methods
LoRA와 같은 method를 통해 파인튜닝 성능에 있어서 대단한 향상이 있었음에도 해당 필드에서 연구는 지속적으로 이루어졌습니다. Aghajanyan et al. (2021)에서 intrinsic dimension은 일반적으로 사용하는 방법론보다 더 적은 양을 필요로 하였습니다. 예를 들어, RoBERTa 베이스 모델의 $d_{90}$은 896로 보고되었지만, LoRA 논문의 저자들은 이 모델에 대해 0.3M의 훈련 가능한 파라미터를 사용했다고 보고하여 파라미터 수를 더 줄일 수 있음을 시사합니다.
AdaLoRA는 더 중요한 레이어들에 동적으로 파라미터들을 할당함으로써 이 방향으로 나아가는 조치를 취하지만, 본 연구진은 파라미터를 감소시키는 또다른 접근법을 받아들였습니다.
Random Models and Projections
모델 효율성을 위한 random matrices & projections 사용에 대한 방법론은 몇몇의 연구에서도 지지 받아왔습니다.
많은 연구들을 종합하여 볼 때, 파인튜닝 방법에서 고정된 random matrices을 활용하는 것은 이 논문에서 취한 접근법에 대한 이론적, 실증적 기반을 제공하며 설득력 있는 사례를 만들어냅니다.
Method
VeRA의 핵심은 reparameterization of the low-rank matrices입니다. 특히 연구진은 무작위로 초기화된 matrices 한 쌍을 고정하고, Figure 1에서 볼 수 있듯이 레이어별 adaption을 허용하는 훈련 가능한 scaling vectors를 도입하였습니다.
Method Formulation
기존 LoRA Equation
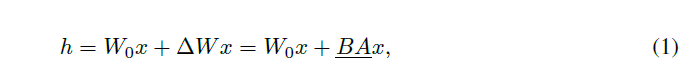
EQ1에서 gradient descent를 통해 파라미터가 업데이트 되기에 밑줄 그은 부분입니다. 이 근사치는 오직 새로운 low-rank matrice $A$, $B$가 최적화하는 동안 모델이 기존의 weight $W_0$를 유지시켜주게 만들어줍니다. 이 행렬들의 사이즈는 rank가 줄어들기에 기존 matrix의 사이즈보다 더 작습니다. 대조적으로 VeRA의 method는 아래와 같이 표현됩니다.
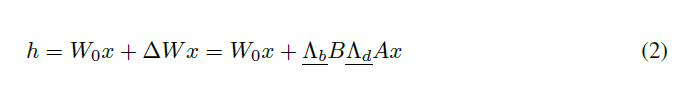
$B$와 $A$는 scaling vector $b$, $d$가 학습할 수 있을때 고정되며, 랜덤하며, layer들을 가로지르고, 공식적으론 대각선행렬로 표시됩니다. 이 접근법은 최소한의 학습가능한 파라미터와 함께 layer-wise adaptation에서 효율적으로 scale할 수 있으며 $A$와 $B$의 rows / columns들을 disable하게 만들어줍니다. $B \in \mathbb{R^{m\times r}}$와 $A \in \mathbb{R^{r\times n}}$는 low-rank될 필요는 없습니다. 그 이유는 그들이 상태를 유지할 수 있으며 그 값들을 저장할 필요 없기 때문입니다. 대신에 변수 $r$은 $d \in \mathbb{R^{1\times r}}$를 통해 학습가능한 파라미터 개수에 의해 선형적 상승을 초래합니다.
Parameter Count
| LoRA 학습 가능한 파라미터 개수: $ | \Theta | = 2 \times L_{tuned} \times d_{model} \times r$ |
| VeRA 학습 가능한 파라미터 개수: $ | \Theta | = L_{tuned} \times (d_{model} + r)$ |
Rank가 가장 낮을때 ($r = 1$), VeRA의 학습가능한 파라미터개의 개수는 LoRA의 절반입니다. 게다가 rank값이 상승할때, VeRA의 파라미터 수는 $L_{tuned}$만큼 증가하며 이는 LoRA의 $2L_{tuned}d_{model}$보다 상당히 절약적입니다.
VeRA의 가장 큰 이점은 학습된 가중치 조정을 저장하기위한 memory footprint를 최소화하는 것입니다. RNG(random number generator) seed로부터 무작위 고정행렬들이 재-생성되기에, 메모리에 굳이 저장될 필요가 없습니다. 이렇게 하면 메모리 요구량이 크게 줄어들어 이제 훈련된 $b$와 $d$ 벡터 및 단일 RNG 시드에 필요한 바이트 수로 제한됩니다.
Initialization Strategies
- Shared Matrices: frozen low-rank matrices $A$, $B$에 Kaiming Initialization 적용. 행렬 dimension기반 값들을 조정함으로써, A와 B의 행렬 곱셈이 모든 랭크에 대해 일관된 분산을 유지하도록 보장하여 각 랭크마다 학습률을 미세 조정할 필요성을 제거합니다.
- Scaling Vectors: LoRA에서의 행렬 $B$의 initialization과 동일하게 Scaling vector $b$는 최초 0값으로 초기화해주며 이를 통해 첫번째 forward pass하는 동안 가중치 행렬은 영향을 받지 않습니다. Scaling Vector $d$는 모든 요소에 걸쳐 단일 비영(非零) 값으로 초기화되며, 이를 통해 향상된 성능을 위해 조정할 수 있는 새로운 하이퍼파라미터를 도입합니다.
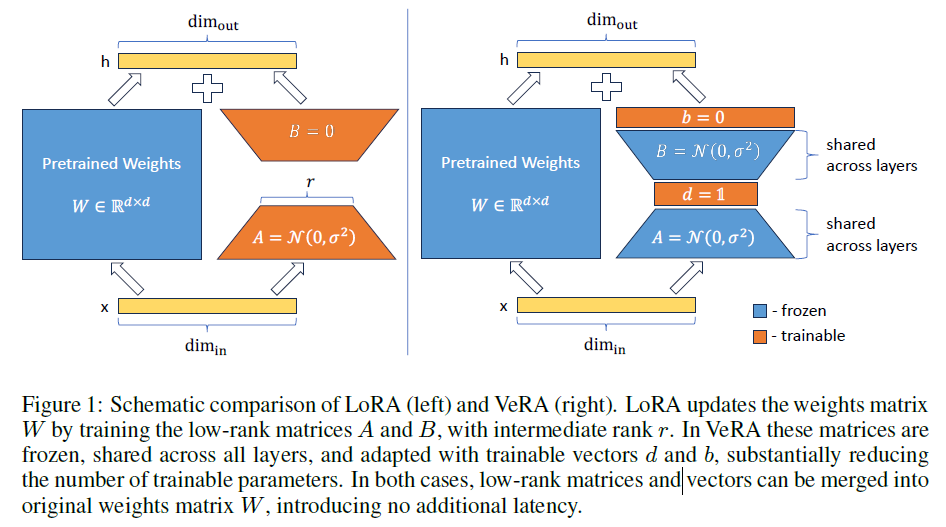
구체적으로, low-rank 행렬은 정규분포를 사용하여 초기화되고, $d$ vector는 1로 초기화됩니다.
Experiments
LoRA와 비교, GLUE / E2E, Llama model (IT), Vision Transformers (Image CLS)
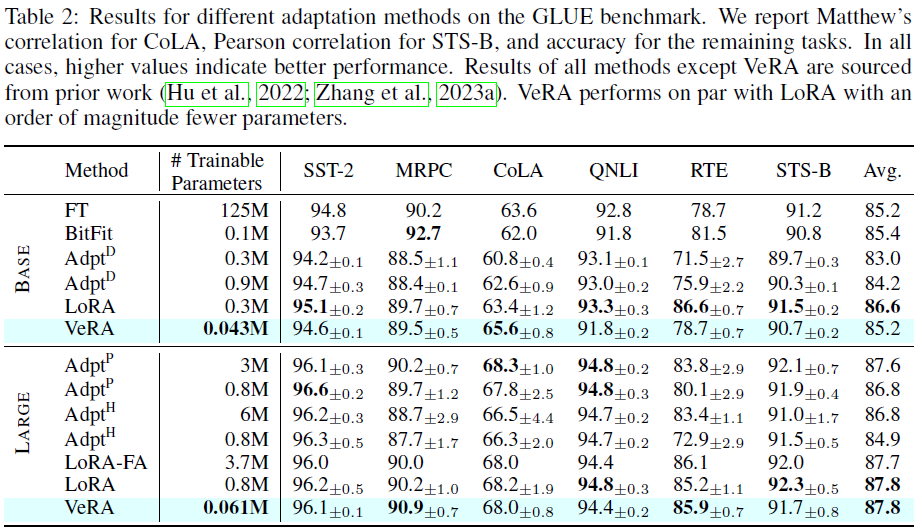
GLUE Benchmark
- base model: $RoBERTa_{base}$ and $RoBERTa_{large}$
- r(Rank): base 모델은 1024 / large 모델은 256
- target modules: query attn, key attn, cls_head
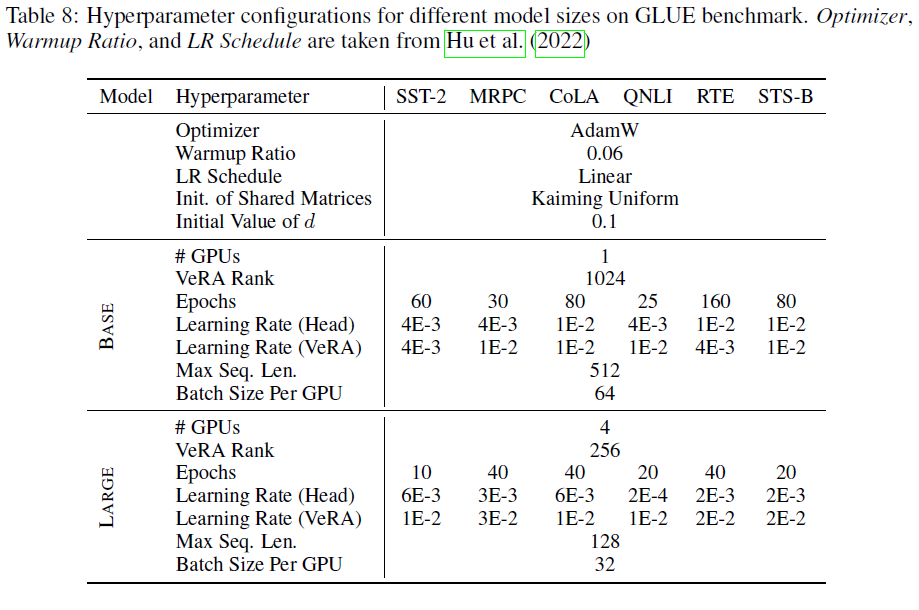
E2E Benchmark
- model: GPT-2 medium / large
- 모든 환경셋팅은 LoRA와 동일하나 r(Rank)와 LR값만 바꿔서 실험 진행
IT
- model: Llama / Llama2, 7B / 13B respectively
- trainable parameters (in VeRA): 1.6M & 2.4M
- trainable parameters (in LoRA): 159.9M & 250.3M ($r = 64$)
- target moduels: “all-linear”
- use quantization techniques
- single GPU
- dataset: Alpaca (clean version) 51k FLAN
- benchmark: MT-Bench
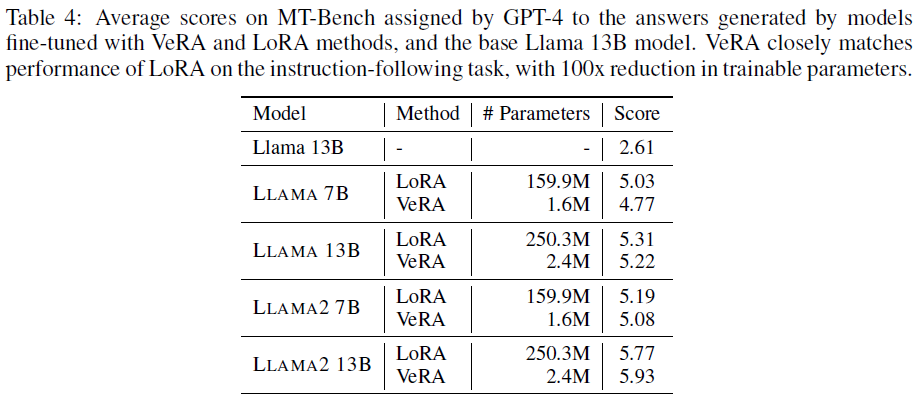
100배 더 적은 파라미터로 거의 동일하거나 뛰어난 모델을 만들 수 있었습니다.
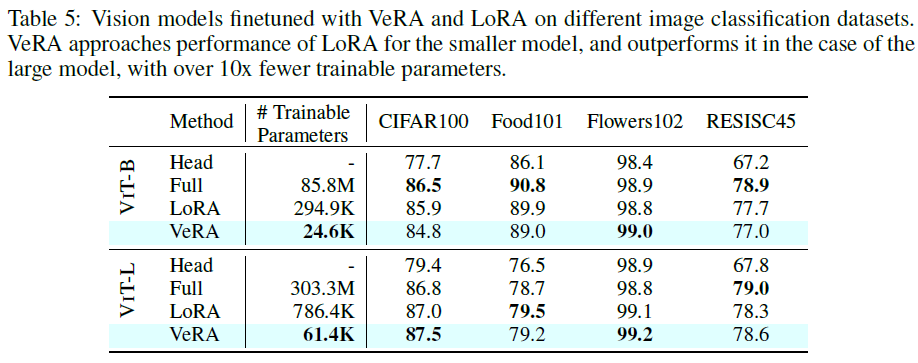
Image Classification
- model: ViT (ImageNet-21k)
- dataset: CIFAR100, Food101, Flowers102, RESISC45
- target modules: query / value layer
- baseline
- full finetuning
- only cls head
- r(Rank): 8(in LoRA), 256(in VeRA)
- epochs: 10
Scaling the number of trainable parameters
Trainable parameter 수와 학습 성능은 trade-off 관계이기에 trainable parameter 수를 scaling하여 실험 진행. $r = {1, 4, 16, 64, 256, 1024}$ in VeRA / $r = {1, 2, 4, 8, 16, 32, 64}$ in LoRA
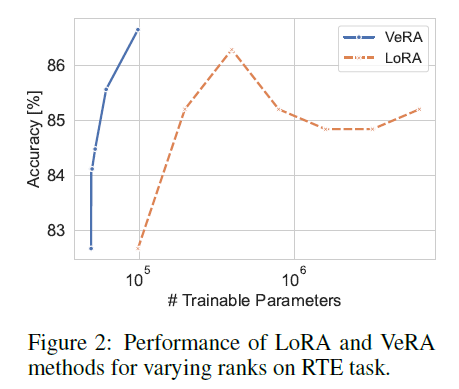
Figure2에 나와있듯이, VeRA가 LoRA에 비해 상당히 더 파라미터 효율적이라고 할 수 있습니다. 특히, 높은 rank를 사용한 VeRA가 LoRA와 같은 파라미터 수를 가질때, LoRA에 비해 4 accuracy percentage point를 앞섰습니다.
Ablation study
VeRA의 Individual Components에 대한 영향을 확인하기 위해 Ablation study를 진행하였습니다. 모델은 $RoBERTa_{large}$를 사용하였으며 MRPC, RTE task에서 실험을 진행하였습니다. 이전 실험의 하이퍼파라미터를 그대로 사용하였으며 테스트 진행시에만 환경을 조금 다르게 수정하였습니다.

Single Scaling Vector 첫번째로 Scaling vector $b$와 $d$의 필요성에 대해 조사하였습니다. 2개의 ablation setup을 만들었습니다. $d$를 제외($b$만 사용)하는 경우와 또다른 하나는 $b$($d$만 사용)를 생략하는 경우입니다. Only $d$의 setup의 경우 0값으로 초기화 해주었습니다. Only $d$의 setup의 경우가 조금 더 좋게 성능이 나왔습니다. $d$는 두 low-rank matrices의 행을 조절하여 최종적으로 구성된 행렬의 더 넓은 측면에 영향을 미칩니다. 대조적으로 $b$는 오직 low-rank matrices의 product의 결과값인 마지막 행렬의 행만 조절합니다.
Initialization of Shared Matrices Kaiming normal, Kaiming uniform, uniform initialization 전략을 사용하였고 Kaiming initialization을 사용앴을때 가장 성능이 좋았습니다.
Initialization of Scaling Vector 연구진은 $d$ vector를 통해 initialization의 성능을 더 알아보기 위해 실험을 진행하였습니다. $d_{init}$ 값을 1.0 $10^{-1}$, $10^{-7}$로 조정하여 실험하였습니다. 그 결과 $d_{init}$값의 조정이 모델의 성능향상에 지대한 영향을 미친다는 점을 밝혀냈습니다.
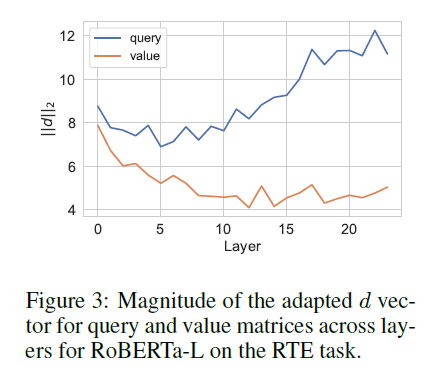
Magnitude of Adaptation 위 figure3는 $d$ vector의 magnitude scaling 변화에 따른 RTE task에서의 파인튜닝 성능 결과값이 나타나있습니다. low-rank 고정행렬들은 각각의 레이어에 같은 형태로 남아있기 때문에 layer들을 가로지르는 $d$ vector의 길이에 대해 직접적으로 비교하였습니다. 전반적으로 value 행렬에 비해 query 행렬에서 가장 큰 적응이 일어난다는 것을 발견했으며 이는 모델에 fine-tuning할 필요가 더 크거나 더 쉽게 이루어질 수 있음을 나타냅니다. 게다가 이런 비슷한 효율적인 적용 방법론들이 다른 연구(Zhang et al., 2023b; Liu et al., 2021)에 의해 이루어졌으며 연구진은 초기 레이어에 비해 후반 레이어에서 더 높은 adaptation을 발견할 수 있었습니다.
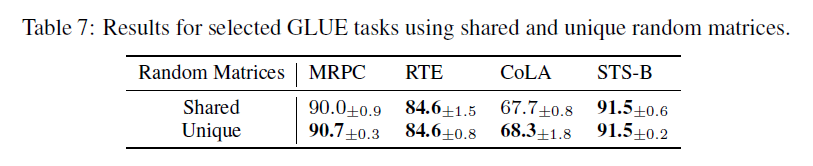
Sharing Random Matrices 공유하는 무작위행렬의 영향을 알아보기 위해 RTE, MRPC, CoLA, STS-B task를 수행하였습니다. 연구진은 모든 적응된 레이어에서 공유되는 무작위 행렬을 사용하는 설정과 독자적으로 생성된 행렬을 사용하는 설정, 두 가지를 평가합니다. Table7에 나왔듯이, RTE와 STS-B task의 경우 성능이 거의 비슷했으나 MRPC와 CoLA task의 경우 성능이 조금 상승했습니다.
Appendix
Impace of training time and memory usage
Llama 7B모델에서 학습 효율성을 측정해보기 위해 VeRA 방법과 LoRA방법론을 비교하였습니다 ($r = 64$).
VeRA는 forward pass에서 추가적인 벡터 곱셈을 포함하여 LoRA보다 더 많은 작업을 포함하지만, 훈련 시간에서 1.8%의 소폭 증가에 그친다는 것을 발견했습니다. GPU 메모리의 경우, VeRA를 사용하면 공유되는 무작위 행렬에 대한 옵티마이저 상태와 기울기를 저장할 필요가 없기 때문에 메모리 사용량이 7.4% 감소함을 관찰했습니다.

IT with Vicuna eval

