EDA - Easy Data Augmentation Techniques for Boosting Performance on Text Classification Tasks [2019]
Introduction
- 그간 NLP 분야에서 많은 진보가 이루어 졌지만 data-augmentation에 대한 research는 vision이나 speech field에 비해 미미하였음.
- 그나마 data-augmentation에 대한 가장 보편이거나 잘 알려진 방법으론 back-translation, nosing as smoothing, 동의어 대체를 통한 predictive LM 등이 있다. 이러한 방법론이 존재하지만 이는 모두 구현에 있어서 비용이 많이 드는 단점이 있다.
- 때문에 이번 연구에서는 universal data에 대한 매우 쉬운 data-augmentation 방법론을 제시하고 이를 EDA (easy data augmentation)이라고 명명한다.
EDA
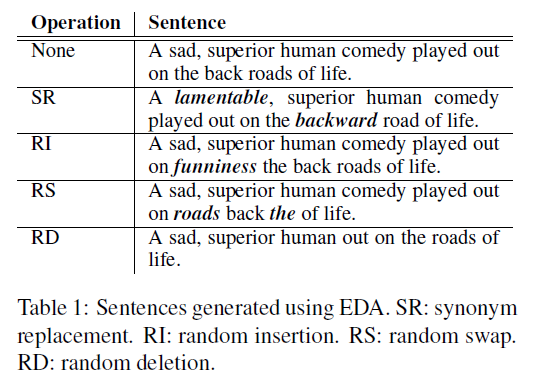
- Synonym Replacement (SR) : 불용어를 제외한 문장 내 단어를 $n$개 만큼 동의어로 대체
- Random Insertion (RI) : 불용어를 제외한 문장 내 동의어를 삽입. 이를 $n$번 만큼 반복
- Random Swap (RS) : 문장 내 무작위한 단어 2개의 위치를 바꿈. 이를 $n$번 만큼 반복
- Random Deletion (RD) : 문장 내 무작위하게 각 단어를 제거
- 문장이 긴 경우 작은경우보다 많은 단얼를 내포하고 있기에 본래의 label을 유지하면서 더 많은 noise를 받아들일 수 있다. 연구진은 단어를 바꾸는 횟수를 다양하하기 위해 SR, RI, RS 방법론에서 문장의 길이를 $l$라 할때, $n=al$라는 식을 적용하였다. $a$는 문장 내 단어가 바뀐 percentage를 의미합니다.
Experimental
Benchmark Dataset
- SST-2, CR, SUBJ, TREC, PC benchmarking
- EDA는 적은 데이터셋에서 효과적이라는 가설을 세웠고 전체 데이터셋 중, $N_{train} = {500, 2000, 5000}$ 만큼 sampling 진행
Text Classification Models
- LSTM-RNN 모델, CNN 계열 모델을 사용하였음
Results
EDA Makes Gains
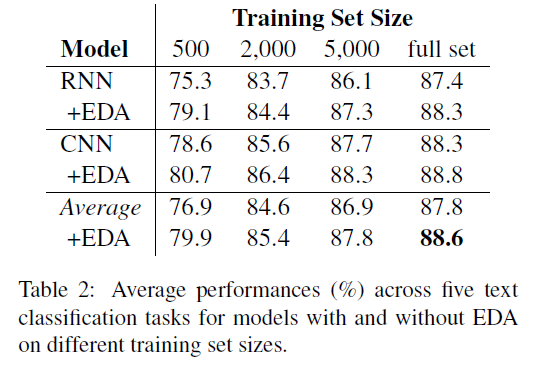
- 역시 모든 모델에서 성능 향상이 있었고 가설대로 적은 데이터셋에서 더 강력한 성능을 자랑
Training Set Sizing
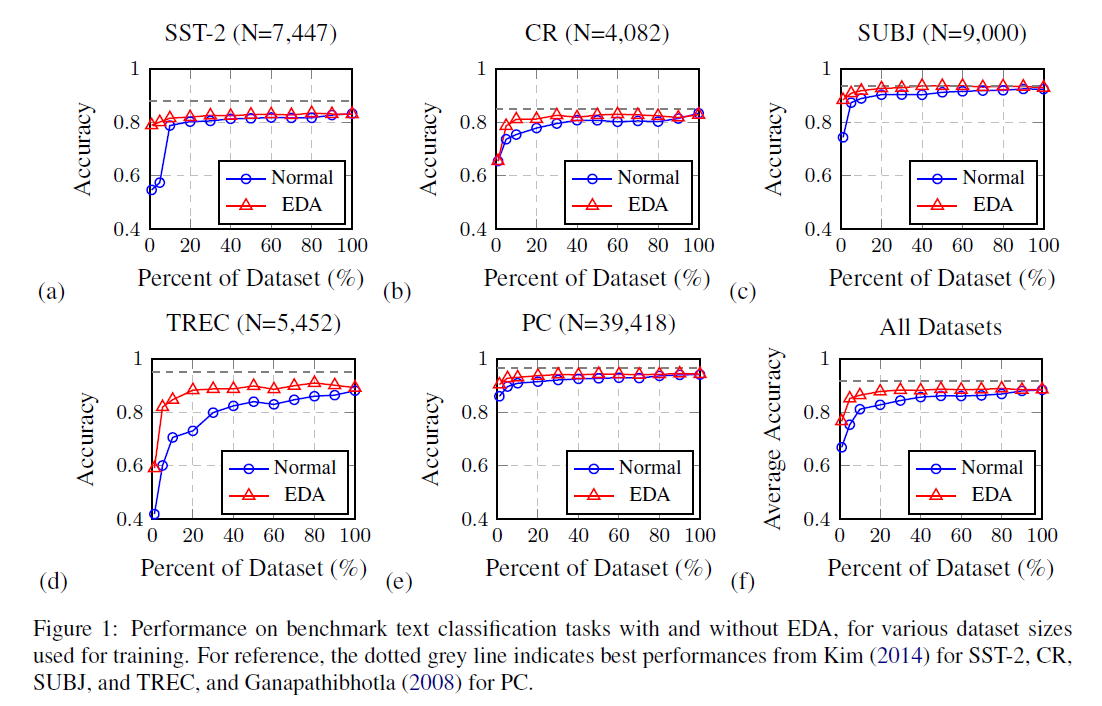
- 과적합문제는 적은 데이터셋에서 학습할때 더 심각해지는 경향이 존재. 제한된 데이터셋 사이즈에서 실험을 진행함으로써 EDA가 적은 학습 데이터셋에서 더 강력한 성능 향상이 있음을 증명. 이에 학습 셋 fracition(%)을 {1, 5, 10, 20, 30, 40, 50, 60, 70, 80, 90, 100}으로 세팅한 후 실험 진행.
Does EDA conserve true lables?

- Data-augmentation으로 인해 label자체가 유지되어야 하지만 만약 데이터의 큰 변화로 인해 본래의 class label의 변화가 있다면 해당 방법론은 유효해선 안된다. 때문에 다음의 순서를 가지는 실험을 진행하였음
- 첫째, RNN모델을 pro-con(PC) classification task에서 augmentation없이 학습 진행
- 그 후, 테스트셋에 EDA를 적용하여 1개의 문장당 9개의 augmentated-sentence를 생성. 이는 원 문장과 함께 RNN에 공급되고 마지막 dense layer에서 output을 추출
- t-SNE를 적용해 figure2를 visualization
- 위 시각화하는 과정을 통해 증강된 문장이 원 문장의 label에 아주 면밀히 연관되어 있음을 밝혀 냈고 이는 EDA 방법론이 원 문장의 label을 오염시키지 않음을 밝혀냈음
Ablation Study - EDA Decomposed
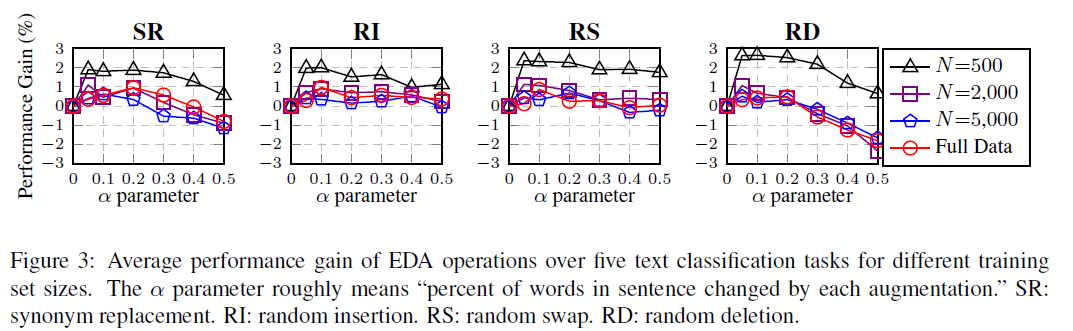
- EDA의 각 방법론에 대한 Ablation Study를 진행하였고 SR은 이전 연구에서 다뤄진 적이 있으나 나머지 3개는 EDA에서 최초로 제시하는 방법론이기에 다음과 같은 가설을 세웠음
EDA 성능 향상의 대부분은 동의어 대체로 인한 것이라고 가정할 수 있고 각각의 EDA 작업을 분리해 성능을 향상시키는 개별적인 기능을 파악
- 4개의 operation을 위해 연구진은 augmentation parameter $a$ 값을 tweak($a={0.05, 0.1, 0.2, 0.3, 0.4, 0.5}$) 하여 단일의 operation을 사용하는 ablation study를 진행하였음
- 4개의 operation가 모두 성능 향상을 가져왔고 특히 RS 방법론은 $a$ 값이 0.2 보다 적게 주어졌을때 큰 성능 향상을 이끌어냈고 0.3 이상 일땐 향상이 미미했음. 문장 내에서 너무 많은 단어가 swap되면 전체 문장을 섞어 버리는 것과 동일하기 때문.
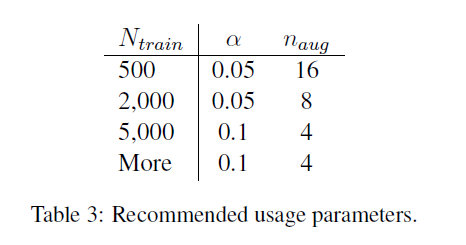
How much Augmentation?

- 문장당 생성된 증강 문장의 수($n_{aug}$)를 결정하는 실험을 진행했고 모든 데이터셋에 대해 다음과 같은 파라미터를 적용하였음. $n_{aug} = {1, 2, 4, 8, 16, 32}$
- 적은 데이터셋이 과적합을 더 유발하기 쉽기에 생성된 많은 augmentated-sentences는 큰 성능 향상을 야기하였음. 큰 비율의 데이터셋에선 기존 1개의 문장당 4개의 augmentated-sentences를 추가하였고 이는 성능 향상에 큰 도움이 되지 않았음. 왜냐하면 모델은 큰 양의 데이터를 사용할 땐 적절하게 generalize하려는 경향이 있기 때문.
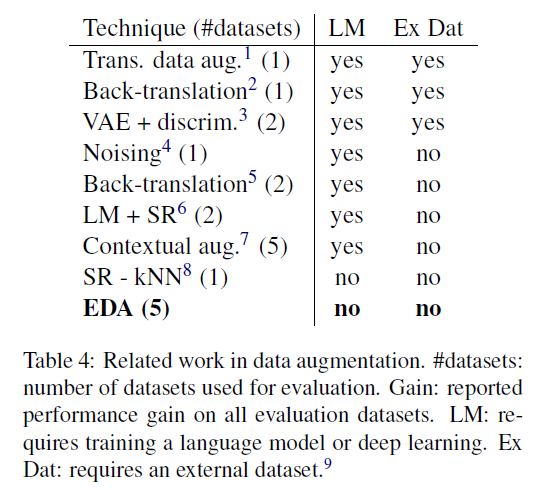
Comparison with Related Work
- 여러 data-augmentation 기법에 대해 설명. 요지는 그간의 증강 방법론은 모델 output을 사용하는것과 같은 형태로 real-data에 적용하기 어려웠으나 EDA는 real-data에 쉽게 적용 가능한 방법론이라는 주장
Discussion and Limitations
- 그간 NLP 분야에서 model-centric한 research가 주로 이루어졌으나 본 연구진은 정 반대의 입장을 취하고 있음. 간단하게 근본적인 질문의 결과를 내기 위해 되물었다. tru label의 변화 없이 문장의 augmentation을 어떻게 수행 할 수 있을까?.
- 쉽게 적용하고 task-specific 데이터 증강이나 universal한 새로운 접근임에도 불구하고 한계점이 존재한다. 데이터셋이 많을 때 성능 향상이 미미할 수 있다. 4개의 full-dataset을 사용하여 classification task에서 실험을 진행했을때 1% 내외의 성능 향상만 나타났고 실제로 적은 데이터셋에서 진행했을 때 성능 향상이 확실하게 나타났다. 또한 EDA는 사전학습된 모델을 사용할 땐 대단한 성능 향상이 일어나지 않는다. 실제로 ELMo나 ULMFit, BERT 모델을 사용했을 때 성능 향상이 매우 적다.
Appendix
Theory
How does using EDA Improve Text classification performacne?
- 첫째, 증강된 데이터가 원본 데이터에 대한 noise를 생성함으로써 overfitting을 방지하는 것을 도왔다.
- 둘째, 테스트 데이터셋을 제외하고 SR, RI operation을 통해 새로운 단어를 모델에 제공함으로써 단어 자체를 일반화 시켰다.
It doesn’t intuitively make sense to make random swaps, insertions, or deletions. How can this possibly make sense?
- 단일의 문장 내에서 2개의 단어를 바꿈으로 인해 아마도 증강된 문장을 생성해내고 이는 인간이 보기엔 말이 되지 않을지 몰라도 original words와 몇몇의 추가된 noise화 함꼐 위치 정보를 얻을 수 있었을 것임. 이를 통해 overfitting을 방지하는 데 큰 도움을 줬을 것.
For random insertions, why do you only insert words that are synonyms, as opposed to inserting any random words?
- Data-Augmentation-operations은 기존 문장의 label을 변경하지 않음. 문장 내 단어의 동의어를 삽입하는 것은 context에 연관있으며 문장의 original-label을 유지시킴