Ziya2 - Data-centric Learning is All LLMs Need [2023]
Introduction
- 최근 LLM 연구가 매우 활발하고 이루어지고 있으나 다음과 같은 중대한 문제점이 존재한다.
- 첫째, high cost of pre-training models from scratch.
- 둘째, open-source LLMs often do not come with open-source data.
- 셋째, many studies on LLMs prioritize increasing model size.
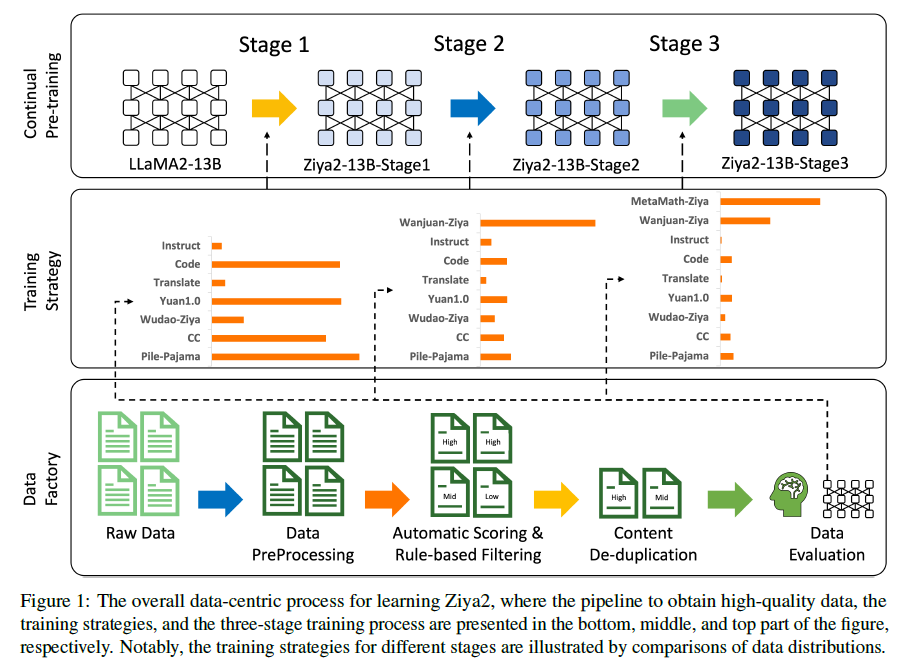
- 이에 따라 이번 연구에선 continual pre-training의 technique과 understanding the intricate relationship between data and model performance에 집중해보고자한다. 연구진은 모델의 필수적인 구조나 사이즈를 유지시키되 높은 품질의 사전학습 데이터를 통해 LLM의 성능을 강화해보고자 한다. 따라서 LLAMA2-13B을 사용한 Ziya2 모델을 backbone 모델로 사용하고 영어와 중국어로된 약 700B 토큰을 사용하여 pre-training을 진행하였다. 특히 학습 process를 3개의 stage를 거쳐 일반적이고 domain-specific한 corpora를 만들어 Ziya2 모델의 다중언어 생성 capabilities를 만들어줬음.
- 첫 번째 stage는 중국어와 영어로 된 Ziya2의 매우 방대한 품질 높은 데이터를 학습.
- 두 번째 stage에선 LLM을 최적화하기 위한 supervised-data를 사용.
- 세 번째 stage에선 Ziya2의 수학데이터를 학습하는데 집중.
-
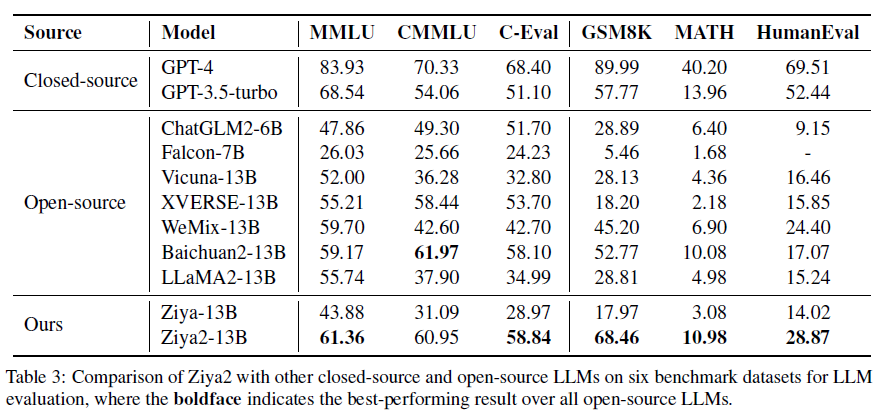
Ziya2의 평가 데이터셋은 수학적이거나 프로그래밍 능력을 테스트할 뿐만 아니라 다중 학문으로 이루어진 데이터셋을 포함한 benchmarking을 진행하였음.
- LLAMA2-13B과 비교한 결과는 다음과 같음
- 10% Increasing on MMLU
- 61% Increasing on CMMLU
- 68% Increasing on C-Eval
- 138% Increasing on GSM8K
- 120% Increasing on MATH
- 89% Increasing on HumanEval
- Ziya2는 여러 학문의 분야에 걸친 데이터셋에서 대단한 성능 향상을 이루어 냈음. 특히 오픈소스 진영에서의 mathematics나 programming skills과 비교해서 대단한 결과를 이루어냈음. 특히, Ziya2의 성능은 GPT-3.5-turbo를 중국어 task에서 능가하였음. 높은 품질의 데이터와 적절한 사전학습은 LLM의 대단한 모델 사이즈의 변화없이 성능향상에 대단한 영향을 미치는 것을 밝혀냈다.
Approach
The Data Factory
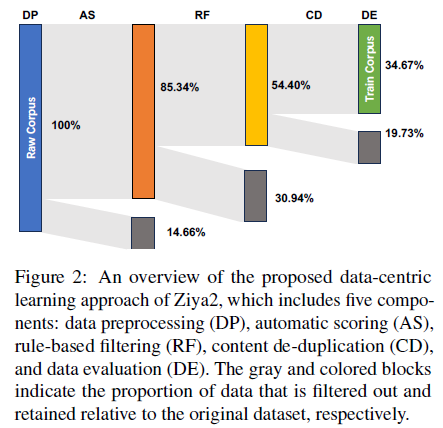
- 데이터는 LLM의 중추적인 초석 역할을 합니다. 데이터의 양과 품질은 모델의 성능에 직접적인 영향을 미칩니다. figure2에 나타난대로 data preprocessing, automatic scoring, rule-based filtering, content de-duplication, data evaluation을 포함한 다수의 공정을 통해 용이하게 만들었습니다. 이러한 절차는 지속적인 사전학습, 데이터 샘플링과 확장을 통해 필요조건을 충족시켰습니다.
-
Data Preprocessing (DP) : 첫째로 corpus의 언어가 중국어인지 영어인지 감지하는 과정. 언어를 감지한 후, corpus의 인코딩을 통해 표준화하며 모든 중국어 텍스트를 단순화 시킵니다. 그 후, non-visible control 문자, special symbol, emojis, punctuation marks처럼 사용할 수 없는 토큰들을 제거합니다.
-
Automatic Scoring (AS) : 위에서 나온 결과를 통해 언어모델로 automatic quality control을 수행하여 scoring 값을 도출해냅니다. 이 작업을 통해 중국어와 영어 wikipedia로 학습된 KenLM을 사용하였고 input data에 대한 평가를 PPL로 산출하였습니다. 그 뒤, 낮은 점수부터 높은 점수까지 줄 세운 후 top 30%의 데이터는 high quality, 30%~60% 데이터는 medium quality로 정의합니다.
-
Rule-based Filtering (RF) : LLM은 인터넷에서 수집된 어떤 유해한 정보를 기억하기 쉽기 때문에 NFSW, 폭력적, 정치적, 광고 등에 대한 유해한 데이터를 제거하는 과정을 생성하였습니다. 따라서 연구진은 세 가지 세분화된 수준에서 30개 이상의 필터링 규칙을 설계하였습니다 (document, paragraph, sentence). document레벨의 rule은 주로 컨텐츠 길이와 형식을 제한합니다. 반면에 paragraph와 sentence레벨의 rule은 컨텐츠의 유해성에 대해 집중합니다. 더불어서 manual evaluation을 통해 원본 텍스트의 랜덤 샘플링을 수행하였습니다. 그런 다음 규칙 반복은 피드백을 받아 추후 필터링 프로세스의 정확성을 보장합니다.
-
Content De-duplication (CD) : 이전 연구에서 밝혀진 것과 같이 반복적인 데이터는 학습의 효율성과 성능을 저해합니다. 이에 연구진은 Bloomfilter과 Simhash를 사용하여 다음과 같은 스텝을 통해 텍스트 데이터의 중복되는 항목을 제거하였습니다. 첫째, Common Crawl과 다른 오픈소스 데이터셋들을 포함시켰습니다. 그 후 Bloomfilter를 사용하여 중복되는 URL들을 제거하였습니다. 둘쨰, 많은 웹페이지의 컨텐츠는 대개 비슷한 정보를 공유하는데 가장 큰 차이점은 punctutation marks나 이모지같은 특수한 문자열입니다. 따라서 이러한 페이지에서 정밀한 중복 제거 작업을 수행하였습니다. 세번째, SimHash를 사용하여 남아있는 데이터에서 textual content에 대한 중복을 제거하였습니다. 비록 이러한 공정들로 인해 품질 좋은 데이터가 뽑히지 않았을지라도 연구진의 자체 매뉴얼 샘플링 평가는 더 높은 효율성을 위한 오류를 받아들이는 과정임을 암시합니다. 게다가 연구진의 데이터 공정에서 새롭게 수집되는 데이터를 위한 효율적인 중복제거 작업을 용이하게 하기위해 caching과 bucketing 작업을 사용하였습니다.
-
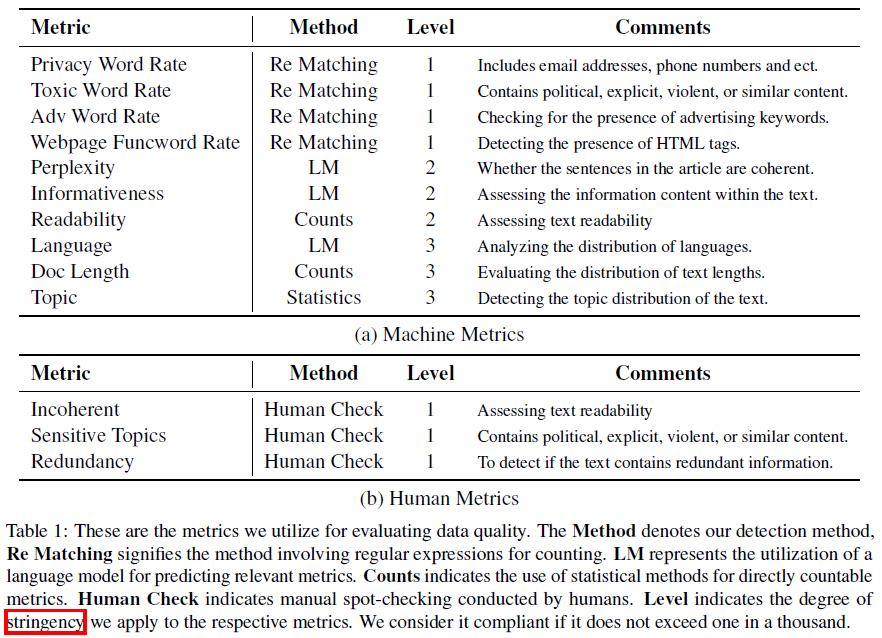
Data Evaluation (DE) : 위 작업 이후 연구진은 데이터 품질 평가 작업을 machine과 human metrics 공정을 거쳤습니다. (table1 참고). machine metric을 통해 무작위하게 1%의 processed data를 선택하였고 machine metrics에 계산 되도록 실행하였습니다. human metric을 통해 1000개를 선택했고 직접 추출된 corpus를 평가하였습니다. 이후 평가된 모든 예제에서 부적격 예제의 비율을 계산합니다. 만약 임계치보다 점수가 낮으면 데이터가 우리의 충족요건을 만족시켰고 해당 corpus는 학습 corpus로 사용하였습니다. 만약 임계치보다 점수가 높으면 우리의 기준을 만족시키지 않았으므로 AS, RF, CD 프로세스를 개선하여 데이터를 처리하는데 활용하였습니다.
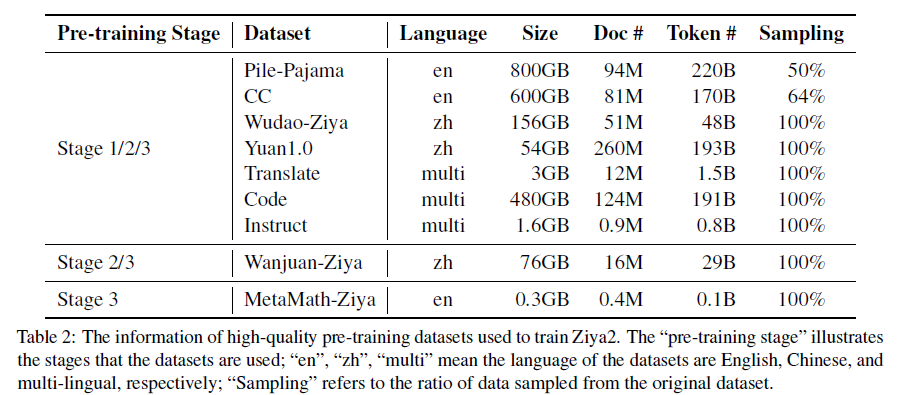
- The Resulted High-quality Data : 많은 데이터를 수집했고 13TB 중, 4.5TB만 추출하여 높은 품질의 오픈소스 데이터셋을 만들었습니다. Pile-Pajama, CC, Wudao-Ziya, Yuan1.0, Translate, Code, Instruct, Wanjuan-Ziya, MetaMath-Ziya 데이터셋을 사용하였습니다. 또한 연구진은 Markdown syntax를 사용하여 프로그래밍 언어를 다루는 질문을 생성할 때, formattted code를 산출하도록 유도하였습니다.
The Architecture of Ziya2
-
Tokenizer : 중국어의 representation을 강화하기 위해 BPE tokenizer를 사용. 주로 컴퓨터가 문자 인코딩을 처리하는 방식 때문에 BPE tokenizer는 중국어를 표현하기에 그리 효율적인 방법이 아닙니다. 예를들어, UTF-8 중국문자는 BPE 인코딩을 사용하는 2-4토큰으로 인코딩됩니다. Vocabulary에 중국문자를 추가한 후 10GB 중국 courpus를 사용하여 테스트 해 본 결과, 기존 tokenizer 대비 약 34% 성능 향상이 나타났습니다.
-
Positional Embedding : LLAMA2는 absolute position encoding 기반 메커니즘인 rotary position encoding을 차용합니다. overflow 이슈를 없애기위해 연구진은 FP32-precision 기반 rotary position encoding을 사용하였습니다. 이를 통해 지속적인 학습시에 데이터의 길이 분포의 변화를 더 잘 수용합니다.
-
Layer Normalization and Attention : 모델 학습시에 안정성과 효율성을 유지시키기 위해 LLAMA2의 attention과 layer normalization을 향상시켰습니다. 특히 후자는 APEX RMSNorm을 통해 구현하였으며 더불어 FP32-precision 학습으로 구동하였ㅅ습니다. Attention은 기존의 scaling, mask, softmax operator를 attention 모듈 내에서 fused-operator로 대체하여 구현하였습니다. 또한 overflow 방지를 위해 softmax 모듈 내에서 FP32-precision을 사용하여 학습하였습니다.
Continual Pre-training
- 다음은 학습 프로세스에 대한 내용입니다.
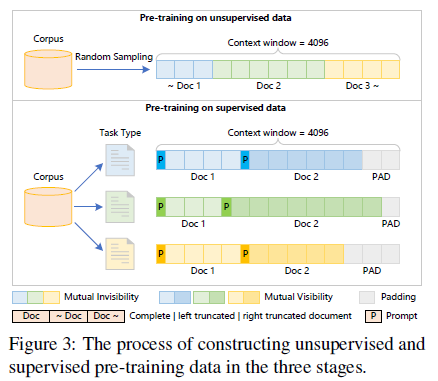
-
Initialization : Ziya-13B에서는 무작위 초기화를 사용합니다. LLaMA2가 이미 중국어와 관련된 일부 정보를 학습하고 있고 LLaMA2에서 중국어 한자는 문자는 2~4개의 토큰에 해당하며, Ziya2에서는 이러한 토큰의 임베딩에 대한 가중치 평균을 중국어 문자에 대한 임베딩으로 사용합니다.
-
Training Strategy : Continual pre-training동안의 가장 치명적인 이슈는 바로 catastrophic forgetting입니다. 목표는 LLAMA2의 중국어와 coding capabilities를 향상시키는 것입니다. 이를 달성하기 위해서 연구진은 continual pre-training을 3개의 stage에 나눠서 실행하였고 자세한 설명은 figure3에 묘사되어 있습니다. 첫 번째 stage에선 기존 LLAMA2의 원본 분포에 유사한 영어 데이터를 샘플링합니다. 또한 중국어 데이터도 샘플링합니다. 이로 인해 650B 비지도학습 데이터를 continual pre-training을 위해 모을 수 있게 됩니다. 연구진은 철저하게 이 데이터셋을 shuffle하였고 서로다른 데이터 세그먼트를 연결해 4096개의 컨텍스트로 연결하였으며 서로 다른 데이터끼리 영향을 미치지 않게 하기 위해 attention masking 처리를 사용하였습니다. 이러한 구성은 학습 효율성을 최대화 할 뿐만 아니라 Ziya2가 더 강력한 중국어 말하기 능력과 coding knowledge를 가능하게 만들어줍니다. 두번째 스테이지에선 중국어 및 영어 instruction으로 구성된 지도학습 데이터를 추가하여 downstream taskd에서의 모델 성능을 강화하였습니다. 세번째 스테이지에선 2단계와 동일한 구성 접근 방식을 사용해 Wanjuan-Ziya 및 MetaMath-Ziya와 같은 추론과 관련된 supervised-data를 통합하였습니다. 이러한 3가지 스테이지를 거쳐 모델의 코딩능력, 수학 추론 능력이 매우 향상하였습니다.
-
Optimizer : 몇가지 하이퍼파라미터 조정하였음.
-
Training Efficiency : Megatron, Deepspeed, flash-attention, fused-softmax 사용하여 163.0 TFLOPS per GPU per second 달성.
-
Training Stability :
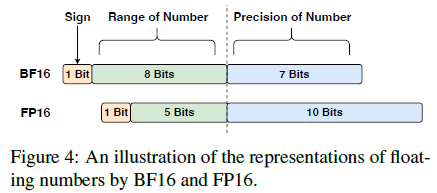
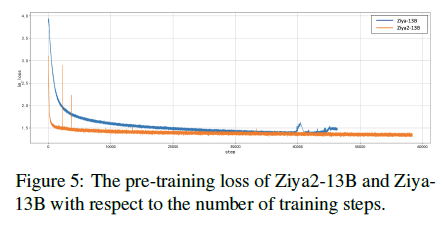
- Ziya-13B은 FP16 mixed-precision 적용한 학습과 빈번하게 loss spike issue를 직면했음.
- 이후 분석을 통해, FP16의 제한된 numerical range가 오버플로우 문제를 야기한다는 것을 알아냈음. 특히 softmax와 같은 operation과 같은 것들이.
- 따라서 Ziya2-13B에선 BF16 mixed-precision 학습을 선택했음.
Evaluation
- 총 6개의 benchmark dataset에서 평가 진행. 5-shot 실험을 실행하여 정확도 산출. MMLU, CMMLU, C-Eval, GSM8K, MATH, HumanEval. 언어종합적인 평가, 알고리즘 문제, 간단한 수학문제를 아루르는 다양항 범위의 benchmarking 진행하였습니다.
Baselines
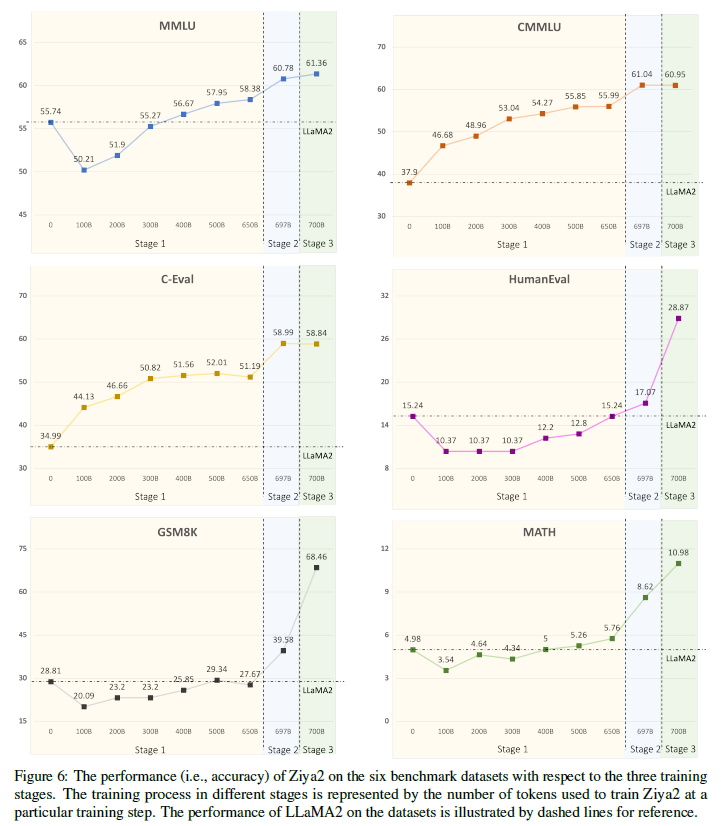
-
GPT와 더불어 비슷한 규모의 오픈소스 모델 선택. ChatGLM2-6B, Falcon-7B, Vicuna-13B, Baichuan2-13B, XVERSE-13B, WeMix-13B, LLAMA2-13B, Ziya-13B, GPT-3.5-turbo, GPT-4.
-
대부분의 모델을 능가하는 성능을 보여줬고 심지어 GPT-3.5-turbo의 모델보다 좋은 성능을 보였음. 연구진의 학습방법은 LLAMA2의 영어 언어 능력을 뛰어넘었을 뿐만 아니라 중국어 task에서의 대대적인 성능 향상이 이루어졌음.
-
추가적으로 Ziya2는 수학능력 및 코딩능력에서 모든 오픈소스 모델을 앞질렀음.
-
결론적으로 이러한 continual pre-training은 LLM의 일반적인 task에서의 성능 뿐만 아니라 특정한 필드에서의 성능을 꾸준하게 향상시킵니다.
Data Efficiency
- Ziya2의 훈련에서 데이터 효율성을 조사한 결과, 세 가지 주요 단계와 여섯 데이터셋에 대한 성능에 대한 영향이 드러났습니다. 초기에는 LLaMA2와 달리 중국어 말뭉치가 포함되어 MMLU에서 Ziya2의 성능이 저하되었습니다. 그러나 훈련이 진행됨에 따라 Ziya2는 보다 폭넓은 데이터셋에서 학습함으로써 중국어 및 영어 텍스트 처리 능력이 향상되었습니다. 두 번째 단계에서는 특히 C-Eval, GSM8K, MATH 등의 벤치마크에서 상당한 발전이 있었으며, 지도 학습 데이터가 사전 훈련에 미치는 기여가 크게 강조되었습니다. 세 번째 단계에서는 Meta-Math 데이터셋을 사용하여 Ziya2의 성능을 유지하면서 GSM8K 및 MATH에서 큰 향상을 보였습니다. 그러나 특정 데이터셋에 특화된 데이터 증가는 해당 데이터셋에서 모델의 성능을 크게 향상시킬 수 있다는 것을 실험 결과로 입증했지만, 이러한 “수월한” 향상이 실제 수학 능력을 개선하는 것이 아닐 수 있음에 주의가 필요하며, 모델이 문제 형식을 기억하는 것과 실제로 이해하는 것 사이의 균형을 유지해야 합니다.