LoRA - Low-Rank Adaptation of Large Language Models [2021]
Introduction
많은 자연어 처리 산업에서 단일의 큰 규모의 모델과 다양한 downstream task에 사전학습된 언어모델에 의존하고 있음. Finetuning 같은 방식을 통해 모든 사전학습 모델의 파라미터를 업데이트하여 적용 시키고 있음. Finetuning의 요지는 수많은 파라미터들을 새로운 모델에 포함시켜 주는 것. 큰 모델일수록 학습시간도 방대해지고 산업에 적용시키기 매우 불편함.
많은 사람들이 일부 매개 변수만 적용하거나 새로운 task를 위해 외부 모듈을 학습하여 이를 완화하려고 했음. 이렇게되면 task-specific한 파라미터의 숫자는 적게 저장되고 불러와짐. 이러한 방법은 Finetuning을 실패하거나 효율성과 모델 품질의 trade-off관계에서 벗어나지 못하였음.
학습된 과도하게 매개변수화된 모델이 실제로 낮은 performance를 낸다는 연구결과에 영감을 받음. 낮은 intrinsic rank를 모델을 적용하는동안 weights가 바뀐다는 가설을 세움. LoRA는 간접적으로 dense layer의 rank decomposition matrix를 최적화함으로써 NN에서 몇몇의 dense layer들을 학습할 수 있게 만들어줌(이 과정에서 weight는 froze).
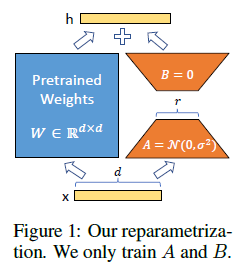
Key Points.
-
공유된 모델을 freeze하고 matrices A와 B을 대체함으로써 효율적으로 task들을 바꿔줌. 이를 통해 필요 저장공간을 줄여줄 수 있음.
-
LoRA는 트레이닝 과정을 더 효율적으로 만들어주고 더 낮은 HW를 사용하게 만들어줌. gradients를 계산할 필요가 없으며 most 파라미터를 통해 optimizer state를 유지시켜줌.
-
단순한 선형적 디자인을 통해 deploy때 frozen weight와 함께 학습가능한 matrices를 통합할 수 있게 해줌.
Problem Statement
Fine-tuning의 drawback은 각각의 downstream-task마다 다른 파라미터를 학습시켜주는 것임. 따라서 모델의 parameter scale이 커질수록 storing과 deploying에 있어서 memory가 challenging하게 될 것!
이에 연구진은 더 높은 효율의 파라미터 접근 방식을 적용하였는데 task-specific parameter increment를 더 적은 규모의 파라미터들로부터 인코드시키는 것.
Aren’t Existing Solutions Good Enough?
이전연구에서 adapter layer들을 추가하는 방법과 input layer 딴에서의 활성화함수의 형태를 최적화해주는 방식들과 같이 효율적인 방법을 고안해냈으나 모델의 규모나 latency-sensitive와 같은 한계점에 봉착하였음.
Adapter Layers Intorduce Inference Latency
이에 연구진은 original design(Parameter-Efficient Transfer Learning for NLP)에 집중하여 각각의 Transformer block에서 2개의 adapter layers와 각 block에서 추가적인 LayerNorm 방법을 만들어냄. 레이어를 pruning, multi-task 셋팅을 이용함으로써 전반적인 latency를 줄일 수 있었음. 실험결과, Single-GPU를 통해 GPT-2 모델 학습할 수 있었음.
Directly Optimizing the Prompt is Hard
prefix tuning방식은 최적화하기 어렵다는 걸 발견해냄. 특정 방법을 통해 prompt를 튜닝한 downstream-task를 제공하기 위해선 sequence_length를 필수적으로 줄여줘야함. 즉 최적화가 힘들다!
Our Method
LoRA는 어떤 딥러닝 모델의 dense layer에서 다 적용 가능함.
Low-Rank Parameterized update Matrices
specific한 task에 적용시킬때 사전학습된 언어모델이 낮은 instrisic dimension을 가지고 있음을 밝혀냈고 적은 공간에 무작위로 투영시킴에도 불구하고 여전히 효율적으로 학습시킬 수 있음.
random Guassian initialization 방식을 사용하여 학습 시작시에 zero로 셋팅. 결과적으로 이러한 scale 과정을 통해 하이퍼파라미터를 재학습시킬 필요를 줄여줌.
LoRA는 단계적으로 step를 밟으며 gradient update 과정이 필요없음. 이는 LoRA를 모든 가중치 행렬에 적용하고 모든 편향을 훈련시킬 때 LoRA rank를 사전 훈련된 가중치 행렬의 순위로 설정하여 전체 미세 조정의 표현력을 대략적으로 복구한다는 것을 의미합니다. 반면에, 학습가능한 파라미터의 수가 늘어날때 학습하는 LoRA는 기존 모델을 roughly 연산함.
또한 inference과정에서 추가적은 latency가 필요없음.
Applying LoRA to Transformer
연구진은 downstream-task를 위한 attention weight를 적용하는 것에만 주제를 국한시켰습니다. 이는 구조의 단순함과 파라미터의 효율성 때문입니다. 다른 방식을 통해 attention weight matrices를 Transformer안에서 적용할때의 효과에 대해서는 WHICH WEIGHT MATRICES IN TRANSFORMER SHOULD WE APPLY LORA TO? 라인에 나타나 있습니다.
LoRA의 가장 큰 이점은 메모리와 저장소 가용성에 대한 이점이라 할 수 있겠습니다. 사용자가 만들어낸 많은 모델들을 넣었다 빼면서 VRAM안에 사전학습된 가중치를 저장할 수 있게합니다. GPT-3 175B 기준 학습시간이 약 25% 증가한다는 걸 밝혀냈으나 full fine-tuning과 비교했을때 gradient를 측정할 수 없었습니다.
LoRA는 또한 한계점을 지닙니다. 예륻 들자면, 추가 추론 대기 시간을 제거하기 위해 A와 B를 W로 흡수하기로 선택한 경우, 단일 전진 패스에서 다른 A와 B를 가진 다른 작업에 대한 일괄 입력이 간단하지 않습니다. 비록 가중치를 통합하거나 급격하게 LoRA모듈을 scenario를 위한 batch를 샘플속에서 사용하기위한 선택을 할 수 없지만 latency는 꽤나 이점으로 다가옵니다.
Empirical Experiments
연구진은 RoBERTa, DeBERTa, GPT-2의 downstream task performance를 평가하였습니다. 자연어 처리의 다양한 분야의 task에서 실험을 진행하였습니다. 특히 RoBERTa, DeBERTa 모델을 위해 GLUE benchmark dataset을 통해 성능평가를 진행하였습니다. GPU는 Tesla V100을 통해 진행하였음
Baselines
Finetuning 동안 모델은 사전학습된 모델의 가중치와 bias를 초기화하고 모든 모델 파라미터들은 기울이 업데이트가 진행된다. 다양한 변수는 다른 레이어들은 freeze되는 반면에 오직 몇몇의 레이어에서만 업데이트가 된다. 연구진은 1개의 baseline뿐만 아니라 마지막 2개의 레이어들을 적용 시켰습니다.
Bias-only or BitFit
Prefix-embedding tuning (PreEmbed)는 입력 토큰 사이에 special 토큰을 삽입합니다. 이 토큰은 단어 임베딩을 학습 가능케 하며 일반적으로 모델의 단어 안에 존재하지 않습니다. 이러한 토큰을 어디에 배치하느냐에 따라 성능에 영향을 미칠 수 있습니다. 연구진은 prompt 앞단에 토큰을 붙이는 prefixing과 prompt를 추가하는 infixing에 집중하였습니다.
Prefix-layer tuning (PreLayer)는 prefix-embedding tuning의 확장 기능입니다. 몇몇의 speicla-tokens을 통해 단어 임베딩을 학습하는 대신에 연구진은 모든 Transformer 레이어 이후에 활성화 함수를 학습하였습니다. 활성화함수들은 단순하게 학습가능하게 만들어진 이전 레이어들로부터 계산하였습니다.
Adapter tuning은 self-attention 모듈과 후속 residual-connection 사이에 삽입된 adapter-layer입니다. Adapter-layer에 bias가 있는 2개의 FCL이 있으며 그 사이에 비선형성이 있습니다.
LoRA는 학습가능한 rank decomosition matrices의 쌍을 추가합니다. 훈련 가능한 파라미터의 수는 rank r과 원래 가중치의 모양에 따라 결정됩니다