CoT - Chain-of-Thought Prompting Elicits Reasoning in Large Language Models [2023]
CoT
Introduction
연구를 통해 2가지의 아이디어를 사용해 언어모델의 추론능력을 향상시킬 수 있는 방법을 도출해냈다.
- 산술적 추론 기술은 자연어 생성의 이점을 누릴 수 있다. 근거를 생성하는 데 도움이 될 수 있다.
- LLM은 prompting을 통해 in-context FSL의 흥미로운 전망을 제공한다. 매 다른 task를 위한 model checkpoint (FT) 대신에 단조로운 prompt를 모델에 질의할 수 있음. 놀랍게도 단순한 QA task에서 성공적적인 실험을 거뒀음.
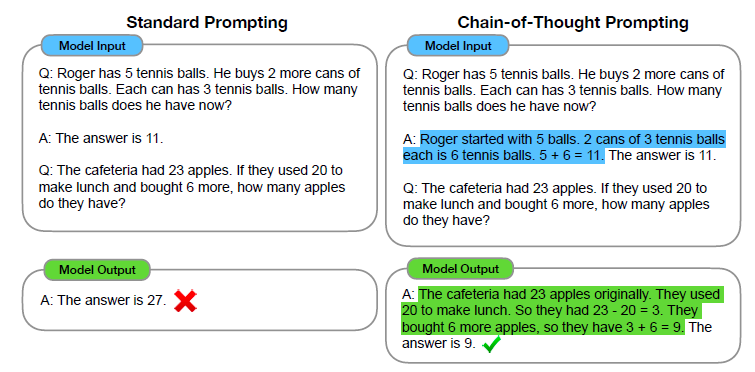
전통적인 FSL은 추론 능력에서 형편없는 결과를 내놓았고 종종 모델 scale을 늘렸음에도 불구하고 성능이 올라가지 않았음. 이에 연구진은 위의 2가지 아이디어를 통해 그들의 한계점을 타파한 해결책을 제시하고 특히 추론 능력 task에서의 Few-shot prompting 능력에 대해 발견하고 prommpt를 input, CoT, output 총 3가지 요소로 구성하였음. 위는 그 예시임.
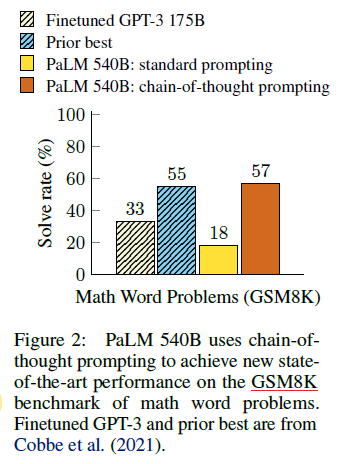
arithmetic, commonsense, symbolic reasoning 총 3개의 benchmark에서 평가하였음. GSM8K benchmark 환경에서 PaLM 540B 모델을 사용한 결과 새로운 SOTA performance를 달성하였음. 이 prompting 능력의 접근법이 중요한 이유는 새로운 큰 데이터셋과 큰 모델의 checkpoint 없이 많은 task에서 자랑할만한 성능을 뽑아줌에 있음.
Chain-of-Thought Prompting
여러 단계를 거쳐야하는 수학 문제와 같은 복잡한 추론을 통해 문제를 푸는 절차를 연구진은 고려하였음. 이건 전형적인 문제를 하나하나 분해하여 정답에 접근하는 방식임. 이 논문의 목표는 LLM에 유사한 CoT를 생성할 수 있는 기능을 부여하는 것입니다. 일관된 일련의 중간 추론 단계를 생성할 수 있는 능력을 LLM에 부여하는 것입니다.
CoT 능력은 다음과 같은 이점이 존재합니다.
- CoT는 LLM이 문제에 대해 여러 스텝을 통해 분해할 수 있게 합니다. 이는 더 많은 스텝을 요하는 문제에 대해 추가적인 연산을 가능케 합니다.
- CoT는 모델에 설명가능한 window를 제공해줍니다.
- CoT는 많은 수학 문제, commonsense 추론문제, symbolic manipluation 그리고 잠재적으로 적용가능한 언어로된 모든 task에서 사용되어 질 수 있습니다.
- 마지막으로 CoT 추론은 단순한 CoT 문장의 예시를 추가해줌으로써 모델을 매우 효율적으로 동작하게 해줍니다.
Arithmetic Reasoning
Arithmetic reasoning에서 CoT prompting을 사용한 결과 540B의 파라미터를 가진 모델에서 몇몇의 다른 task-specific 파인튜닝한 모델과 견줄만한 성능을 뽑아냈고 심지어 GSM8K benchmark에선 SOTA를 달성하였음.

Experimental Setup
GPT와 LaMDA, PaLM UL2 20B 등 다양한 모델, 다양한 파라미터를 가진 모델을 사용해 실험하였음. greedy decoding을 통해 모델로 부터 sample을 추출해냈음.
Results
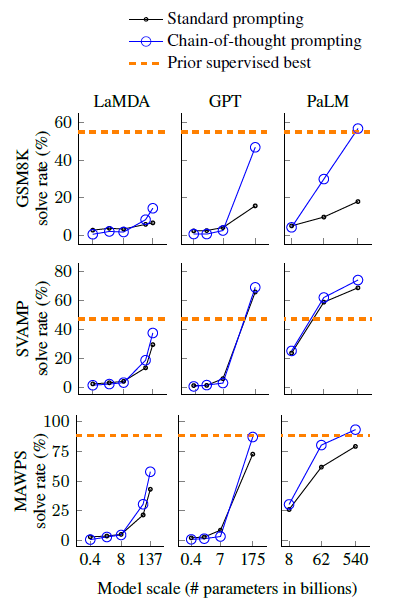
CoT prompting은 모델 규모의 새로운 능력을 초래하였음. 즉, 모델 파라미터 수의 증가가 긍정적인 영향으로 나타났고 주로 100B 이상의 모델에서 두드러지는 효과가 나타났음. 더 낮은 파라미터 수를 가진 모델은 더 낮은 성능이 나타났음.
CoT prompting은 더 복잡한 문제에 대해선 더 큰 성능을 뽑아냈음. 예를들어 GSM8K benchmark에서 기존엔 제일 낮은 performance를 뽑아냈으나 GPT나 PaLM모델에서 2배 이상의 performance를 뽑아냈음. 반면에 SingleOp나 쉬운 문제를 가진 MAWPS benchmark에서의 performance는 미미했고 심지어 성능이 더 저하되는 경우도 존재했음.
GPT-3 175B, PaLM 540B를 통한 CoT prompting은 전형적으로 task-specific finetuning한 모델인 이전 SOTA 모델들과 견주었음. figure4에 CoT를 사용한 PaLM 540B 모델이 GSM8K, SVAMP, MAWPS benchmark에서 새로운 SOTA를 달성했음을 알 수 있음.

CoT가 작동하는 이유를 더 잘 이해하기 위해 prompt가 작동하는 이유를 이해하기 위해, 우리는 수동으로 LaMDA 137B 모델에서 생성된 모델 생성 CoT에 의해 생성된 CoT을 직접 조사했습니다. 50개의 랜덤한 모델이 추출해낸 올바른 예시에서 단 2개지를 제외하고 논리적, 수학적으로 옳은 대답에 접근할 수 있었음. 또한 모델에게 50개의 틀린 예시를 주었고, 46%에 달하는 예시에 대해서는 맞췄고, 나머지 54%는 의미이해나 일관성에 대해 오류가 있었음.
Ablation Study
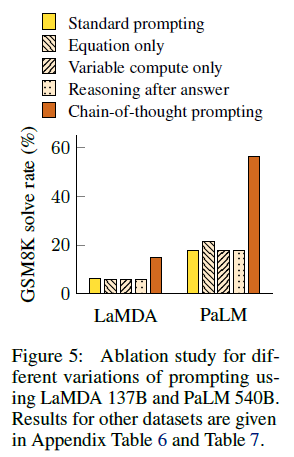
Equation Only
CoT가 오직 방정식을 포함한 수학문제에서도 유의미한 능력을 이끌어 낼 수 있을것으로 생각되어 모델에 답을 주기 전에 몇몇의 다양한 상황을 통해 테스트하였음. Figure 5에 나왔듯이 GSM8K에선 방정식만을 사용한 방법으론 큰 performance나 나타나지 않았음. 그러나 one-step 또는 two-step 문제를 가진 데이터셋에선 방정식만을 사용하는 prompting이 performance 향상을 야기한다는 것을 밝혀냈고 그 이유는 방정식은 질문에서 쉽게 논리를 도출하기 때문임.
Variable compute only
변수 계산의 효과를 변수 계산의 효과를 분리하기 위해, 우리는 모델에 입력된 문자 수와 동일한 점(: : :)의 문제 해결에 필요한 방정식의 문자 수와 동일한 점(: : :)의 시퀀스만 의 문자 수와 동일한 점(: : :)만 출력하라는 메시지를 표시하는 구성을 테스트합니다. 이 변형의 성능은 기준선과 거의 동일하게 수행되며, 이는 변수의 계산 자체가 CoT prompting의 성공 이유가 아니며 자연어를 통해 중간 단계를 표현하는 것에서 유용성이 있는 것으로 보입니다.
Robustness of CoT
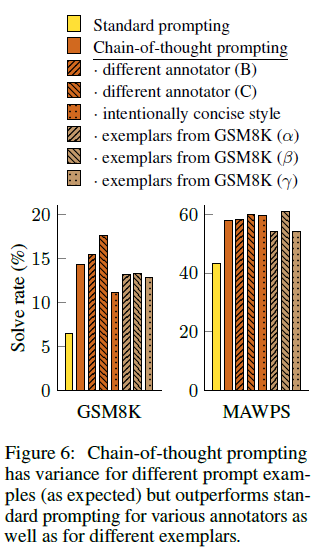
비록 CoT annotation사이에 다른 변수가 존재하지만 exemplar 기반의 prompting을 사용할때 표준 prompt와 비교했을때 많은 차이가 있음을 나타났음. 이 결과는 CoT prompt가 특정한 언어 스타일에 의존하지 않고 성공한 예로 매우 의미있음.
Commonsense Reasoning
비록 CoT가 문자를 통해 수학문제를 푸는 방식에 더 적합할 수 있으나 언어 기반의 CoT는 사실 commonsense reasoning 문제에 대해 잘 적용할 수 있게 만들 수 있음. commonsense reasoning은 세상과 상호작용하는 열쇠이며 여전히 현재 자연어 이해 시스템의 범위를 벗어나지 못함.
Prompts
이전 섹션에서 나타난 setup 환경과 동일하게 진행하였음. CSQA, StrategyQa benchmark에서 무작위하게 샘플을 선택하여 few-shot exemplar를 사용해 CoT에 직접 연결하였음. 두 개의 빅벤치 작업에는 훈련 세트가 없으므로 다음과 같이 선택했습니다. 처음 10개의 예제를 평가 세트의 예제로 선정하고 나머지 평가 세트에 대한 보고서 번호는 few-shot 예제로 선정했습니다. SayCan에서 트레이닝 셋에서 6개의 예제를 사용하였고 또한 직접 CoT에 연결해주었음.
Results
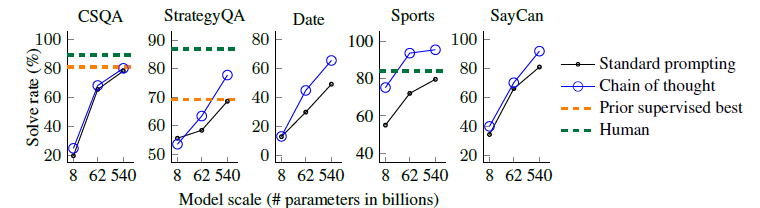
모델 규모를 늘린 test에선 standard prompting보단 모든 경우에서 performance가 향상되었음. CoT prompting을 사용한 PaLM 540B 모델에선 baseline보다 월등한 성능을 보였고 StrategyQA benchmark에선 이전 SOTA 모델보다 높은 능력을 보였음. 또한 스포츠 이해도에 대해서 비전문가보다 더 높은 이해도를 보였음.
Symbolic Reasoning
Symbolic Reasoning은 인간에겐 매우 간단한 문제일 수 있으나 잠재적으로 언어모델에겐 굉장히 어려운 문제임. 연구진은 CoT prompting이 해당 task에서 언어 모델이 기존의 prompting setting과의 비교 뿐만 아니라 few-shot 예제보다 inference-time에 유리하게 해주는 input길이에 대해 테스트하였음.
Results
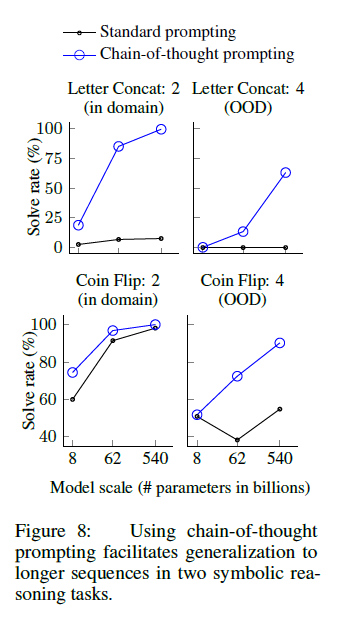
마지막 단어 연결, 코인 Flip 총 2가지 task에서 In-domain, Out-of-Domain(OOD)으로 진행한 결과, PaLM 540B 모델에서 거의 100%에 달하는 능력을 나타냈음.
OOD 평가에서 standard prompting은 2가지 task에선 모두 실패하였음. CoT prompting을 사용한 결과 언어모델은 규모에 따라 급격한 curve를 그렸음(성능향상). 따라서 CoT prompting는 충분한 규모의 언어 모델에 대해 보이는 CoT를 넘어선 길이 generalization를 촉진합니다.
Conclusions
CoT prompting은 간단하고 폭넓게 논리를 강화하여 언어모델에서 사용할 수 있음. 3가지 실험 케이스를 통해 CoT prompting이 모델 규모의 적절한 크기에 따라 효율적인 효과를 냄을 밝혀냈음.