DoRA - Weight Decomposed Low-Rank Adaptation [2024]
Introduction
NLP, multi-modal과 같은 각종 downstream task로부터의 application은 넓은 방향으로 확장되고 있습니다. 이 특정한 task에 모델을 적용시키기 위해선 full fine-tuning(FT)을 적용해야하는데 모델이나 데이터셋의 크기에 따라 그에 따른 resource도 굉장히 많이 필요로 하는 실정입니다.
이러한 관점에서 parameter-efficient fine-tuning(PEFT) 방법론이 나타났고 사전학습된 모델을 매우 적은 수의 파라미터만을 파인튜닝 하는 방식입니다. 그 중 LoRA는 모델의 구조를 변화시키지 않고 가장 효율적으로 학습할 수 있는 대표적인 방법론입니다. 그럼에도 불구하고 훈련 가능한 파라미터의 수가 제한되기 때문에 FT와 LoRA의 사이엔 여전히 격차가 존재합니다.
Weight Reparameterization을 통해 기울기의 조건을 개선함으로써 더 빠른 속도로 수렴하는 Weight Normalization에 따라, 연구진은 새로운 weight decomposition analysis을 소개합니다. 이는 규모나 직접적인 구성요소에 따라 초기에 모델의 가중치를 reparameterize하며 그 뒤에 LoRA와 FT에 의해 도입된 규모와 방향의 변화를 검토합니다. 연구진의 분석에 따르면 LoRA와 FT는 현저하게 다른 업데이트 패턴을 보여주며, 이러한 변이들이 각 방법의 학습 능력을 반영한다는 추측을 하게 됩니다. 연구진의 발견에 영감을 받아, 우리는 사전 훈련된 가중치를 크기와 방향 요소로 분해한 다음, 두 가지 모두를 fine-tuning하는 Weight-Decomposed Low-Rank Adaptation(DoRA)을 제안합니다. 파라미터 관점에서 상당한 양의 directional component를 고려해 볼 때, 연구진은 Figure1에 나타난대로 효율적인 파인튜닝을 실행하기 위해 directional adaptation을 통해 LoRA를 차용했습니다. 게다가 수학적으로나 실증적으로나 Full fine-tuning과 유사하게 보임으로써 연구진은 다양한 task에 걸쳐 (NLP, Vision-Language, backbones, LLM, LVLM) DoRA를 평가했습니다. 실험결과 추론효율성의 손해 없이 LoRA의 성능을 앞질렀습니다.
Related Works
PEFT (Parameter-Efficient Fine-tuning)
현재 존재하는 PEFT는 3가지 category가 있습니다.
첫번째는 Adapter-base 방법론입니다. 이는 기존의 고정된 backbone에 추가적으로 학습할 수 있는 모듈을 추가해주는 것입니다. 예를들어, (Houlsby et al., 2019)의 연구에선 추가적인 선형 모듈을 기존의 존재하는 layer에 추가하였습니다. 반면에 (He et al., 2021) 연구에선 이러한 모듈을 기존 레이어와 병렬로 통합하여 성능을 향상시키는 것을 나타냈습니다.
두 번째는 Prompt-based 방법입니다. 이 방법론은 추가적인 extra soft tokens(=prompts)을 초기의 input에 추가하고 파인튜닝할때 이 학습할 수 있는 vector에 집중시키는 방법론입니다. 그러나 이 접근들은 전형적으로 initialization할 때의 민감함으로 인해 종종 어려움을 겪어 전체적인 효과에 영향을 미칩니다.
이 첫 번째 두 범주는 모델의 입력 또는 아키텍처를 변경하는지에 관계없이, 기준 모델에 비해 추론 지연 시간이 증가하는 결과를 가져옵니다.
LoRA and its variants
Pattern Analysis of LoRA and FT
Low-Rank Adaptation (LoRA)
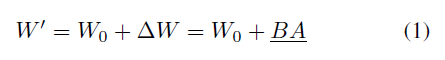
미세 조정 중에 수행된 업데이트가 낮은 “intrinsic rank”를 보여준다는 가설에 기반하여, LoRA는 두 개의 low-rank matrices의 곱을 사용하여 사전 훈련된 가중치를 점진적으로 업데이트할 것을 제안합니다. 사전학습된 가중치 행렬을 통해 LoRA low-rank 분해를 활용하여 가중치 업데이트 $\triangle W \in \mathbb{R^{d\times r}}$를 모델링합니다. 그 후에 fine-tuned weight는 $W’$에 투영될 것이고 eq1에서 $W_0$엔 fine-tuning process동안에 고정될 것입니다. 그리고 밑줄친 파라미터들은 학습될 것입니다. 행렬 $A$는 uniform Kaiming distribution에 의해 초기화되며 $B$는 0값으로 초기화될 것이며 결과적으로 $\triangle W = BA$로 학습 초기엔 0값이 될 것입니다. 특히, $\triangle W$의 decomposition은 다른 LoRA나 VeRA와 같은 variatns로 대체되어질 수 있습니다. 추가적으로 Eq1에 근거하여 연구진은 학습된 $\triangle W$를 사전학습된 가중치 $W_0$와 merge하였고 배치 초반에 $W’$ 가중치를 얻었습니다. 그리고 $W’$와 $W_0$ 둘다 모두 $\mathbb{R^{d\times k}}$의 차원 내에 포함되기에 LoRA와 관련 variants는 원래 모델에 비해 추론 중 추가적인 지연을 받지 않습니다.
Weight Decomposition Analysis
LoRA연구에 의하면 LoRA를 full fine-tuning의 일반적인 근사치로 간주할 수 있음을 시사합니다. 사전학습된 가중치의 rank와 함께 align에 LoRA의 rank를 점차 늘려감에 따라, LoRA는 FT와 유사한 수준의 성능을 달성할 수 있습니다. Weight Normalization에 영감받아, 연구진은 혁신적인 weight decomposition analysis 방법을 소개합니다. 이 분석방법은 가중치 행렬을 2개의 분리된 요소로 재구성합니다. magnitude (크기) 그리고 direction (방향), 이는 LoRA와 FT의 학습 패턴과 조금 다른점이 존재합니다.
Analysis Method
The weight decomposition of $W \in \mathbb{R^{d\times k}}$의 식은 다음과 같습니다.
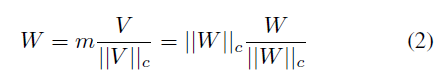
이 weight decomposition을 위해 연구진은 VL-BART 모델을 4개의 image-text task에 파인튜닝하하여 case-study를 진행하였습니다. (Sung et al., 2022) 연구에서 LoRA를 self-attention 모듈내의 query/value 가중치 행렬에만 적용하였습니다. 연구진은 사전학습된 가중치 $W_0$, full fine-tuned 가중치 $W_{FT}$, EQ2에 표현된 query/value의 가중치 행렬의 병합된 LoRA가중치 $W_{LoRA}$를 decompose하였습니다. $W_0$와 $W_{FT}$ 사이에서 Magnitude와 directional variations는 다음과 같이 정의될 수 있습니다.
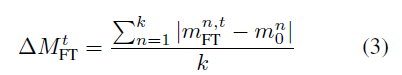
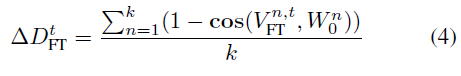
3번식과 4번식에 의해 크기와 방향성 $W_{LORA}$와 $W_0$의 차이는 유사하게 계산됩니다. 연구진은 실험을 위해 4개의 서로 다른 training steps를 가지는 checkpoint들을 선택했고 3개는 중간정도의 steps, 마지막 1개는 마지막 checkpoint를 가지는 모델 (FT, LoRA)을 선별하였습니다. 그리고 각각의 checkpoint에서 weight decomposition의 성능을 체크하였습니다.
Analysis Results
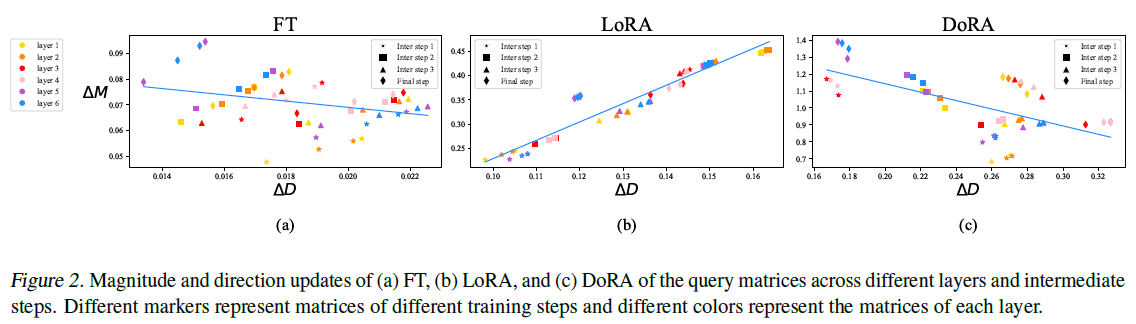
위 figure2의 (a)와 (b)는 각각 FT와 LoRA환경에서 query 가중치 행렬의 변화를 나타냅니다. 각각의 point $\triangle D^t$, $\triangle M^t$는 다른 레이어들과 학습 스텝에서의 query 가중치 행렬들을 나타냅니다. 유사하게도 figure5는 value 가중치 행렬을 나타냅니다. 이는 LoRA는 모든 중간 step에서 일관된 양의 기울기 추세를 나타내며 방향과 크기의 변화 사이에서 비례 관계가 있음을 나타냅니다. 대조적으로 FT는 음의 기울기 추세와 함께 더 다양한 학습 패턴이 보여집니다. FT와 LoRA의 이러한 차이는 아마도 각각의 학습 능력을 반영하는 것 같습니다.LoRA는 magnitude & direction updates가 상승하거나 하락하는 경향이 있으나 미묘하게 조절을 위한 기능은 떨어집니다. 특히 LoRA는 magnitude 변화는 크나 directional 변화할때의 효율성을 좋지 못해 보입니다. 결과적으로 이번 연구에서는 FT의 학습 패턴과 더 유사한 학습 패턴을 보이고 LoRA보다 학습 능력을 개선할 수 있는 LoRA의 변종을 제안하려고 합니다.
Method
Weight-Decomposed Low-Rank Adaptation
DoRA는 초기에 사전학습된 가중치를 magnitude와 directional components에 따라 분해하며 그것들을 파인튜닝합니다. Directional Components는 파라미터 수의 관점에서 크기 때문에, 효율적인 파인튜닝하는 LoRA와 함께 더 decompose 하였습니다.
DoRA의 메인 포인트는 2개입니다. 첫째로, LoRA를 directional adaptation에만 집중하도록 제한하면서 magnitude component도 조정 가능하게 하는 것은, LoRA가 magnitude와 direction 모두에서 조정을 학습해야 하는 기존 접근법에 비해 작업을 단순화합니다. 두번째로, 방향 업데이트를 최적화하는 절차는 행렬분해를 통해 좀 더 안정화되어집니다. DoRA와 weight normalization의 주요 차이점은 훈련 접근법에 있습니다. Weight normalization은 두 가지의 요소들을 처음부터 끝까지 학습하며 이 방법론은 다른 초기화방법에 더 민감하게 만들어줍니다. 반대로 DoRA는 두 가지의 요소들이 사전학습된 가중치와 함께 시작되기에 초기화 문제를 피할 수 있습니다.
Figure 2 (c)에 DoRA에 대한 자세한 사항을 표현하였습니다. LoRA의 기울기와는 반대로 DoRA의 경우 음의 기울기 형태를 나타냅니다. 우리는 사전 훈련된 가중치가 이미 다양한 downstream task에 적합한 상당한 지식을 가지고 있기 때문에 FT가 부정적인 경향을 보인다고 추론합니다. 그러므로 적절한 학습 능력이 주어질 경우, 그 규모와 방향 변경이 더 큰 폭일 경우에 downstream 적용이 충분히 효율적임을 시사합니다. 더불어서 correlation 값을 추출해본 결과 FT (-0.62), DoRA (-0.31), LoRA (0.83) 값으로 나타났습니다. 결론적으로 DoRA가 상대적으로 최소한의 크기 조정 또는 그 반대의 경우에 상당한 방향 조정을 수행하면서 FT의 학습 패턴에 더 가깝게 나타나는 능력을 보여주는 것은 LoRA에 비해 우수한 학습 능력을 나타냅니다.
Gradient Analysis of DoRA
DoRA의 학습 패턴을 분석하고 부정적인 경향을 보이는 것을 설명합니다.
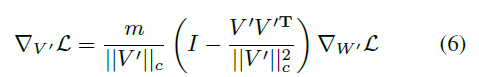

| Eq6 식을 통해 Loss $L$에 대한 $m$과 $V’ = V + \triangle V$의 기울기를 얻을 수 있습니다. Eq6은 가중치 기울기 $∇W′L$이 $m/ | V ′ | c$에 의해 스케일링되고 현재 가중치 행렬로부터 멀리 투영됨을 보여줍니다. 이러한 두 가지 효과는 기울기의 공분산 행렬을 identity 행렬에 더 가깝에 정렬하는데 기여하며 이는 최적화에 유리합니다. 또한 $V’ = V + \triangle V$이므로, 기울기 $∇ΔV L.$과 동일합니다. 따라서 이러한 분해에서 얻은 최적화의 이점은 $ΔV$로 완전히 전이되어 LoRA의 학습 안정성을 향상시킵니다. |
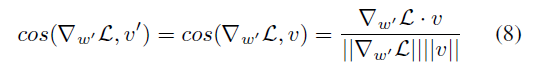
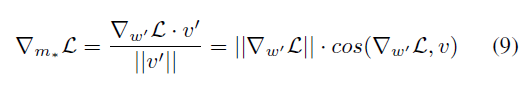
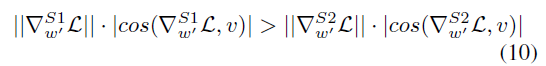
또한 Eq7을 통해 DoRA의 학습 패턴에 대한 추가적인 통찰을 얻을 수 있습니다. S1은 S2보다 더 큰 크기 업데이트를 가지지만 방향 변화가 더 적음을 의미합니다. figure 2 (c)에 입증됩니다. 따라서 DoRA가 LoRA의 학습 패턴에서 벗어나 FT의 패턴에 더 가깝게 조정되는 방법을 효과적으로 보여주었습니다.
Experiments
언어모델 뿐만 아니라 다양한 task (Vision, VQA task)에 LoRA, VeRA, DoRA를 적용
Commonsense Reasoning
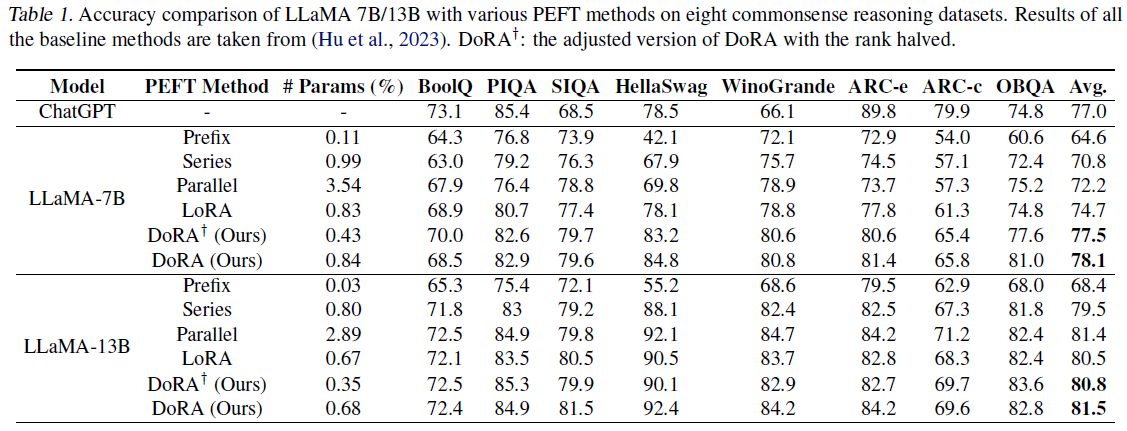
Llama-7B/13B 모델을 commonsense reasoning task에 DoRA, LoRA와 Prompt learning(Prefix), Series Adapter(Series), Parallel Adapter(Parallel) 방법론을 적용해보았습니다. 또한 ChatGPT api를 사용하여 zero-shot CoT를 적용한 ChatGPT accuracy를 포함시켰습니다.
Commonsense Reasoning은 8개의 sub-task로 이루어져있으며 각각 사전 정의된 학습과 테스트 셋으로 이루어져있습니다. 연구진은 8개의 task로부터 학습 데이터셋을 모두 병합하여 최종 학습 데이터셋을 만들었으며 평가는 각기의 평가데이터셋에서 이루어졌습니다. 비교를 확실히 하기 위해, 연구진은 LoRA configuration을 따라 DoRA를 파인튜닝하였으며 같은 rank값을 유지하였고 오직 learning rate값만 조정하였습니다. DoRA의 학습 가능한 파라미터 수가 LoRA에 비해 0.01% 증가한 것은 학습 가능한 크기 조절 구성 요소 (parameter of size $1\times k$)를 포함했기 때문입니다. 이 증가된 파라미터는 DoRA의 효과와 유연성을 높이는데 기여한 것으로 보여집니다. 그 후에 LoRA와 DoRA를 비교하기 위해 rank 값을 반으로 줄였습니다. 이는 $DoRA^{+}$로 테이블1에 표시되어있습니다.
2개의 모델 모두 꾸준하게 DoRA 방법론은 baseline을 모두 능가하였습니다. 특히 7B 모델에선 3.4% 앞서나갔습니다. LoRA에 비해 더 낮은 학습파라미터로 더 성능이 좋은 모델을 만들 수 있었습니다.
Image/Video-Text Understanding
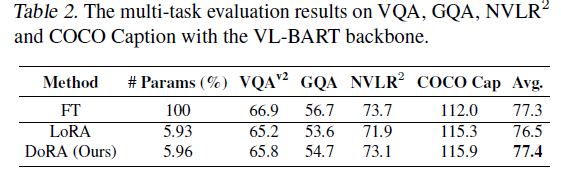
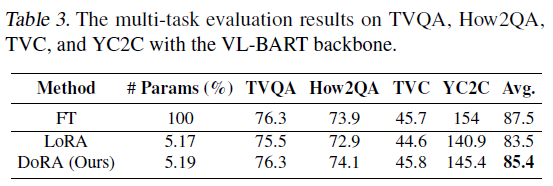
VL-BART모델(vision encoder 사용) / $BART_{Base}$ (en-decoder 사용)에 DoRA, LoRA, FT를 4개의 image-text task들: $VQA^{v2}$, GQA(visual question answering), $NLVR^{2}$(visual reasoning), MSCOCO(image captioning), 4개의 video-text task들: TVQA, How2QA, TVC, YC2C에 적용하여 성능을 측정하였습니다.
Visual Instruction Tuning
LLaVA-1.5-7B 모델을 사용하여 마찬가지로 DoRA, LoRA, FT 비교.
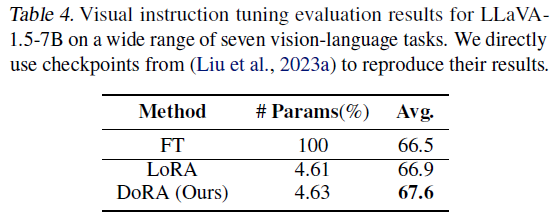

Compatibility of DoRA with other LoRA variants
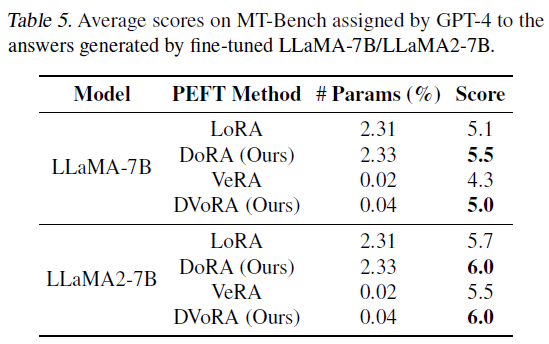
LoRA, VeRA, DoRA, DVoRA(VeRA + DoRA)를 통해 Llama-7B / Llama2-7B 모델 비교. GPT-4 모델을 통해 평가하여 ~ 10의 score 추출.

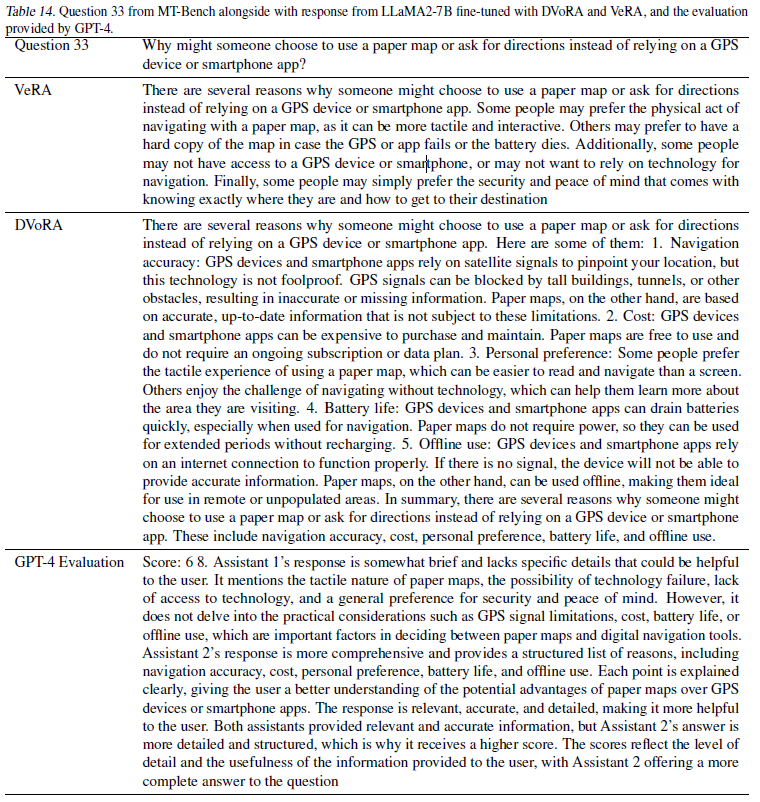
다음으로 DoRA가 학습데이터의 양이 적을 경우, 모델 성능을 유지할 수 있는지 살펴보는 실험을 진행하였습니다. DoRA의 효율성과 효과성을 판단하기 위해 이 부분을 연구하고, 이를 통해 데이터 제한 환경에서의 DoRA의 실용성을 파악합니다. 마찬가지로 Llama1/2-7B 모델에 FLAN 데이터셋을 샘플 사이즈만큼 파인튜닝하였고 특히 셋팅 사이즈는 (Kopiczko et al., 2024) 연구에 근거하여 각각 1000, 4000, 7000, 10000로 제한하였습니다.
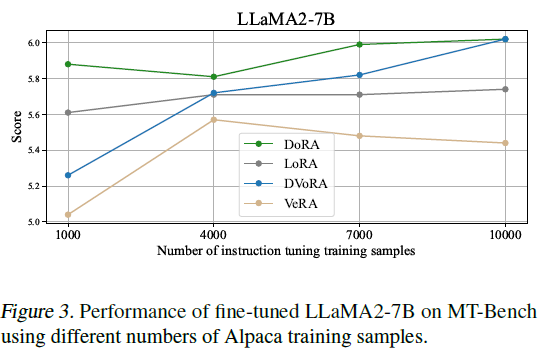
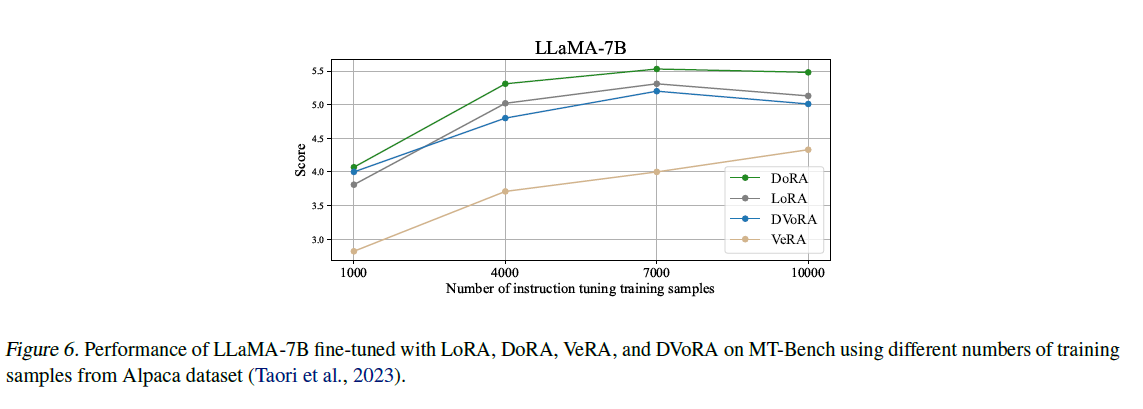
꾸준하게 DoRA와 DVoRA가 LoRA와 VeRA를 모든 학습 사이즈에서 앞질렀습니다. 특히 학습 사이즈가 적을때 (1000개) 성능의 격차가 가장 큰 것으로 보여집니다.
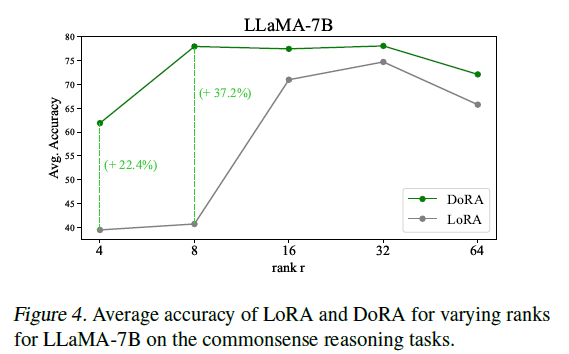
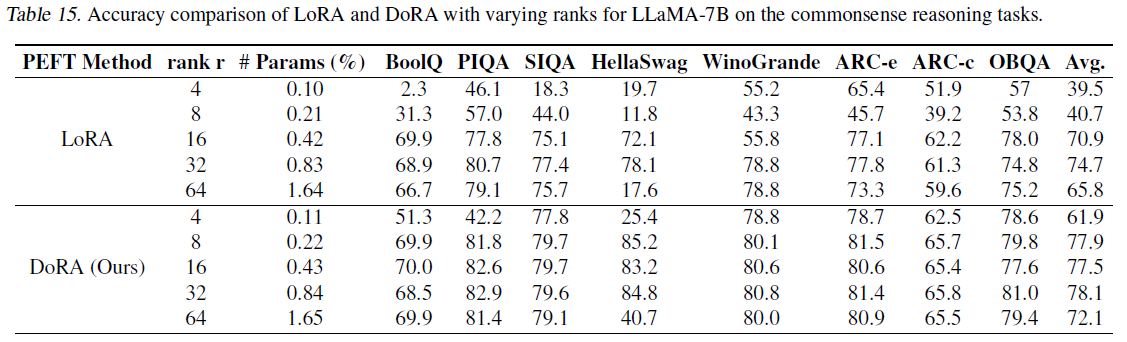
Robustness of DoRA towards different rank settings
다양한 rank($r$)값에 따른 성능 변화 실험.
- set: {4, 8, 16, 32, 64}
- model: Llama-7B
- task: commonsense reasoning
마찬가지로 꾸준하게 LoRA의 성능을 능가하였으며 특히 rank가 8일때 가장 큰 격차로 나타났습니다. LoRA의 경우 r=8일때, 40.74%, r=4일때, 39.49%를 기록하였습니다. 대조적으로 DoRA의 경우 r=8일때, 77.96%, r=4일때, 61.89%를 기록하였습니다.
Tuning Granularity Analysis
Figure2에 나와있듯이, 방대한 magnitude의 변경은 종종 더 적은 directional change와 연관있는 결과를 가져옵니다. Directional updates가 대부분의 학습가능한 파라미터를 처리한다는 사실을 고려하면, 이는 특정 모듈의 크기 조절 구성 요소만 업데이트하면서 나머지 선형 모듈의 크기와 방향 구성 요소를 모두 계속 업데이트하는 방식으로 학습 가능한 파라미터 수를 줄일 수 있는지에 대한 조사를 유도합니다. 이러한 방식은 전체 모델의 학습 파라미터 수를 줄이면서도 필요한 부분에서는 학습 능력을 유지할 수 있을지 살펴봅니다. 이를 통해 모델의 효율성과 자원 사용 최적화를 향상시키면서도 성능 저하를 최소화할 수 있는 전략을 모색할 수 있습니다.
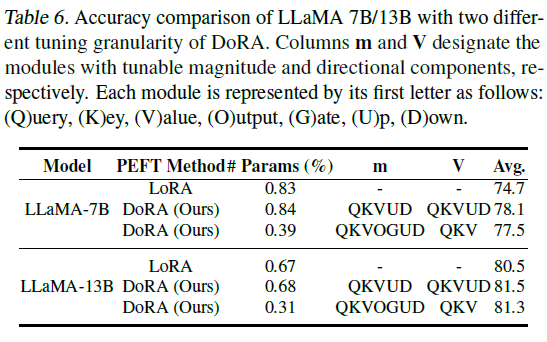
연구진이 찾아낸것에 의하면 LoRA 연구진이 암시한것과 대조적으로 최적희 성능을 위해서는 MHA와 MLP 레이어에서 반드시 update가 필요합니다. DoRA는 최적의 성능을 단지 MH / MLP 레이어의 directional & magnitude 구성요소들을 업데이트 함으로써 달성한 바가 있습니다. 특히 table6에 나와있듯이, QKV 모듈에서의 2개의 구성요소들을 업데이트함으로써 DoRA는 LoRA보다 학습 파라미터를 절반으로 사용하고, 성능은 2.8% (Llama-7B), 0.8% (Llama-13B) 만큼 높게 측정되었습니다.
의의
- LoRA와 Full fine-tuning 방식에서 학습 패턴을 추출하여 novel한 weight decomposition 방식을 수행
- 언어모델 뿐만 아니라 제한적이긴 하나 Vision 모델에도 DoRA 적용하여 우수한 성능 달성
- Flexible Integration (combinate with VeRA -> DVoRA)
- Image-to-text 분야에서의 추가적인 연구 시사점을 기대