Transformer - Attention Is All You Need [2017]
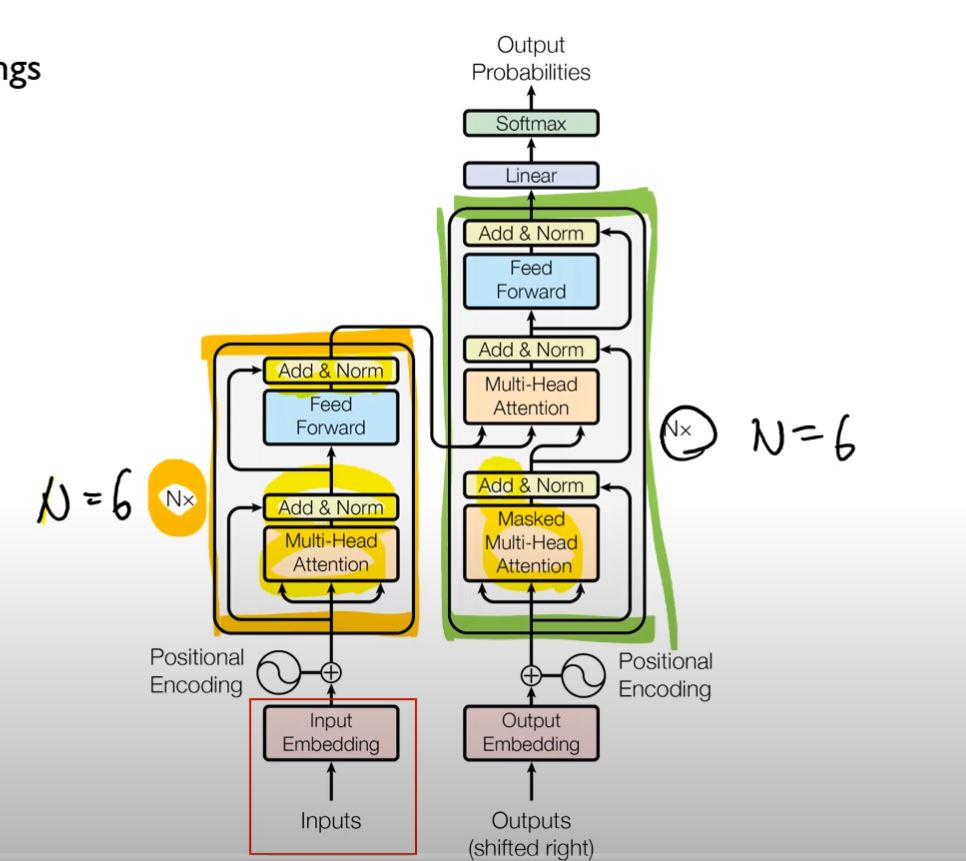
Transformer
기존의 RNN처럼 하나씩 처리하는게 아닌 한꺼번에 처리하며, 기존의 Attention 메커니즘을 사용하면서 학습과 병렬화(Parallelize)가 쉽게 되게하는 모델
출현배경
기존 Seq2Seq 모델은 Encoder-Decoder 구조로 구성되어 있었다. 여기서 Encoder는 입력 시퀀스를 하나의 벡터 표현으로 압축하고, Decoder는 이 벡터 표현을 통해 출력 시퀀스를 만들어냈다. 하지만, 이러한 구조는 Encoder가 입력 시퀀스를 하나의 벡터로 압축하는 과정에서 입력시퀀스의 정보가 일부 손실된다는 단점이 있었고, 이를 보정하기 위해 Attention이 사용되었다
Transformer가 기존 모델과 다른점
- Transformer 내부에 Encoding Component와 Decoding Component가 따로 존재
- 연결시키는 구조가 다름
Self-Attention
- Encoding Component = stack of encoders
- 그저 인코더를 쌓은 형태
- 논문에서는 6개를 stack했고, 논문의 저자가 최적의 값이 아니라고 소개
- 한번에 모든 시퀀스를 사용해 masking을 사용하지 않는 ‘Unmasked’
- Input > Self-Attention > FFNN를 거치는 2단구조
- Decoding Component = stack of decoders
- 이 또한, 디코더를 단순히 쌓은 형태
- 어찌됐든 output은 순차적으로 내야하기 때문에 순서에 따라 masking하는 ‘Masked’
- Maked Self-Attention > Encoder-Decoder Self-Attention > FFNN를 거치는 3단구조
- RNN계열 모델에선 Encoder / Decoder가 하나씩 존재했지만, Transformer에선 다수의 Encoder / Decoder가 존재
- Transformer에선 512개의 TOKEN을 사용하고 이 길이를 맞추지 못하면 Padding
Encoder Block
- 각각의 인코더는 구조적으로 전부 동일하나, 구조적으로 같다고해서 weight를 share하는 것은 아니다.
- 첫번째 encoder block과 두번째 encoder block의 가중치는 얼마든지 달라질 수 있다.
- 두 개의 하위계층(sub-layer)으로 구성
- Self-Attention Layer
- 한 단어의 정보를 처리할 때, 함께 주어진 input sequence의 다른 단어들을 얼마마큼 중요하게 볼 것인가를 계산하는 layer
- FFNN(Feed Forward Neural Network)
- 매 Input에 각각의 Neural Network를 독립적으로 적용하여 Output값 산출
- Self-Attention Layer
Input Embedding
- 인코더의 최하단에서 사용, 밑단에 있는 인코더는 word embedding을 수행. 그 외의 인코더는 바로 아랫단의 인코더들의 output으로 받는다. 동시에 이들의 사이즈는 동일하게 유지
- 한 sequence의 길이를 최대 몇으로 가져갈까 결정하는 하이퍼파라미터
- 논문에선 512로 설정
ex) 상위 90%에 해당하는 토큰의 개수로 설정 or 학습 데이터셋에서 가장 긴 문장의 길이로 설정
Positional Encoding
- RNN은 하나의 sequence만을 입력으로 받기에, 위치정보를 그대로 저장하나, Transformer에선 모든 sequence를 한번에 입력으로 받기에, 위치정보가 손실되는 단점이 있다. 그 정보의 완전한 복원은 불가능하니 각가의 위치정보를 어느정도 복원해주자는 목적으로 만들어짐
- Input Embedding과 Positional Encoding을 더해준다. (concat의 개념이 아니며, 결과물도 같은 차원의 형태를 띌 것)
- 해당하는 Encoding vector의 크기는 동일해야한다
- 위치관계를 표현하고 싶은것이니, 두 단어의 거리가 Input Sequence에 멀어지게되면 Positional Encoding 사이의 거리도 멀어져야한다
Self-Attention
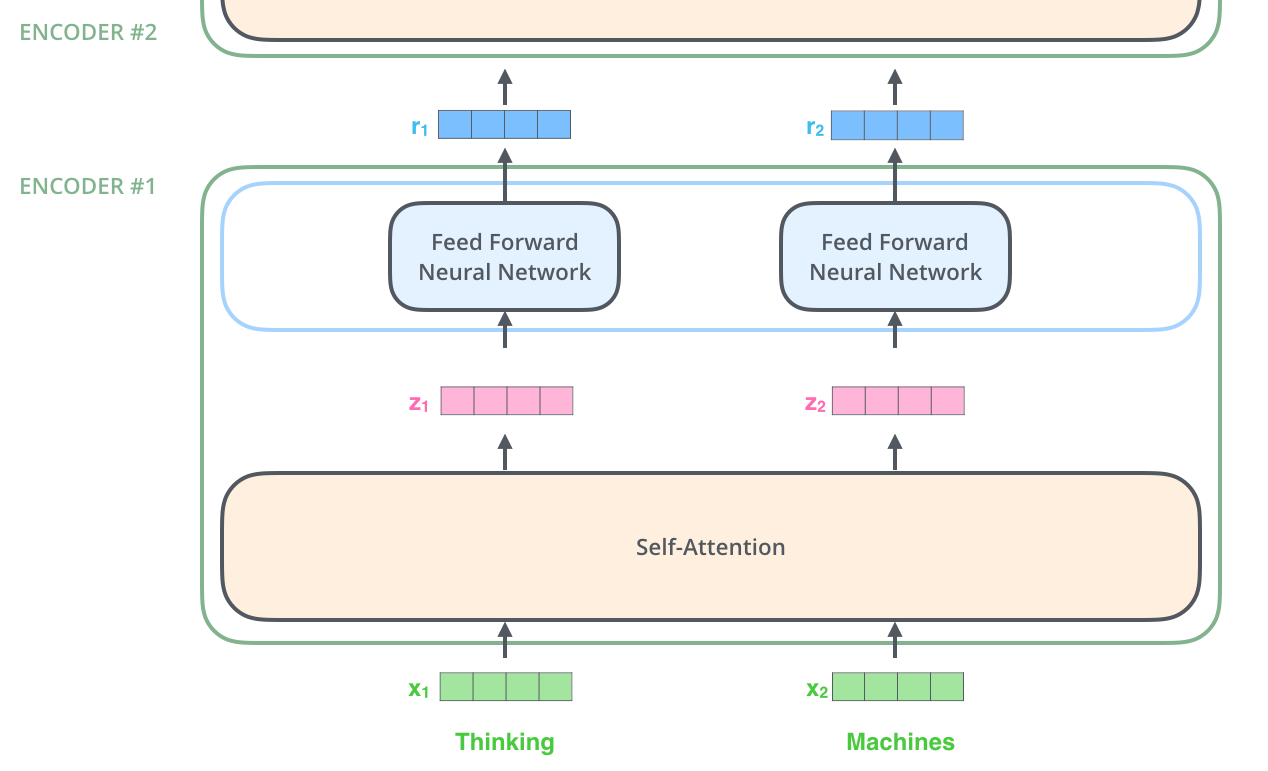
- 개념
- Self-Attention층에서 이 위치에 따른 path들 사이에 모두 dependency가 존재하는데, FFNN는 dependency가 없기에 FF layer 내의 다양한 path들은 병렬처리(parallelize)가 불가능
- FFNN의 weight들은 모두 동일
- Input Sequence : ‘The animal didn’t cross the street because it was too tired.’
- 사람들은 “it”이 가리키는 정보가 앞에 나와있는 “street”와 “The animal” 중 “The animal” 이라는 것을 단번에 알 수 있지만, AI는 그것이 불가능
- 그렇기에 각각의 단어들을 훑어가면서 it과 연관이 있는 단어는 무엇일까? 라는 질문에 답을 구하고자하는 것
- 모델이 입력 문장내의 각 단어를 처리해 나감에따라, self-attention은 입력문장내의 다른 위치에 있는 단어들을 보고 거기서 힌트를 받아 현재타겟위치의 단어를 더 잘 encoding 할 수 있다

- “it”이라는 단어를 encoding 할 때, attention 메커니즘은 입력의 여러 단어들 중에서 “the animal”이라는 단어에 집중하고 이 단어의 의미 중 일부를 “it”이라는 단어를 encoding 할 때 이용한다
Self-attention is the method the Transformer uses to bake the “understanding” of other relevant words into the one we’re currently processing
- Mechanism
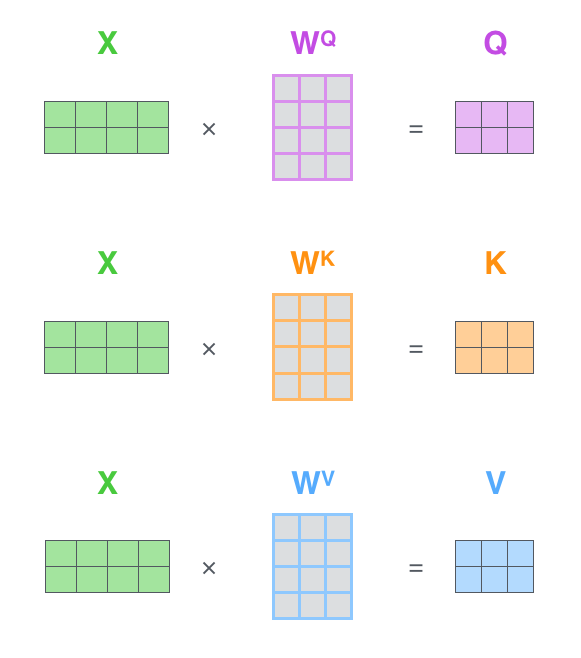
- 세 종류의 벡터 생성
- Query : 현재 보고 있는 단어의 representation, 다른 단어를 스코어링 하기 위한 기준값
- Key : 모든 단어들에 대한 label과 같은 의미를 지닌다. Query가 주어졌을 때, Key값을 참고해 relevant한 단어를 추출
- Value : 실제 단어가 나타내는 값
-
Query, Key를 통해 적절한 Value값을 찾아, 연산을 진행
- $X_1 * W^Q = q_1$
($W^{Q}$, $W^{K}$, $W^{V}$는 학습을 통해 찾아야하는 미지수)
- 세 종류의 벡터 생성
Step 1 : 각각의 인코더 Input으로부터 3개의 벡터를 만들어내자
- 일반적으로 Q, K, V의 차원은 인코더의 Input/Output보다 작게 만든다
- 굳이 더 작게 만들 필욘 없지만, Multi-Head Attention의 연산에 있어서 유리하게 적용시키기 위해 대개 그렇게 만든다
Step 2 : 스코어 값을 계산하자
- Q와 K 각각에 dot-product를 수행해 스코어값을 산출
- 단어와 Input Sequence 속의 다른 모든 단어들에 대해서 각각 점수를 계산
- 이 점수는 현재 위치의 이 단어를 encode할 때, 다른 단어들에 대해서 얼마나 집중을 해야 할지를 결정
Step 3 : 스코어값을 $\sqrt{d_{k}}$로 나눠준다
- 논문에선 8로 나눠줬음
- 이 과정은 gradient를 안정화시켜준다
Step 4 : softmax함수를 통해 결과값을 만들어준다
- softmax 함수를 통해 각각의 단어들은 매 위치에서 스코어값이 표현될 것 » 매 위치에서의 중요도를 나타내는 값
- 이 결과값은 현재 위치의 단어의 encoding에 있어서 얼마나 각 단어들의 표현이 들어갈 것인지를 결정한다. 당연하게 현재 위치의 단어가 가장 높은 점수를 가지며 가장 많은 부분을 차지하게 되겠지만, 가끔은 현재 단어에 관련이 있는 다른 단어에 대한 정보가 들어가는 것이 도움이 된다
Step 5 : softmax함수를 통해 도출된 결과값과 V 벡터를 곱해주자
- 집중하고싶은 관련이 있는 단어들은 그대로 남겨두고, 관련이 없는 단어들은 0.001과 같은 작은 숫자(score)를 곱해 없애버리기 위함
Step 6 : Step 5에서 나타난 값을 더해주자 -> 현재 위치에 대한 self-attention layer의 출력
- softmax에 의해서 가중합이된 value값들을 self-attention layer의 output 값으로 사용
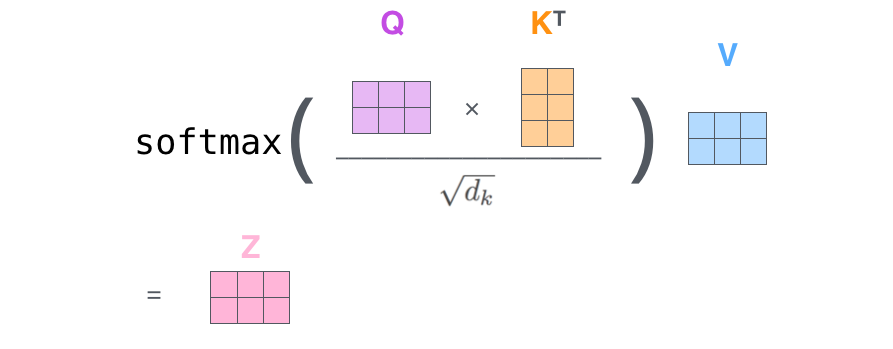
$Attention(Q,K,V)=softmax(\frac {QK^{T}}{\sqrt{d _{k}}})V$
Multi-Head Attention
-
지금까지 본 것은 single-head attention. Multi-head Attention은 하나의 경우의 수가 아닌 여러개의 경우의 수를 허용해 다수의 attention head 값(위 그림에선 Z 값)을 만들어내자 » 여러개의 attention을 사용
-
모델이 다른 위치에 집중하는 능력을 확장시킨다. 위의 예시 문장을 번역할 때, “it”이 무엇을 가리키는지에 대해 알아낼 때 유용할 것
-
attention layer가 여러개의 “representation 공간”을 가지게 해준다. multi-head attention을 이용함으로써 여러개의 Q, K, V weight 행렬들을 가지게된다. 이 각각의 Q, K, V set은 랜덤으로 초기화되어 학습된다.
-
학습이 된 후, 각각의 세트는 입력벡터들에 곱해져 벡터들을 각 목적에 맞게 투영시키게 된다. 이러한 세트가 여러개 있다는 것은 각 벡터들을 각각 다른 representation 공간으로 나타낸다는 것을 의미
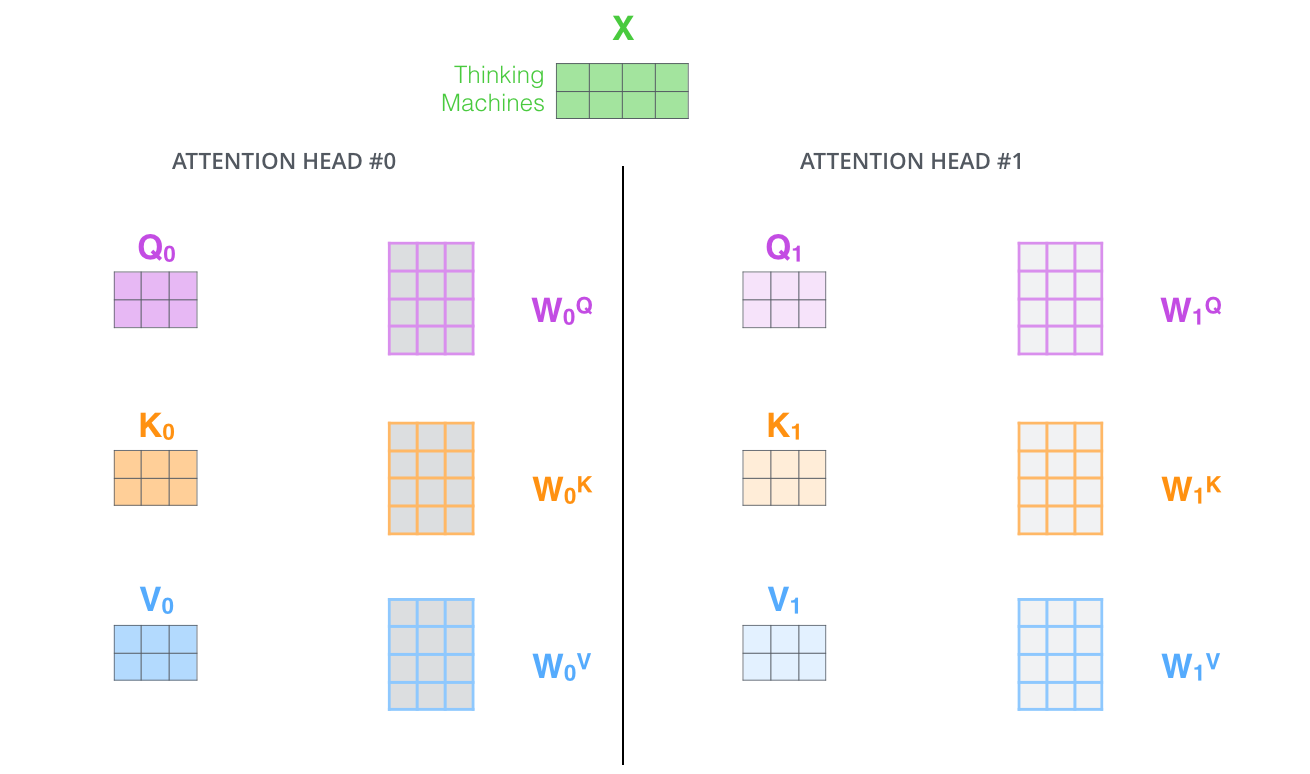
- multi-head atttention을 이용하기 위해서는 각각의 head를 위해서 각각의 다른 Q, K, V weight 행렬들을 모델에 가지게 된다. 벡터들의 모음인 행렬 X를 $W^{Q}$, $W^{K}$, $W^{V}$ 행렬들로 곱해 각 head에 대한 Q, K, V 행렬을 생성
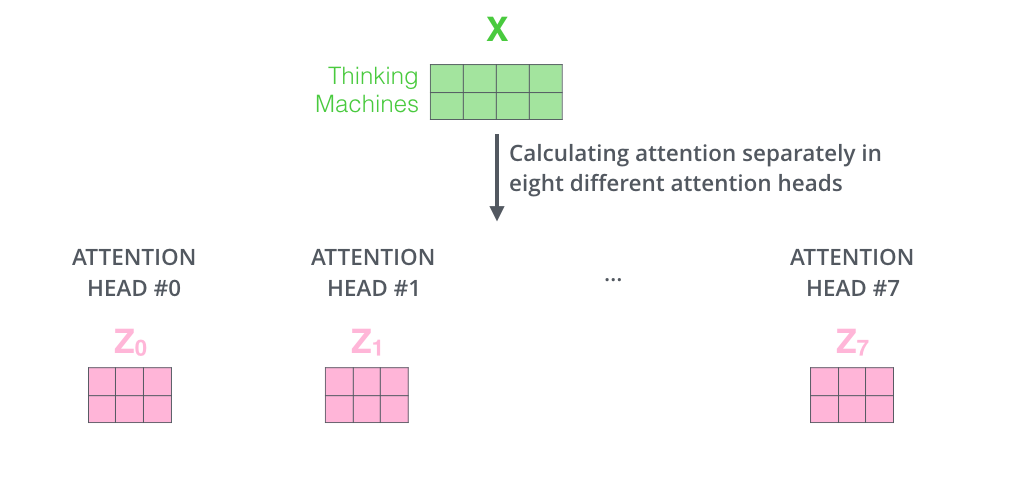
-
self-attention 계산 과정을 8개의 다른 weight 행렬들에 대해 8번 거치게되면, 8개의 서로 다른 Z 행렬을 가지게 된다
-
그러나 문제는 이 8개의 행렬을 바로 FF layer로 보낼 수 없다. FF layer는 한 위치에 대해 오직 한 개의 행렬만을 input으로 받을수 있기 때문이다. 그렇기 때문에 이 8개의 행렬을 하나의 행렬로 합치는 방법을 고안해야한다.
-
일단 Z행렬을 하나의 행렬로 만들기 위해 concatenate하고 난 후, 하나의 또 다른 weight 행렬인 을 곱하면 된다. 이 과정은 다음의 그림과 같다.
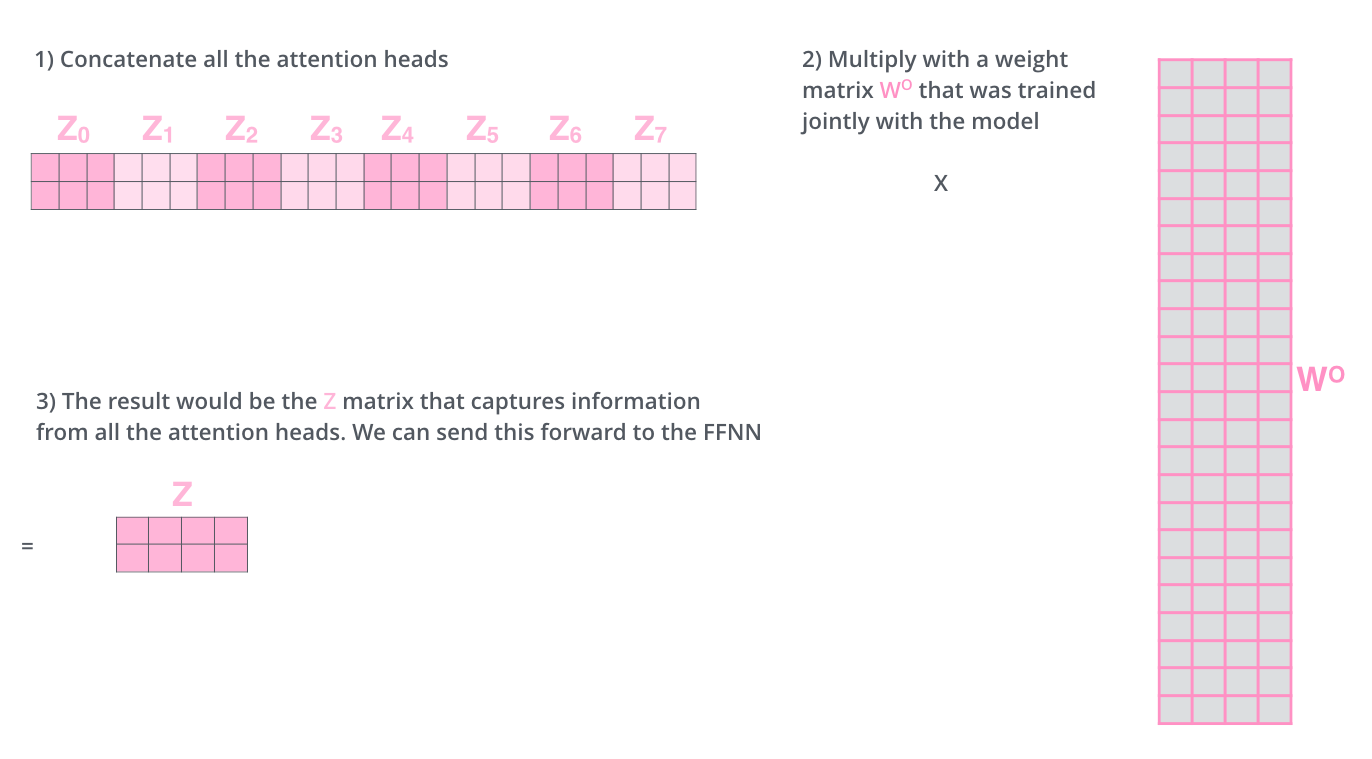
- 정리
- 모든 Attention head를 concat
- (attention head와 동일한 len, input embedding len) 의 크기를 가지는 $W^{O}$를 생성하여 step 1의 값과 곱한다
- 모든 attention head의 정보를 가지고 있는 결과값을 도출. 이는 최초 Input Embedding의 사이즈와 동일함. 또한, 이후 FFNN에 보내질 것이다
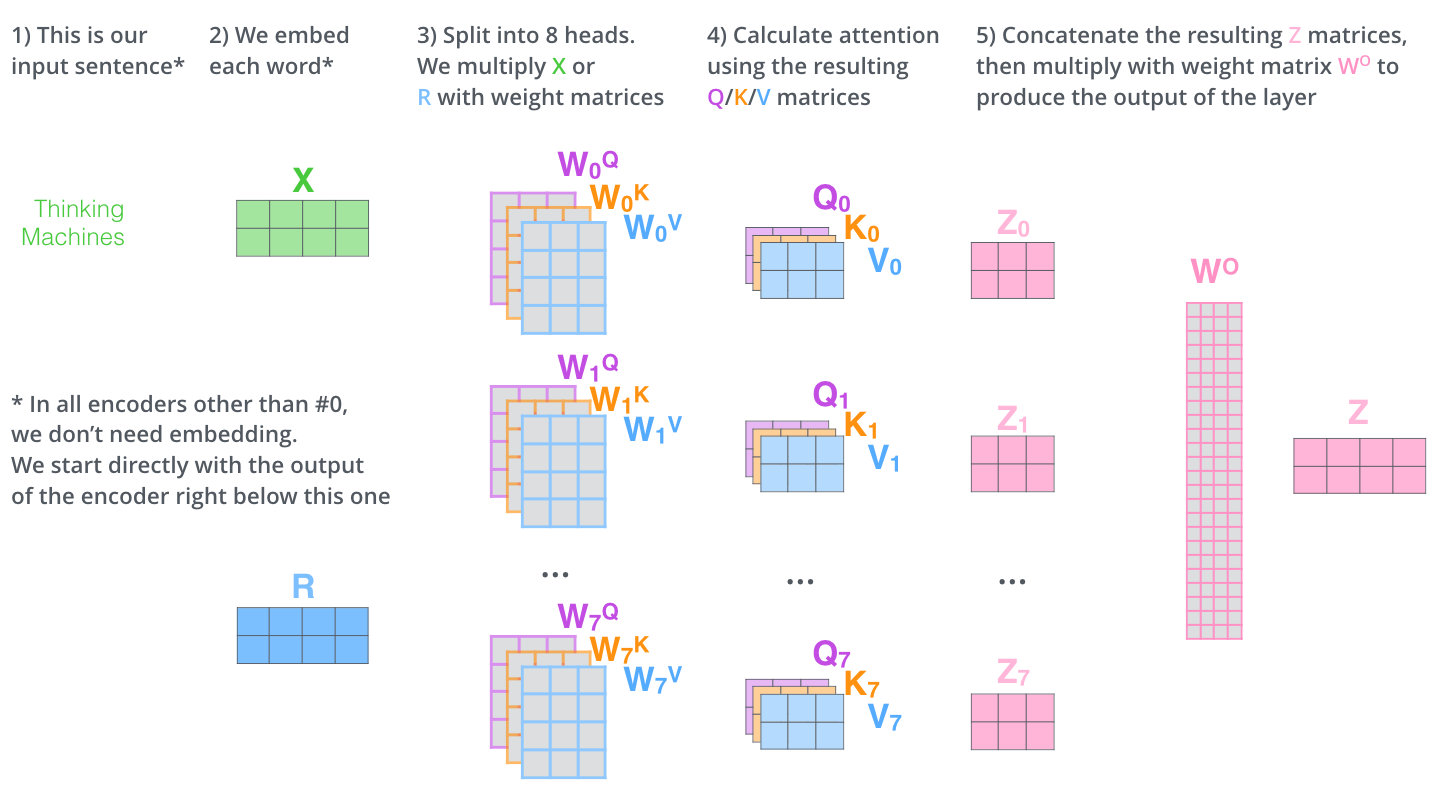 기존 인코더 인풋의 차원을 유지하면서 Multi-head Attention을 수행할 수 있음을 보여주는 사진
기존 인코더 인풋의 차원을 유지하면서 Multi-head Attention을 수행할 수 있음을 보여주는 사진
Residual Connection
- $f(x) + x$ 를 $f’(x) + 1$ 이라는 결과값이 나올테고 $f’(x) + 1$ 값이 매우 작은 값일지라도 “$+1$” 이라는 상수를 통해 gradient가 최소 1만큼의 값을 나타내기 때문에 학습에 굉장히 유리하게 작용 할 것
- $f(x) + x$에서 $f(x)$는 self-attention을 거친 Output값이고, $x$는 Input값
- 이 과정을 시각화한 이미지는 다음과 같다
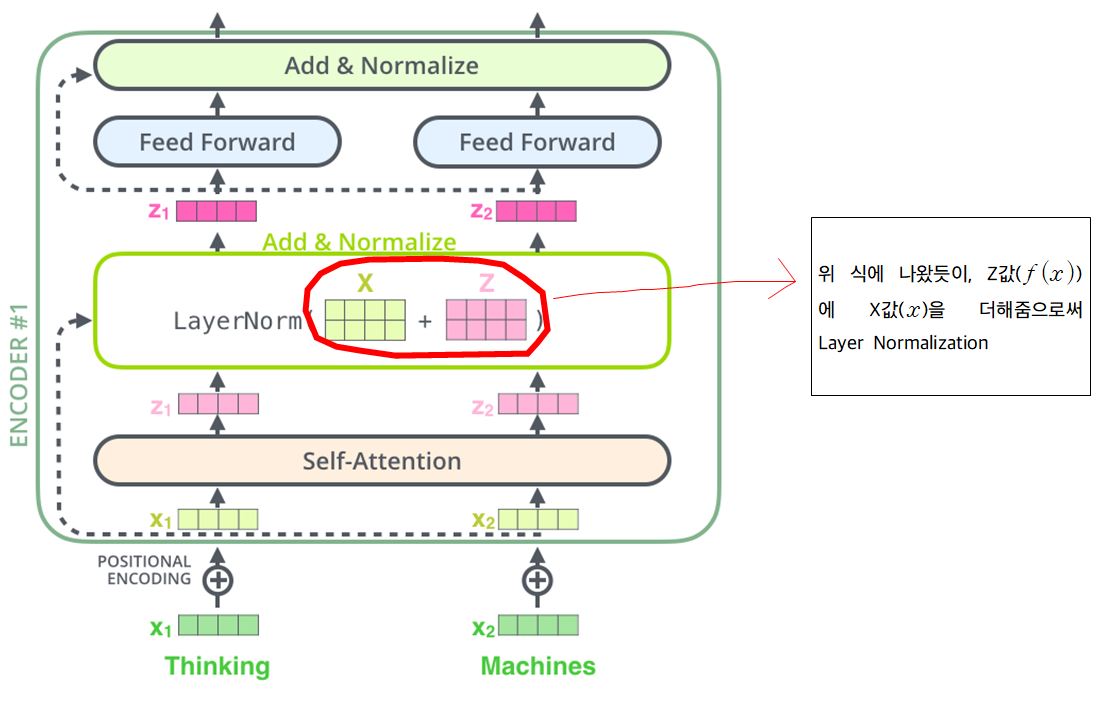
Layer Normalization
- Residual Connection 이후의 Output값은 FFNN에 보내진다.
- 위 2개의 과정은 Encoder, Decoder에서 default값으로 자주 사용한다
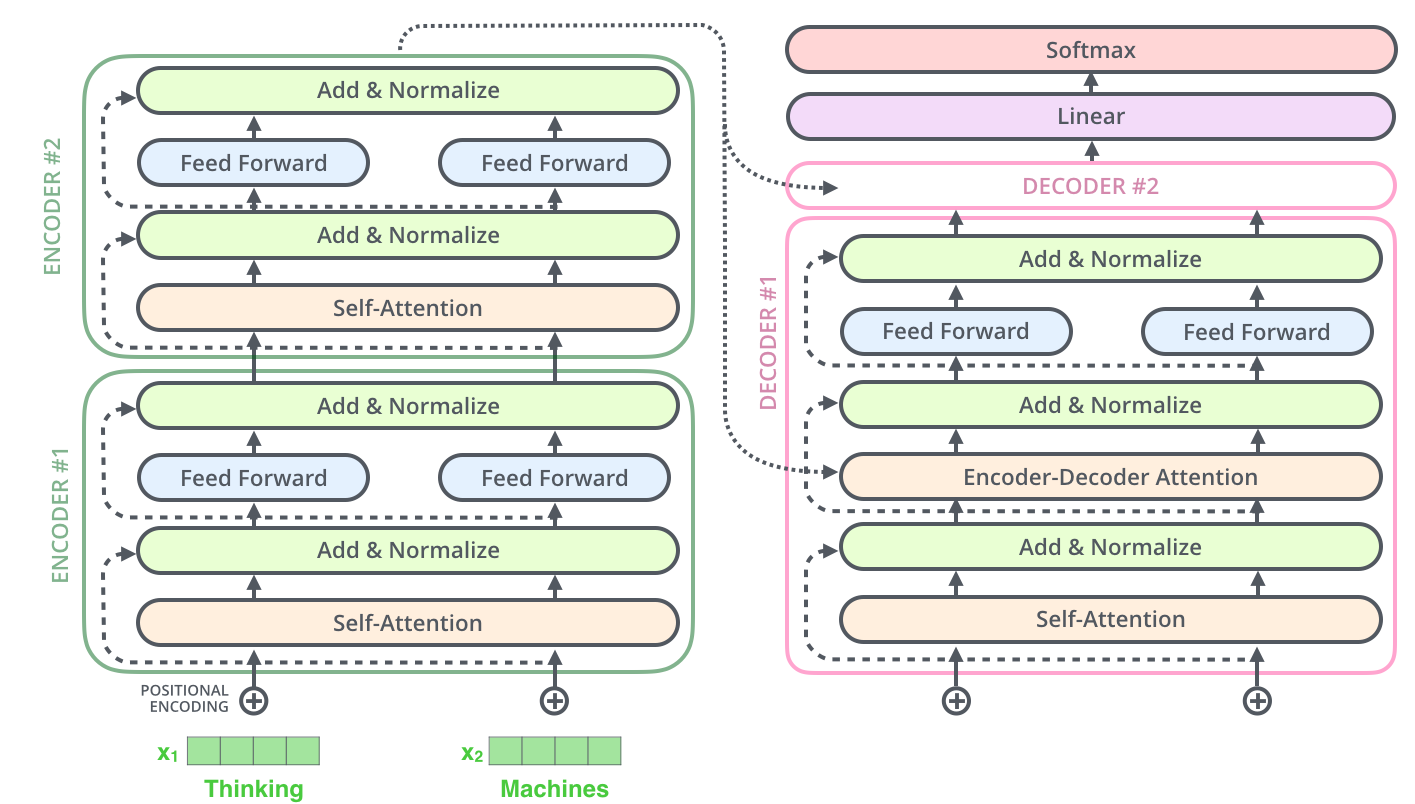
Position-wise FFN
- Fully-connected feed-forward network로 각각의 위치에 대해 개별적으로 적용된다
- $FFN(x) = max(0, xW_{1} + b_1)W_{2}+b_{2}$
- ReLU 함수 적용
- 각각의 layer마다 서로 다른 파라미터값을 사용한다
Decoder Block
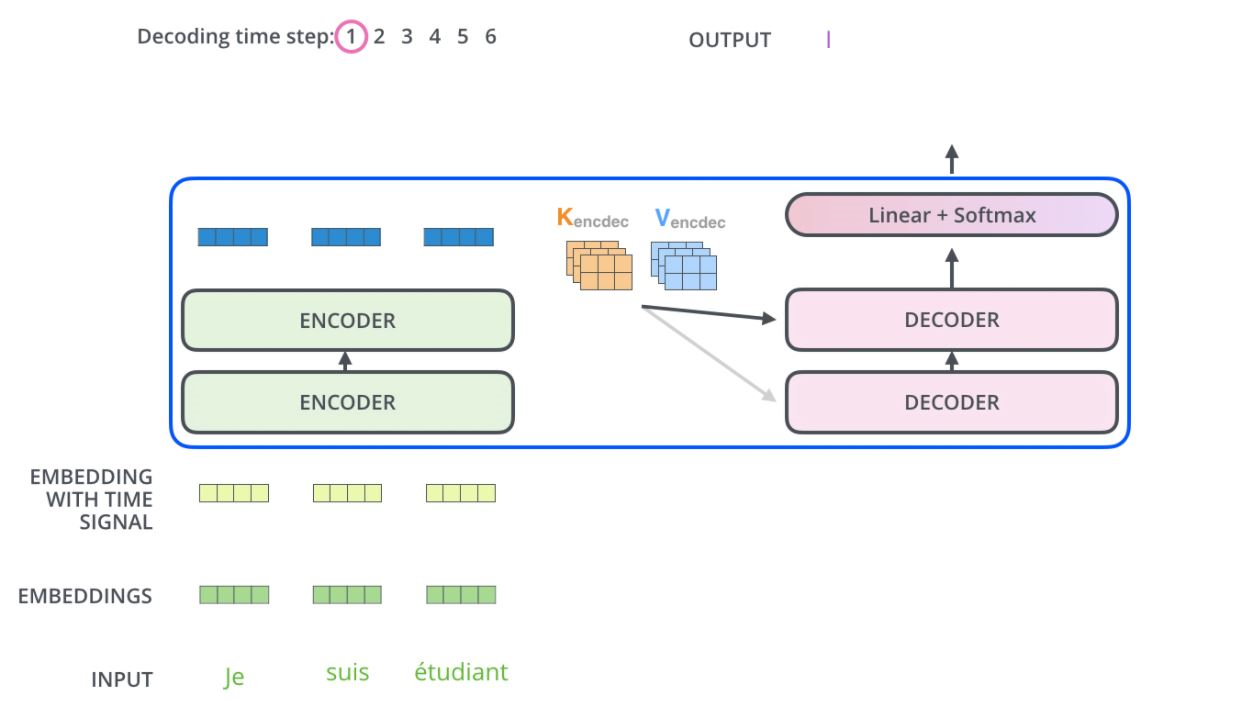
- 인코더와 다르게 하나의 sub-layer를 더 가지고 있는데 그것이 바로 ‘Encoder-Decoder Attention’ 최종 Output을 산출할 때, 인코더에서 주어지는 정보를 어떻게 반영할것인가를 결정
- Decoder가 출력을 생성할 때, 다음 출력에서 정보를 얻는 것을 방지하기 위해 masking을 사용한다. 이는 I번째 원소를 생성할 때는 $1$ ~ $I-1$번째 원소만 참조할 수 있도록 하는 것이다.
Masked Multi-head Attention
- Encoder에선 스코어값이 Input sequence 모두에 대해 나타났지만, Decoder에선 오직 전 포지션에서의 Output값만을 가져와야하기 때문에, 다른 Input sequence에 대한 어텐션 스코어값을 $-inf$ 값으로 masking해준다.
- 이 값들은 이후 softmax함수를 거치게 되면 attention-score값은 0을 가지게 될것이고, 오직 자기 자신의 score값 또는 그보다 앞에 해당하는 attention-score 값만을 사용하게 될 것이다.
- 위 과정을 아주 잘 나타낸 시각화 자료가 있는데 이는 다음과 같다.
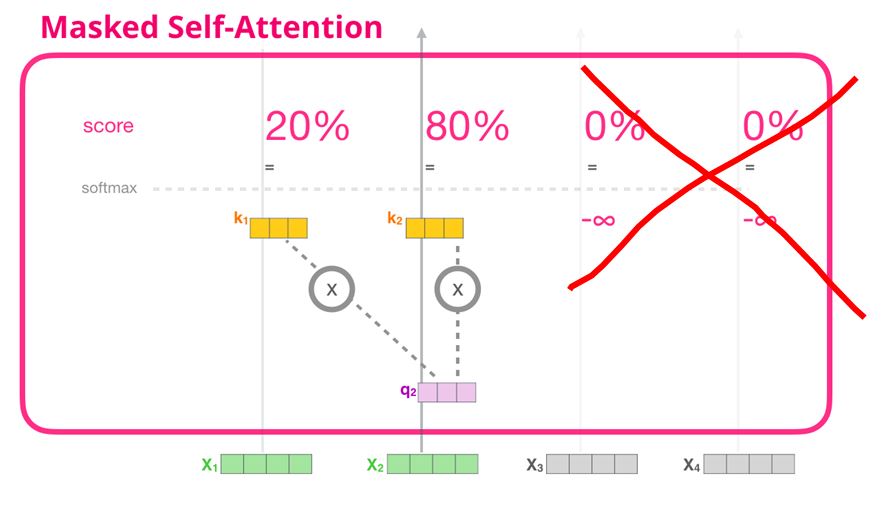


- 다시 한번 설명하자면, 자신보다 먼저 들어온 sequence에 해당하는 K, V 값만을 사용할 수 있고 그 이후의 값들은 $-inf$로 masking 처리.
Multi-head Attention
- Encoder로부터 전달받은 결과값과의 연산
-
K, V 벡터값이 Decoder와의 attention-score를 계산할 때, 영향을 준다.
- Transformer의 Attention은 총 3단계에 걸쳐 진행된다
- encoder의 self-attention
- decoder의 masked self-attention
- encoder의 output과 decoder 사이의 attention (Encoder-Decoder attention)
Final Linear and Softmax Layer
- Linear Layer : 단순한 FC Neural Network로 decoder가 마지막으로 출력한 벡터를 그보다 훨씬 더 큰 사이즈의 벡터인 logits 벡터로 투영시킨다
- Softmax Layer : Linear Layer를 거친 점수들을 확률값으로 변환해주는 역할. 가장 높은 확률값을 가지는 셀에 해당하는 단어가 Output으로 출력
- Decoder의 FFNN을 거친 값 통과 » Linear Layer에서 vocab_size만큼의 실수값 도출 » Softmax 함수를 취한 후, 최종 Output값 산출
Trnasformer 의의
- Attention 메커니즘만을 사용하는 Transformer라는 새로운 구조를 제안하였다.
- Machine Translation Task에서 매우 좋은 성능을 자랑
- 학습 시, 우수한 Parallelization 및 훨씬 더 적은 시간 소요
- 구문분석(Constituency Parsing) 분야에서도 우수한 성능 » 일반화도 잘됨
Reference
- https://wikidocs.net/31379