LLaMA - Open And Efficient Foundation Language Models [2023]
Introduction
LLM은 엄청난 양의 텍스트 데이터를 학습시켜 performance를 향상시킵니다. 그런데 최근 연구에 의하면 Scaling-laws에 반하는 연구결과가 나타나기도 하였습니다.
근데 이런 연구결과에서 inference budget은 쏙 뺀 근거를 들이미는데 이는 서비스 할때 엄청나게 큰 결함으로 작용합니다. 이번 논문에서 학습은 그다지 빠르지 않을지라도 inference는 가장 빠른 preferred model을 소개합니다. 그리고 어느 레벨에 도달하기 위한 large model을 더 저렴하게 학습할 수 있을지라도 더이상 더 작은 모델은 궁극적으로 inference시에 더 저렴할 수 없을겁니다. 예를들어 Hoffmann et al. (2022)이 10B, 200B 토큰을 가진 모델을 추천했을지라도 우리의 연구진은 7B, 1T 토큰을 가진 모델이 더 나은 성능을 내는 것을 발견하였습니다.
우리 연구진의 주 목표는 가능한 가장 최고의 성능을 달성하는 LM의 series를 학습하는 것이었습니다. 그 결의 모델을 우린 LLaMA라 부르기로 하였고 이는 7B 모델부터 65B 파라미터를 가지는 모델을 만들어냈습니다. 우리의 13B 모델은 GPT-3와 비교했을때 더 뛰어나지만 그 규모는 10배 더 작습니다. 그리고 65B 모델은 Chinchilla, PaLM-540B 모델과 견줄만합니다.
Approach
연구진의 학습 접근방법은 GPT-3, PaLM 연구진의 방법과 비슷하며 Chinchilla의 scaling-laws에서 영감을 받았습니다.
Pre-training Data
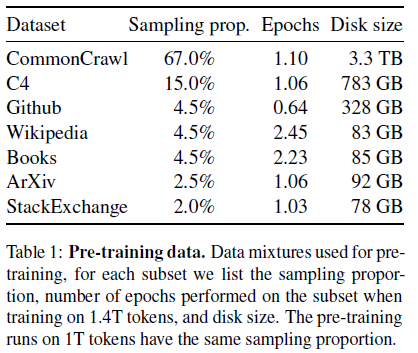
우리 연구진의 데이터셋은 몇몇의 소스의 혼합이며 다양한 도메인의 데이터셋을 사용하였습니다. 또한 다른 LLM 연구진이 사용한 데이터셋을 재사용하였으며 우린 오직 공개적으로 사용가능하며 오픈된 데이터만을 사용하였습니다.
Tokenizer
BPE알고리즘을 사용한 tokenizer를 사용하였으며 Sentencepiece로부터 implementation을 수행하였습니다. 특히, 우린 모든 숫자들을 개개인의 밑기수로 나눴으며 알수 없는 UTF-8 문자를 분해하기 위하여 bytes 단위로 fallback 하였습니다.
전반적으로 우리의 전체적인 학습 데이터셋은 tokenization한 후의 약 1.4T 토큰을 포함합니다.
Architecture
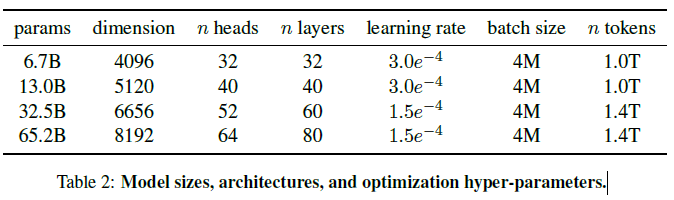
Pre-normailization(GPT3), 학습 안정성을 향상시키기 위해 output을 일반화하는 대신에 각각의 transformer sub-layer의 input을 normalize 해줬습니다. 또한 RMSNorm normalizing 함수를 사용하였습니다.
SwiGLU 활성화 함수(PaLM), 우린 성능을 향상시키기 위해 ReLU 대신에 SwiGLU 활성화 함수를 사용하였습니다. 또한 PaLM에서 사용한 $4d$ 대신에 $\frac{2}{3}4d$ 차원을 사용하였습니다.
Rotary Embeddings(GPTNeo), 우린 absolute PE를 제거하고 대신에 RoPE를 각 network의 레이어에 적용하였습니다.
Optimizer
AdamW optimizer를 사용하여 학습했으며 H-params는 $\beta_1 = 0.9$, $\beta_2 = 0.95$ 입니다. 또한 cosine learning rate schedule을 사용하였습니다. $weight_decay = 0.1$, $gradient_clipping = 1.0$, $warmup_step = 2000$, $batch_size$는 각 모델의 사이즈에 맞게 조정하였습니다.
Efficient Implementation
성능을 향상시키기 위해 한 사항은 다음과 같습니다.
첫번째, causal multi-head attention을 사용하여 학습시간과 사용되는 메모리를 줄였습니다. xformers 라이브러리를 사용하여 구현했습니다. 이를 통해 attention weight를 저장하지 않았으며 key/query score를 계산하지 않았습니다.
두번재, 더 높은 학습 효율성을 위해 checkpointing과 함께 backward pass 동안에 계산하여 활성화함수의 양을 줄였습니다. 활성화함수는 선형 레이어의 output딴에서 계산하는데 resource가 굉장히 많이 들기에 우리 연구진은 이를 save하였습니다. optimization 효과를 최대로 보기 위해 모델과 sequence parallelism을 사용하여 모델의 메모리 사용량을 줄였습니다. 게다가 activation의 계산과 network에서의 GPU들의 결합을 통해 이를 가능케 했습니다.
65B 모델 기준 2048개의 A100 머신을 통해 학습하였고 1.4T 토큰 기준으로 약 21일이 소요되었습니다.
Main results
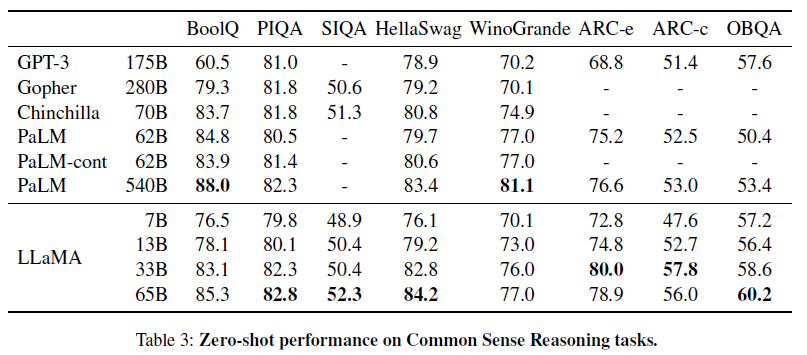
총 20개의 benchmark에서 zero-shot, few-shot 성능을 테스트하였습니다.
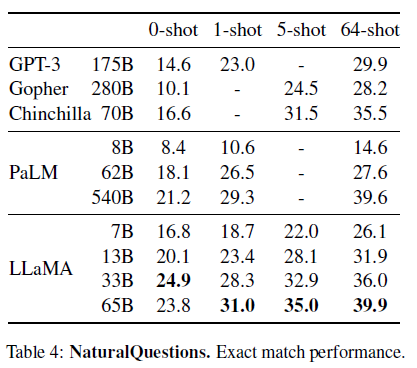
대표적으로 Common Sense Reasoning, Closed-book Question Answering, Reading Comprehension, Mathematical reasoning, Code generation, Massive Multitask Language Understanding 분야의 task에서 실험을 진행하였으며 Gopher, Chinchilla, GPT, PaLM 보다 대부분의 n-shot learning에서 SoTA를 달성하였습니다.
Evolution of performance during training
학습하는 동안, 연구진은 few-question answering과 common sense benchmark에서의 LLaMA의 성능을 추적하였고 결과는 아래와 같습니다.
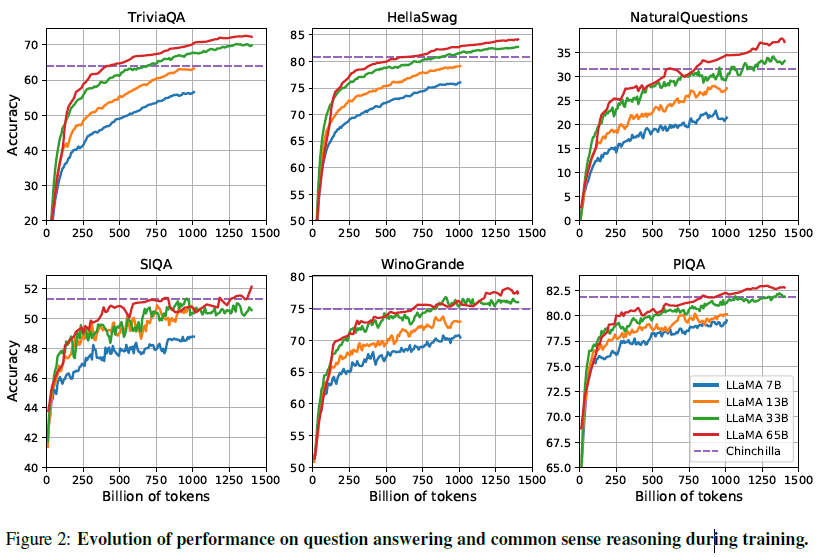
대부분의 benchmark에서 꾸준하게 성능이 향상되었고 학습 perlexity와 모델의 상관관계가 나타났습니다. SIQA와 WinoGrande는 예외였습니다. SIQA에선 성능에 있어서 많은 변수가 나타났고 아마 이 benchmark는 신뢰도가 좀 떨어져 보입니다.
Instruction Finetuning
Instruction FT를 통해 MMLU에서 급격한 성능 향상을 초래했다는 것을 밝혀냈습니다. 비록 non-finetuned model인 65B 모델은 이미 일반적인 instruction을 따르지만, 연구진은 매우 적은 양의 FT를 통해 성능 향상을 할 수 있다는 것을 밝혀냈습니다. 그리고 모델이 instruction을 따르면 더 높은 성능을 뽑아낼 수 있습니다. 이 사항은 이 논문의 맹점이 아니기에 Chung et al. (2022)에서 제시한 단일의 환경에서 실험을 진행하였고 instruc model인 LLaMA-I를 학습하였습니다.
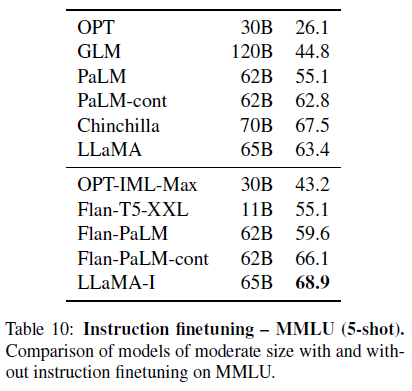
간단한 instruction FT 접근에도 불구하고 MMLU에서 우리 모델은 68.9%에 달했습니다. 현존하는 instruction FT 모델들의 보통에 scale임에도 우리 모델은 MMLU에서 뛰어난 성능을 보였습니다. 그러나 여전히 SoTA와는 거리가 멀어보입니다..
Bias, Toxicity and Misinformation
LLM들은 학습 데이터내에 존재하는 편향값들을 재생산하고 증폭시키고 toxic 또는 offensive한 content를 생산해내기 위한것으로 보입니다. 우리의 학습 데이터셋이 web으로부터 온 데이터의 큰 부분을 포함하지만 연구진은 이러한 콘텐츠를 생성할 수 있는 모델의 잠재력을 파악하는 것이 중요하다고 생각합니다. 65B 모델의 잠재적인 유해성을 이해하기위해 우리는 다른 benchmark에서 유해한 콘텐츠 생산과 고정관념 탐지를 측정하였습니다. 우리가 이전에 선택했던 다른 언어 모델이 사용한 표준의 benchmark를 사용하였습니다만 이 평가에서는 이러한 risk를 완전히 이해할 수 없습니다.
Related Work
언어 모델들은 단어, 토큰, 문자의 연속에 대한 일련의 확률 분포입니다. 종종 다음 토큰 예측값들에 대해 예측하는 task는 NLP 분야에서 고질적인 문제점이 하나 있습니다. Turing(1950)이 “imitation game”을 통해 언어를 사용하여 machine intelligence을 측정할 것을 제안한 이후, 언어 모델링은 인공지능을 향한 진전을 측정하는 벤치마크로 제안되었습니다.
Architecture Scaling
Appendix
Instruction FT하지 않은 65B로 만들어낸 생성 예시



Instruction FT한 모델 LLaMA-I로 만들어낸 생성 예시



