The idea you need to understand about the Object Detection Model
Backbone
Detection, Segmentation, Pose Estimation, Depth Estimation 등에서 일명 “Backbone”으로 사용된다
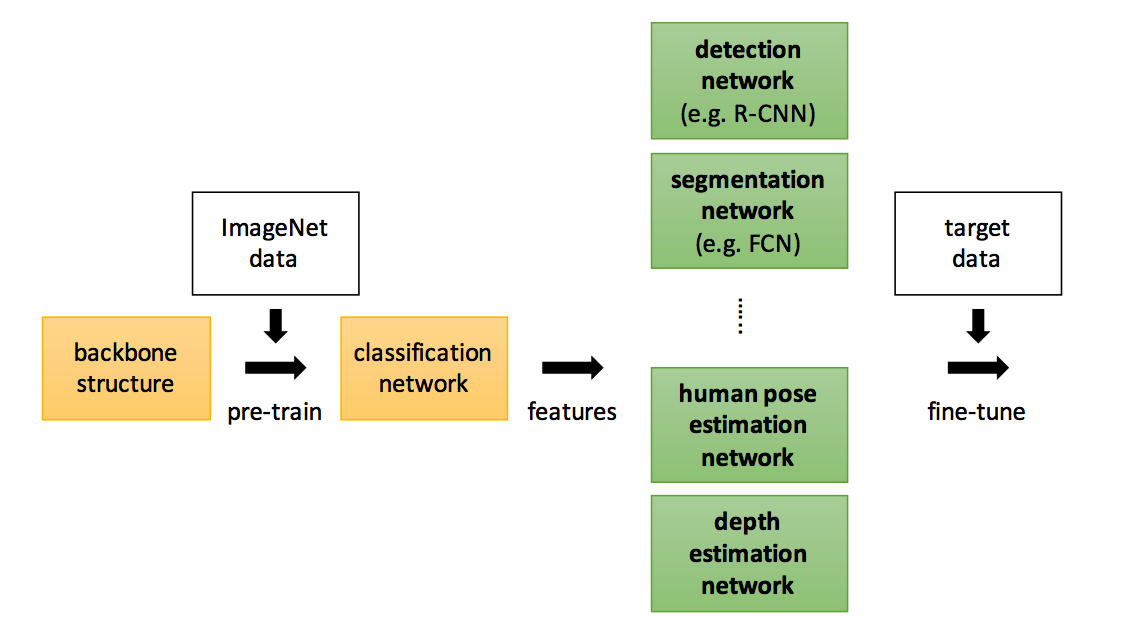
Backbone은 등뼈라는 뜻이다. 등뼈는 뇌와 몸의 각 부위의 신경을 이어주는 역할을 한다. 뇌를 통해 입력이 드러온다고 생각하고 팔, 다리 등이 출력이라고 생각한다면 backbone은 입력이 처음 들어와서 출력에 관련된 모듈에 처리된 입력을 보내주는 역할이라고 생각할 수 있다. 여러가지 task가 몸의 각 부분이라고 생각하면 Classification Model은 입력을 받아서 각 task에 맞는 모듈로 전달해주는 역할이다. 결국 객체를 검출하든 영역을 나누든 Neural Network는 입력 이미지로부터 다양한 feature를 추출해야한다. 그 역할을 Backbone Network가 하는 것이다.
Region Proposal (물체가 있을 법한 위치 찾기)
정의
**주어진 이미지에서 물체가 있을법한 위치를 찾는 것**종류
-
Selective Search
R-CNN은 Selective Search라는 툴 베이스 알고리즘을 적용해 2000개의 물체가 있을법한 박스를 찾는다.
Selective Search는 주변 픽셀 간의 유사도를 기준으로 Segmentation을 만들고, 이를 기준으로 물체가 있을법한 박스를 추론한다.
하지만 R-CNN 이후 Region Proposal 과정 역시 Neural Network가 수행하도록 발전하였다. -
Sliding Window
R-CNN에서 최초로 채택되었으나 속도가 너무 느림Faster R-CNN에 Sliding Widow기법을 채택해 Network(GPU) 단위에서 수행하도록 설계
방법1. Sliding Window
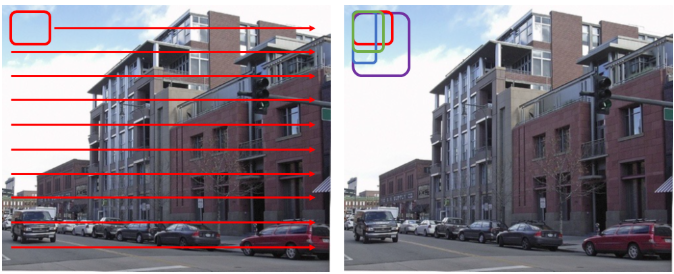

정의
Sliding Window방식은 이미지에서 물체를 찾기 위해 window의 (크기, 비율)을 임의로 마구 바꿔가면서 모든 영역에 대해서 탐색하는 것
단점
CPU환경(느림)에서 임의의 (크기, 비율)로 모든 영역을 탐색하는 것은 매우 느리다 + 너무 많은 연산을 필요로한다
방법2. Selective Search
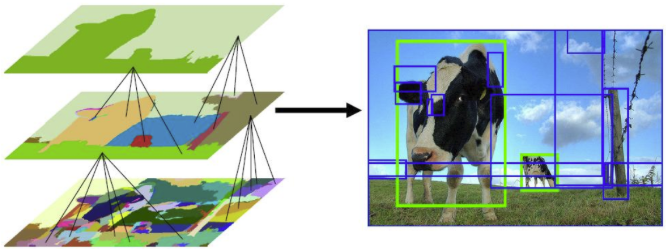
정의
인접한 영역(region)끼리 유사성을 측정해 큰 영역으로 차례대로 통합해 나가는 방식
메커니즘
- 색상, 질감, 영역크기 등을 이용해 non-object-based segmentation을 수행 이 작업을 통해 좌측 제일 하단 그림과 같이 많은 small segmented areas를 얻음
- Bottom-up 방식으로 small segmented areas들을 합쳐 더 큰 segmented areas들을 만듦
- 2번의 작업을 반복하여 최종적으로 2000개의 Region Proposal을 생성
Selective Search 알고리즘에 의해 2000개의 region proposal이 생성되면 이들을 모두 CNN에 넣기 전에 같은 사이즈로 wrap시켜야한다.
단점
- CPU환경에서 수행되며, 이미지 한 장당 약 2초의 시간이 걸리므로 많은 시간을 필요로한다.
RPN(Regions Proposal Network)
RCNN, SPP Net, Fast RCNN 모델들의 공통점은 객체가 ‘있을 법한’ 영역을 추천해주는 Region Proposal 단계를 Selective Search 방법을 사용해 구현. 하지만, Selective Search는 네트워크 구조가 아니기 때문에 오랜 시간이 걸린다는 단점이 존재한다. 그래서 Region Proposal 단계도 딥러닝과 같은 네트워크 구조로 만들어 탐지 속도를 높이자는 목표를 연구진들은 설정했다. 그 결과 RPN이 탄생되었다.
RPN이란 VGG, ResNet과 같은 Feature Extraction에 입력이미지를 넣어 나온 Feature Map에다가 convolution을 적용해 해당 Region들에 객체가 있는지 없는지 분류하고 동시에 그 객체가 있을만한 Region의 바운딩 박스 좌표를 회귀하는 것을 함께 수행하는 네트워크를 의미한다. 그래서 네트워크라는 특성으로 인해 GPU 이용이 가능하고 결과적으로 기존의 Selective Search보다 속도가 빠른 장점이있다.
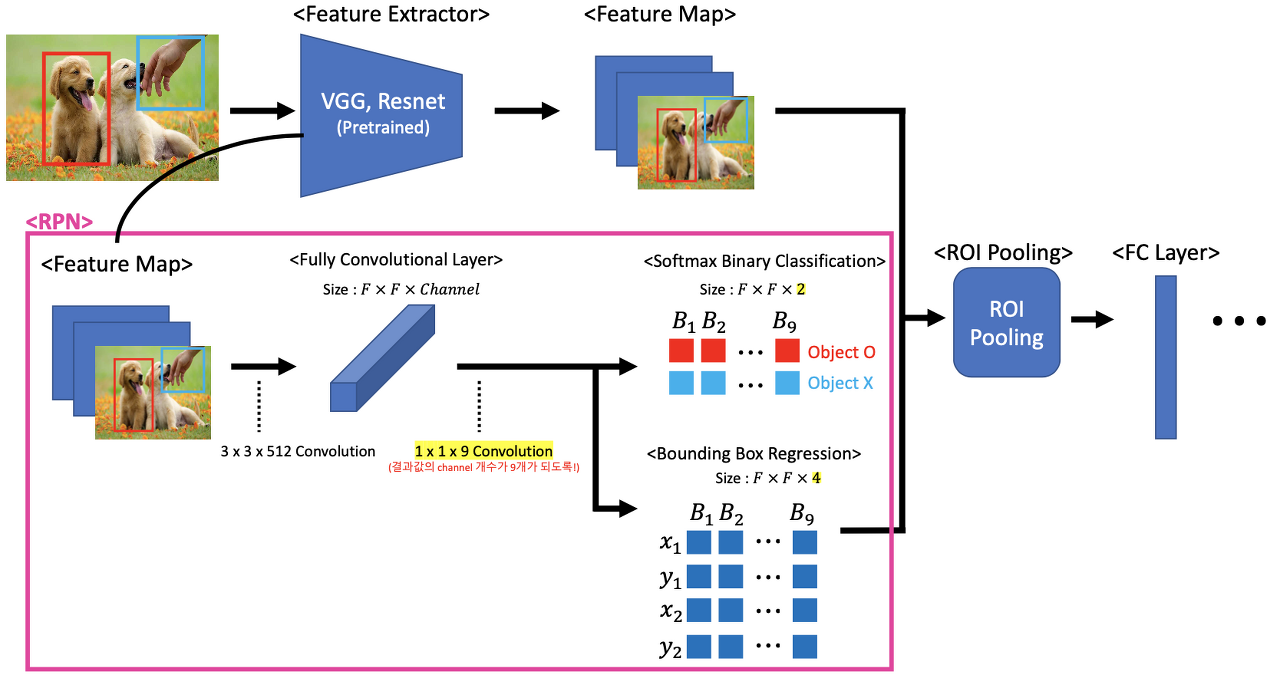
RPN은 위 그림처럼 Feature Map에 Convolution을 2번 사용해 Fully Convolutional Layer를 만든다. 중간 1x1 Convolution을 사용하는 이유는 Channel개수를 2개, 4개로 맞추어 주기 위해 사용한다. 1x1 Convolution을 통해 나온 결과값을 Ground Truth와 IoU값을 비교하면서 IoU값이 0.5보다 크면 Positive Anchor Box, 작으면 Negative Anchor Box로 분류한다. 결국 해당 Region에 객체가 있을 법한지 아닌지(이진 분류)를 수행한다. 그리고 그 바운딩 박스의 좌표($x_1$, $y_1$, $x_2$, $y_2$)를 회귀도 동시에 수행하게 된다.
참고로 위와 같이 RPN에서 2번의 Convolution을 거치는 이유는 1x1 Convolution을 거쳐야 Anchor Box별로 학습된 클래스와 Bounding Box Accordination을 쉽게 추출할 수 있기 때문이다.
RPN’s Loss
RPN도 딥러닝과 같이 일종의 네트워크. 네트워크 내부에서 학습을 시키기 위해서는 Cost Function이 필요하다. RPN 또한 분류와 회귀 문제를 동시에 수행하기 때문에 Multi-task Loss를 사용한다.
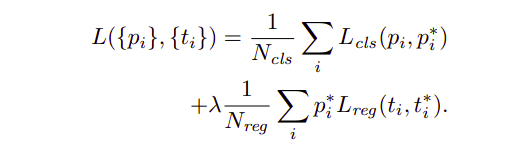
다른 모델들과 Multi-task Loss라는 점에서는 유사하지만 주목할 점은 바로 Anchor Box이다. Negative Anchor Box로 분류되는 Regions들은 0으로 계산되어 $L_1$ $smooth$ 함수를 계산할 필요가 없게 된다.
또 하나 주목할 점은 Mini-batch라는 개념이 사용된 것이다. Mini-batch란 보통 방대한 양의 데이터를 학습시킬 때 전체 데이터셋을 일부(batch)로 분할해 차례차례 넣어서 학습시키는 것을 의미한다.
RPN도 네트워크이며 ‘학습’을 시켜야한다. 그런데 방대한 양의 이미지 데이터를 한 번에 학습시킨다면 방대한 양의 Positive 또는 Negative Region들이 학습될 것이다. 그렇게 되면 네트워크 학습 시 효율성이 떨어지게 된다. 따라서 특정 사이즈로 데이터셋을 분할해 학습시키는 Mini-batch 학습을 시켜준다.
또 한번의 Region Proposal
위의 과정을 통해, Region Proposal이 완료된다면 이미지가 어떤지에 따라 달맂겠지만 수많은 Positive Anchor Box로 분류된 Region들이 추천이 된다. 다시 말해, 다소 필요없는 Region들도 추천이 된다는 의미이다. 따라서 이 추천된 수많은 Region들에 대해 다시 한 번 필터링 과정을 거친다.
이 또 한 번의 필터링 시 사용하는 개념이 Objectness Score이다. 즉, 1차적으로 RPN의 결과로 나온 Positive Anchor Box들만을 대상으로 각 Box당 Objectness Score를 계산해주고 이 Score 기준으로 내림차순으로 정렬 한 후 상위 N개의 Positive Anchor Box들만 최종 Region Proposal하게 된다.
$ Objectness Score = Softmax() * IoU() $
RoI Pooling
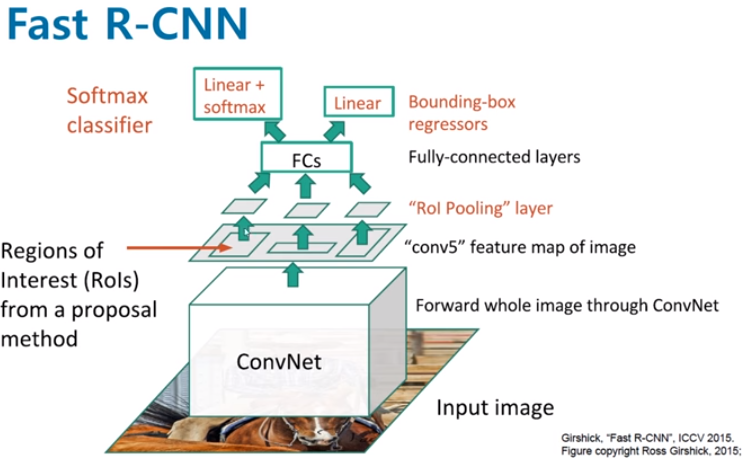
Fast R-CNN에서 적용된 1개의 피라미드 SPP로 고정된 크기의 Feature Map을 만드는 과정을 RoI Pooling 이라고 한다
- Fast R-CNN에서 먼저 입력 이미지는 CNN을 통과하여 Feature Map을 추출한다.
- 추출된 Feature Map을 미리 정해놓은 H x W 크기에 맞게끔 grid를 설정한다.
- 각각의 칸 별로 가장 큰값을 추출하는 max pooling을 실시하면 결과값은 항상 H x W 크기의 Feature Map이 되고, 이를 펼쳐서 Feature Vector를 추출하게 된다.
이렇게 RoI Pooling을 이용함으로써 원래 이미지를 CNN에 통과시킨 후 나온 Feature Map에 이전에 생성한 RoI를 Projection시키고 이 RoI를 FC layer input 크기에 맞춰 고정된 크기로 변형할 수가 있다.
따라서 더이상 2000번의 CNN연산이 필요하지 않고 1번의 CNN연산으로 속도를 대폭 높일 수 있다.
이러한 RoI Pooling은 Spatial Pyramid Pooling에서 피라미드 레벨이 1인 경우와 동일하다.
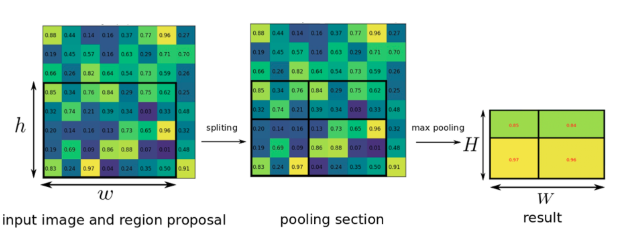
인풋 이미지의 크기와 Feature Map의 크기가 다를 경우, 그 비율을 구해서 ROI를 조절한 다음, ROI Pooling을 진행한다.
end-to-end
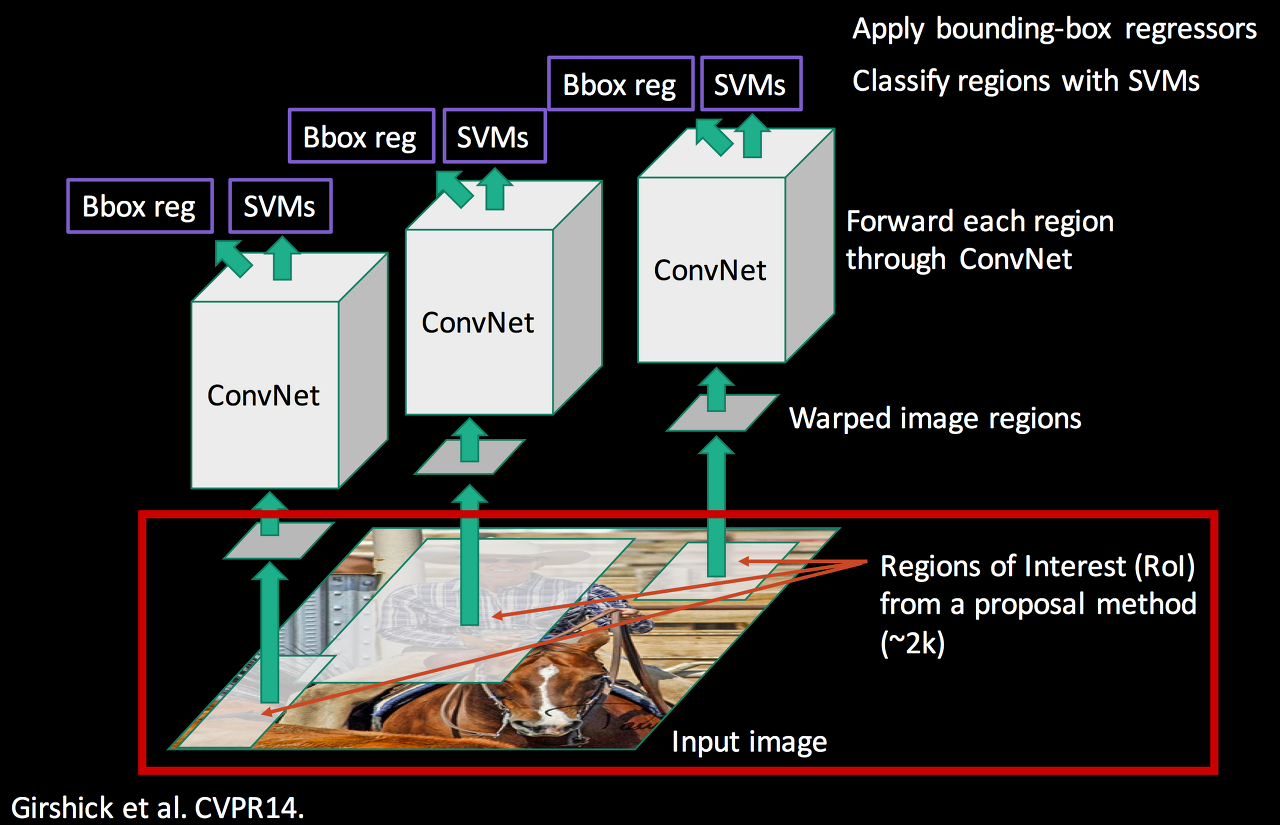
R-CNN의 두번째 문제였던 multi-stage pipeline으로 인해 3가지 모델을 따로 학습해야했던 문제.
R-CNN에서는 CNN을 통과한 후 각각 서로다른 모델인 SVM(classification), bounding box regression(localization) 안으로 들어가 forward됐기 때문에 연산이 공유되지 않았다.
- bounding box regression은 CNN을 거치기 전의 Region Proposal 데이터가 input으로 들어가고 SVM은 CNN을 거친 후의 Feature Map이 input으로 들어가기에 연산이 겹치지 앟는다.
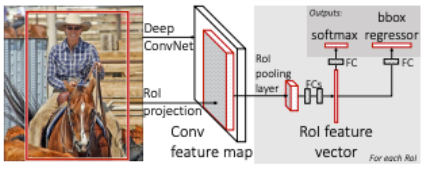
그러나 RoI Pooling을 추가함으로써 RoI영역을 CNN을 거친후의 Feature Map에 투영시킬 수 있었다. 따라서 동일 데이터가 각자 softmax(classification), bounding box regressor(localization)으로 들어가기에 연산을 공유한다. 이는 이제 모델이 end-to-end로 한 번에 학습싴리 수 있다는 뜻이다.
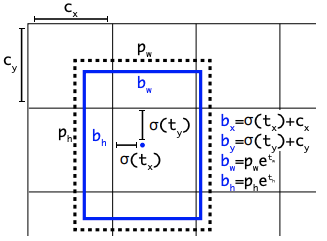
Anchor Box
Anchor Box는 Object Detection task에서 모델링에 필요한 아주 중요한 개념이다. 이는 객체탐지 모델의 성능 향상에 매우 중요한 lever가 될 수 있을 것이다. 특히, 불규칙적인 모양을 가진 물체에 대해 Detecting 한다면 말이다.
The Object Detection Task
Object Detection 에서 물체가 이미지에서 나타날때 우린 물체에 대해 identify, localize 할 것이다. 이는 ‘image classification’과는 다른 개념인데, 여기엔 많은 객체의 같거나 다른 classes들이 이미지에 나타나기 때문이다. 그리고 객체탐지는 모든 객체에 대해 정확하게 예측하는 것을 추구하기 때문이다.
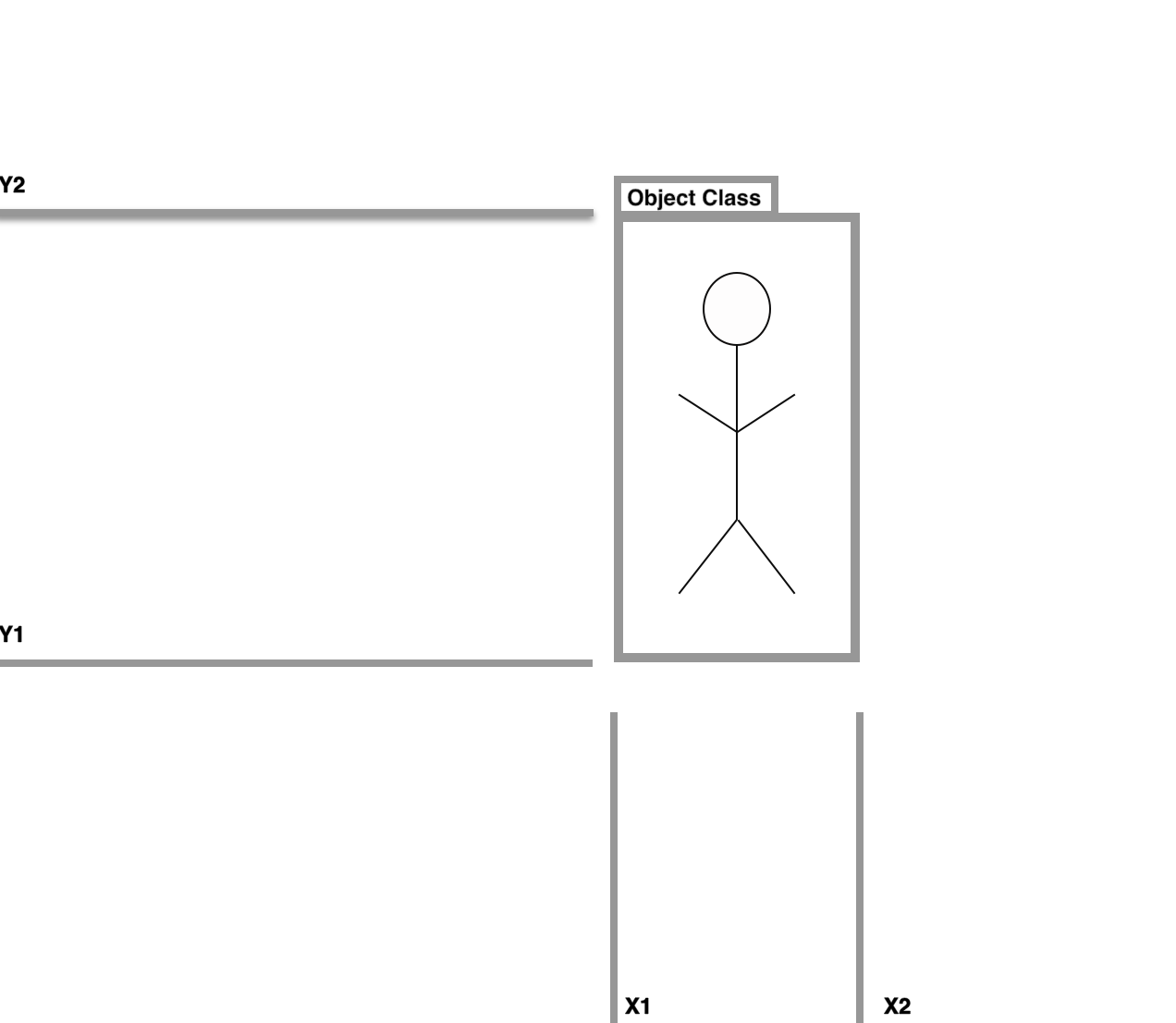
Object Detection 모델들은 위와 같은 task에 대해 예측 step을 2개로 가져가면서 씨름할 것입니다.
- regression을 통해 bounding box를 예측할 것이고
- classification을 통해 class label을 예측할 것
Anchor Boxes가 뭘까?
이미지내의 많은 다른 객체들을 예측 그리고 위치를 알아내기 위해 EfficientDet과 YOLOv4같이 대부분의 SOTA(state-of-the-art)의 Object Detection 모델들은 anchor box들을 미리 그리기 시작했다.
SOTA의 모델들은 일반적으로 bounding box들을 사용할때 다음과 같은 사항을 따른다.
- 이미지에 수천개의 candidate anchor box들을 형상화시킨다
- 각각의 anchor box를 예측하기위해 몇몇의 후보 박스로부터 box를 상쇄한다
- ground truth example에 근거하는 loss function을 계산한다
- 주어진 offset 박스는 진짜 객체와 겹쳐지게 되는 probability를 계산한다
- 만약 확률값이 0.5보다 작다면, loss function에 예측값을 전달한다
- 병렬화, 보상화 함으로써 예측된 박스들을 천천히 localizing된 실제 값을 향한 모델에 pull한다
이는 가볍게 학습된 모델의 예시이며, 이미지의 모든 부분에서 box를 볼 수 있을것입니다.
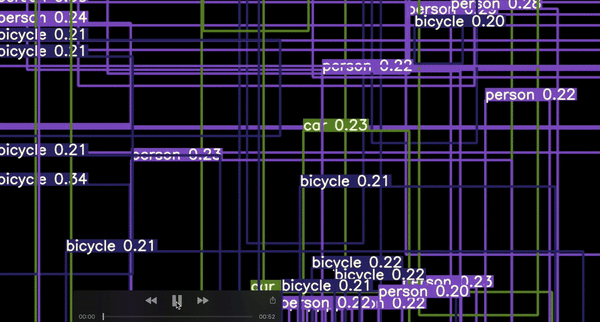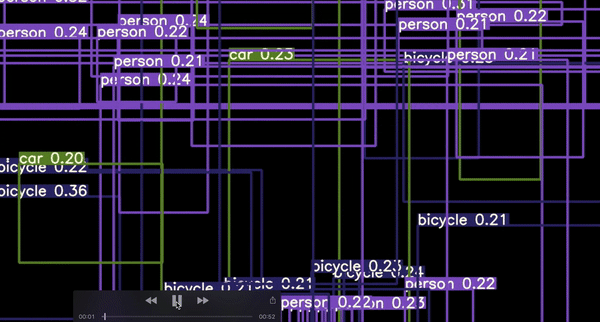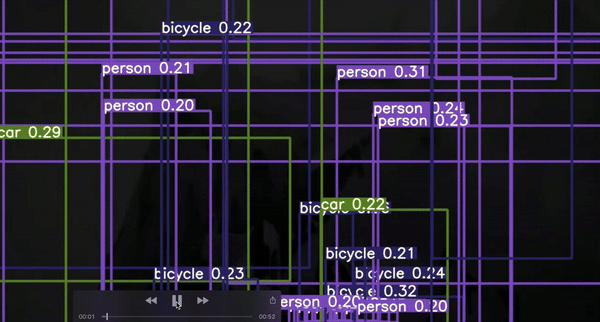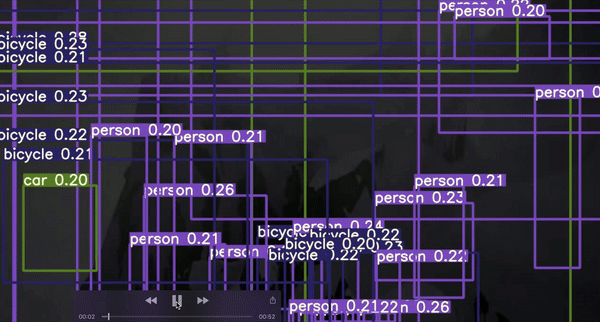
학습이 완료된 후, 사용자의 모델은 오직 높은 확률의 값을 가지는 것을 취할 것이며, 이는 가장 실제에 가까운 anchor box offset에 근거한 것이다.

Anchor Box 커스텀 튜닝하기
사용자 각 모델의 config 파일안에, anchor box를 커스텀 할 수 있는 기회가 있을것이다. 예를 들자면, Yolov5에는 다음과 같은 anchor box가 선언되어있다.
# parameters
nc : 80 ## number of classes
depth_multiple : 0.33 ## model depth nultiple
width_multiple : 0.50 ## layer channel multiple
# anchors
anchors:
- [116,90, 156,198, 373,326] ## P5/32
- [30,61, 62,45, 59,119] ## P4/16
- [10,13, 16,30, 33,23] ## P3/8
## YOLOv5 backbone
만약 COCO dataset 에서 실제값과 다소 다르게 예측이 된다면 anchor box를 custom할 수 있을 것이다. 예를 들어, 만약 기린과 같이 얇거나 매우 긴 물체를 감지해야 할때 말이다.
고맙게도, YOLOv5 auto learns anchor box distributions은 당신의 학습셋에 근거해있다. 이것은 커스텀 데이터에 사용자들의 학습하는 모델에 종종 도움을 줄 것이다.
Reference
- https://dnddnjs.github.io/cifar10/2018/10/09/resnet/
- https://ganghee-lee.tistory.com/35
- https://yeomko.tistory.com/13
- https://thebinarynotes.com/region-proposal-network-faster-r-cnn/
- https://ganghee-lee.tistory.com/36
- https://yeomko.tistory.com/15
- https://blog.roboflow.com/what-is-an-anchor-box/
- https://towardsdatascience.com/anchor-boxes-the-key-to-quality-object-detection-ddf9d612d4f9