Polyglot-ko 모델 파인튜닝
Polyglot 파인튜닝 데이터 형식 이슈
Envs
- python3.10.6
- ubuntu 22.04
- pytorch 2.0.1+cu118
- transformers 4.28.1
- deepspeed 0.9.2
Prob
-
KoAlpaca Github의 📰데이터를 사용했으나 학습이 5분만에 끝나버림..
-
KoAlpaca 레포에 있는 파일을 그대로 가져다가 썼기 때문에 sh 파일의 명령어 문제는 아닐거라 생각함
-
그럼 남은건 데이터 뿐.. train 파일의 데이터 처리 부분 코드를 뜯어보기로!
Solution
train.py의 데이터 불러오고 tokenize하는 부분
# Preprocessing the datasets.
# First we tokenize all the texts.
if training_args.do_train:
column_names = list(raw_datasets["train"].features)
else:
column_names = list(raw_datasets["validation"].features)
text_column_name = "text" if "text" in column_names else column_names[0]
# since this will be pickled to avoid _LazyModule error in Hasher force logger loading before tokenize_function
tok_logger = transformers.utils.logging.get_logger("transformers.tokenization_utils_base")
def tokenize_function(examples):
with CaptureLogger(tok_logger) as cl:
output = tokenizer(examples[text_column_name])
# clm input could be much much longer than block_size
if "Token indices sequence length is longer than the" in cl.out:
tok_logger.warning(
"^^^^^^^^^^^^^^^^ Please ignore the warning above - this long input will be chunked into smaller bits"
" before being passed to the model."
)
return output
-
tokenize_function의 examples[text_column_name] 데이터를 받아 tokenize하는데.. 윗 부분 코드에서text_column_name은 첫번째 column_name만 받네? -
최초 내가 구성했던 데이터 형식은 다음과 같았음
{"instruction":"~~~~","output":"~~~~~"}
-
위 데이터의 형식으로 돌리면 데이터의 instruction만을 가져와 학습을 돌리는 것..
-
수정 후 데이터 형식
{"text": "### 명령어: 삶의 의미가 뭘까?\n\n### 결과: 삶의 의미는 개인에 따라 다를 수 있으며, 각각의 개인이 그 의미를 발견하고 경험하는 과정입니다."}
- nohup.out
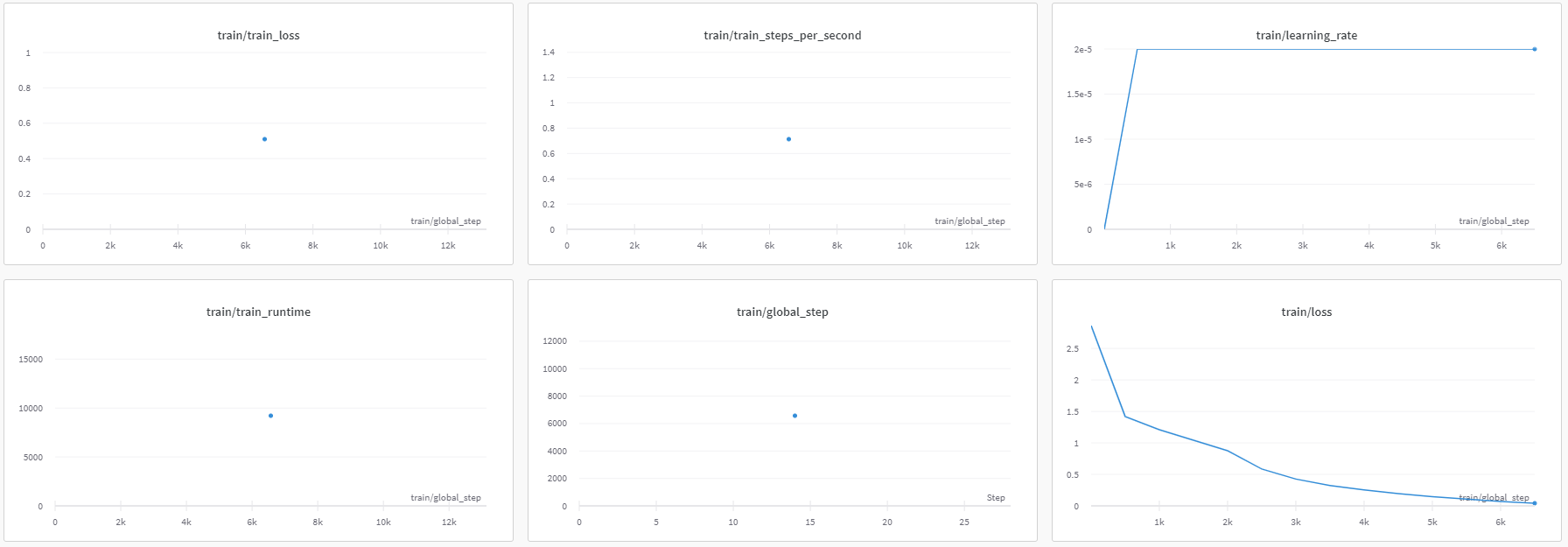
- wandb: train/loss 0.0417
- wandb: train/total_flos 103825281122304.0
- wandb: train/train_loss 0.51006
- wandb: train/train_runtime 9215.9184
- wandb: train/train_samples_per_second 2.852
- wandb: train/train_steps_per_second 0.713
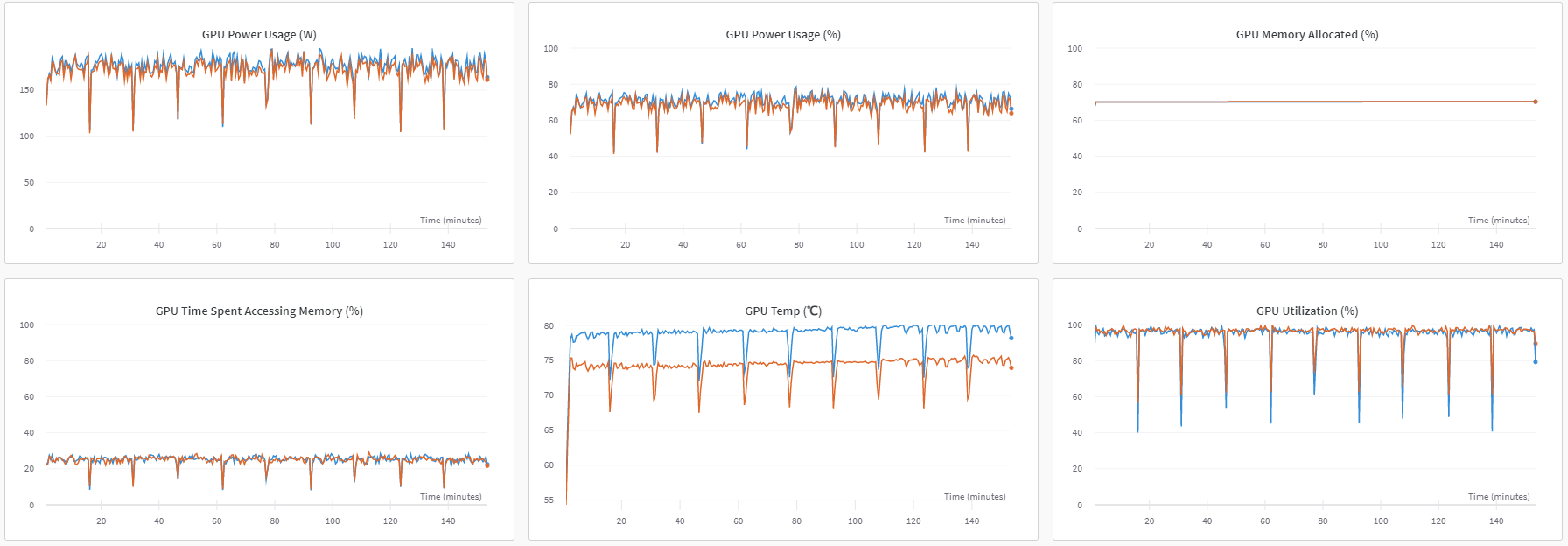
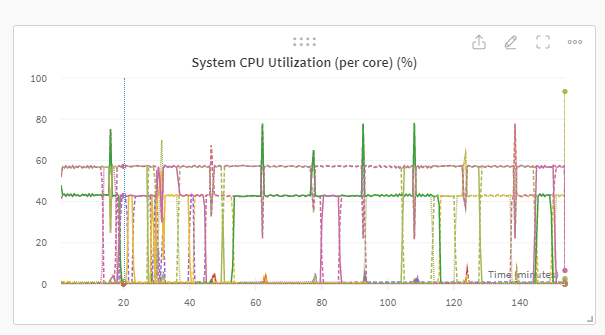
- step 잘 밟고 GPU 2장 모두 잘 사용하며 ZeRO3 Offload로 rest of CPU-mem 잘 사용되었음을 확인 할 수 있었음