Everything you need to know about Few-Shot Learning
Few-shot learning
이 글은 Everything you need to know about Few-Shot Learning을 번역한 글입니다. 더불어서 몇가지 내용을 추가하였습니다.
Image Classification, OJ, Semantic Segmentation과 같은 CV task의 딥러닝 모델들의 성공은 많은 양의 레이블된 데이터들을 training 네트워크에 다용하는 것과 같은 이점을 낳았습니다. 이를 지도학습supervised learning이라 하죠. 비록 많은 비구조화된 데이터는 IT시대에 가용 가능하지만 annotated data는 좀 더 확장적으로 사용 가능합니다.
데이터 라벨링은 값비싼 cost의 할애 등과 같은 이유로 CV분야의 프로젝트에 대부분의 시간을 할애합니다. 게다가 healthcare과 같은 분야에서 오직 전문가(의사)들만이 데이터를 categorization 할 수 있습니다. 예를들어, 아래에 cervical cytology에 대한 2개의 이미지가 있습니다. 혹시, 어떤 것이 악성종양인지 구분할 수 있나요?

대부분의 비전문의는 아마 답변하지 못하리라 생각됩니다. (a)가 악성종양(암) (b)는 benign(양성)입니다. 이와 같은 이유들로 인해, 데이터 레이블링은 굉장히 까다롭고 어려운 작업입니다. 가장 최선은 우리는 그저 annotated sample들만 다루는 것이겠죠. 그러나 이러한 annotated sample들이 우리가 supervised learning model에 충분히 학습할만한 양이 갖춰져 있을까요?
그리고, 새로운 데이터들이 점차 시간이 지나갈수록 생겨날 것입니다. deep neural network에 큰 데이터셋을 학습시키는 것은 많은 resource(cost)들이 필요할 것입니다. 따라서 새로 사용 가능한 데이터를 수용하기 위해 모델을 재훈련하는 것은 대부분의 시나리오에서 불가능합니다.
이러한 이유들로 말미암아, Few-shot learning이라는 새로운 concept이 생겨납니다.
Few-shot learning이 뭘까?
Few-shot learning (FSL)은 각 class에 대해 오직 몇가지만 레이블된 샘플들을 사용한 데이터의 새로운 카테고리를 사전학습 모델에 이용가능하게 한 머신러닝 framework입니다. 이건 meta-learning의 패러다임에서 파생된 개념입니다.
meta-learning : “배우는것을 배우는 방법”
우리 인간은 이전에 배운 지식을 토대로 아주 적은 예시들만들 사용해서 새로운 class들의 아주 잘 구분할 수 있습니다. FSL은 이와 같은 방식을 흉내내는 것을 목표로 합니다. 이건 “meta-learning”이라 불리며 예시들을 더 잘 이해하는것입니다.
외국의 동물원을 첫 방문했다고 가정할때, 사전에 한번도 보지 못한 이상한 새를 볼 수 있을 겁니다. 이후 3개의 카드가 주어졌을때, 각각 2개의 이미지에서 다른 새의 종류를 나타난 있다고 칩시다. 각각 새의 종이 다른 카드와 동물원에서 본 새의 이미지를 봄으로써 우린 더 쉽고 빠르게 새의 종을 추론 할 수 있습니다. 추론할 때 깃털의 색깔, 꼬리의 길이 등과 같은 정보가 사용되겠죠? 즉 우리는 스스로 몇가지 지원 정보를 사용함으로써 새의 종류를 학습한 것입니다. 이게 바로 meta-learning이 모방하고자 한 것입니다.
FSL과 관련된 중요한 용어
-
Support Set : support set은 각 데이터 카테고리의 몇가지 레이블된 샘플들로 구성되어있으며 사전 학습된 모델은 이러한 새로운 클래스에 대해 일반화하는 데 사용합니다.
-
Query Set : query set은 new & old 카테고리의 데이터셋으로부터 구성된 샘플들로 구성되어있습니다. 이러한 데이터셋에서 모델은 이전의 정보와 support set으로부터 얻은 정보들을 사용해 일반화할 필요가 있습니다.
-
N-way K-shot learning scheme : FSL 분야에서 일반적으로 사용되는 용어로 k는 몇가지 클래스가 있는가, 즉 범주의 수를 의미합니다. N은 각 클래스별 이미지가 몇 개나 존재하는지에 대한 지표로 범주별 support 데이터의 수라고 할 수 있습니다.

위 그림에서는 다람쥐, 토끼, 햄스터, 수달 4가지의 클래스가 있으므로 4-way가 됩니다. 그리고 각 클래스별로 2개의 이미지가 있으므로 2-shot이 됩니다. 4-way 2-shot 문제라고 할 수 있겠죠.
주로 K는 1~5의 값을 사용합니다. K값이 1인 경우를 우리는 One-Shot Learning이라 칭하죠. K값이 0인 경우는 Zero-Shot Learning이라 하는데 해당 task는 다음 글에 이어가도록 하겠습니다.
왜 FSL 일까?
전통적인 지도학습 방법들은 학습시에 상당한 양의 레이블 데이터를 사용합니다. 게다가 테스트셋은 같은 카테고리들만 속해있는것이 아니라 근사한 통계적 분포로부터 와야합니다.예를 들어, 휴대폰으로 촬영한 이미지로 생성된 데이터 세트는 고급 DSLR 카메라로 촬영한 이미지로 생성된 데이터 세트와 통계적으로 다릅니다. 이를 흔히 도메인 시프트라고 합니다.
Few-shot learning은 다음에 기술된 방법들로 인해 문제들을 완화합니다.
- 비용이 많이 드는 레이블데이터의 큰 볼륨을 위한 필요조건은 학습하기위한 모델을 위해 근절되어집니다. 왜냐하면, 목표는 오직 소수의 레이들된 샘플들을 사용하여 일반화하는 것이기 때문입니다.
- 사전학습된 모델(예를들면 ImageNet과 같은 큰 데이터셋들로 학습된)은 데이터의 새로운 카테고리들로 확장되기 때문에 처음부터 재학습 시킬필요가 없습니다. 이를 통해 연산 학습량(cost)을 save할 수 있습니다.
- FSL을 사용할떄, 모델은 적은 양의 카테고리의 데이터에 대해 제한된 이전 정보들로 배울수 있습니다. 예를들면, 멸종위기에 처하거나 새롭게 발견된 특별한 종들은 희귀하며 이는 FSL model로 학습시키기에 충분할 것입니다.
- 비록 통계적으로 다른 분포의 데이터를 사전학습한 모델일지라도 support set과 query set의 데이터 일관성이 존재하는한 다른 데이터 도메인으로 확장시켜 사용할 수 있을 것입니다.
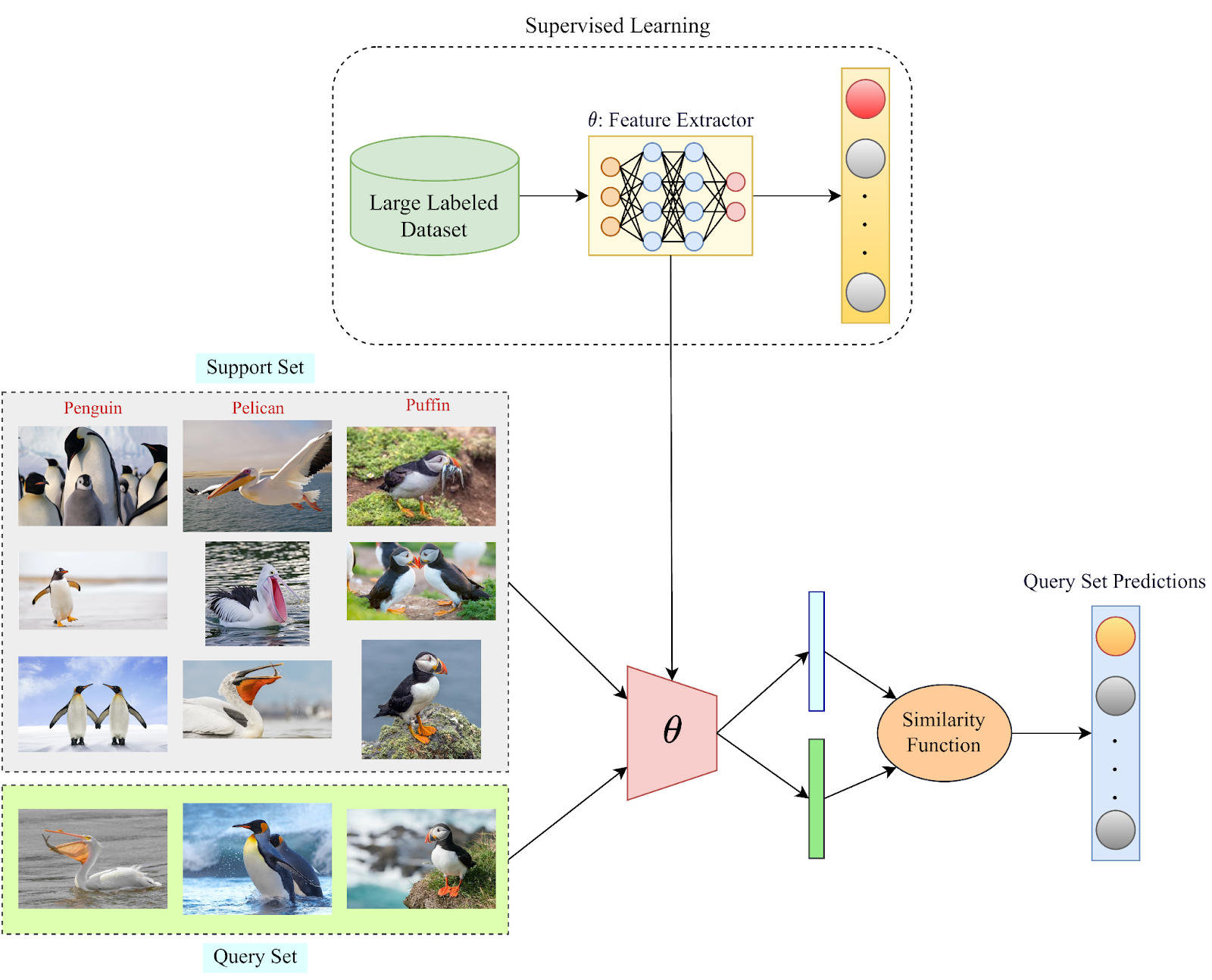
Few-shot learning은 어떻게 작동할까?
그간 전통적인 Few-shot framework에서의 목표는 support set과 query set에서 class들 사이의 유사성을 매칭할 수 있는 similarity 함수를 배우는 것이었습니다. 유사도 함수는 전형적으로 어떤 유사함에 대한 확률값을 나타내는 것입니다.

예를들어, 완벽한 유사도 함수는 1.0의 값을 리턴할겁니다 (l1, l2 비교). 오실롯의 이미지와 고양이의 이미지를 비교할때 유사도는 0.0으로 리턴하였으나 이는 단지 이상적인 시나리오에 불구합니다. 실제로는 아마 0.95 정도의 값을 리턴할 것입니다. (되게 비슷하게 생겼으니까)
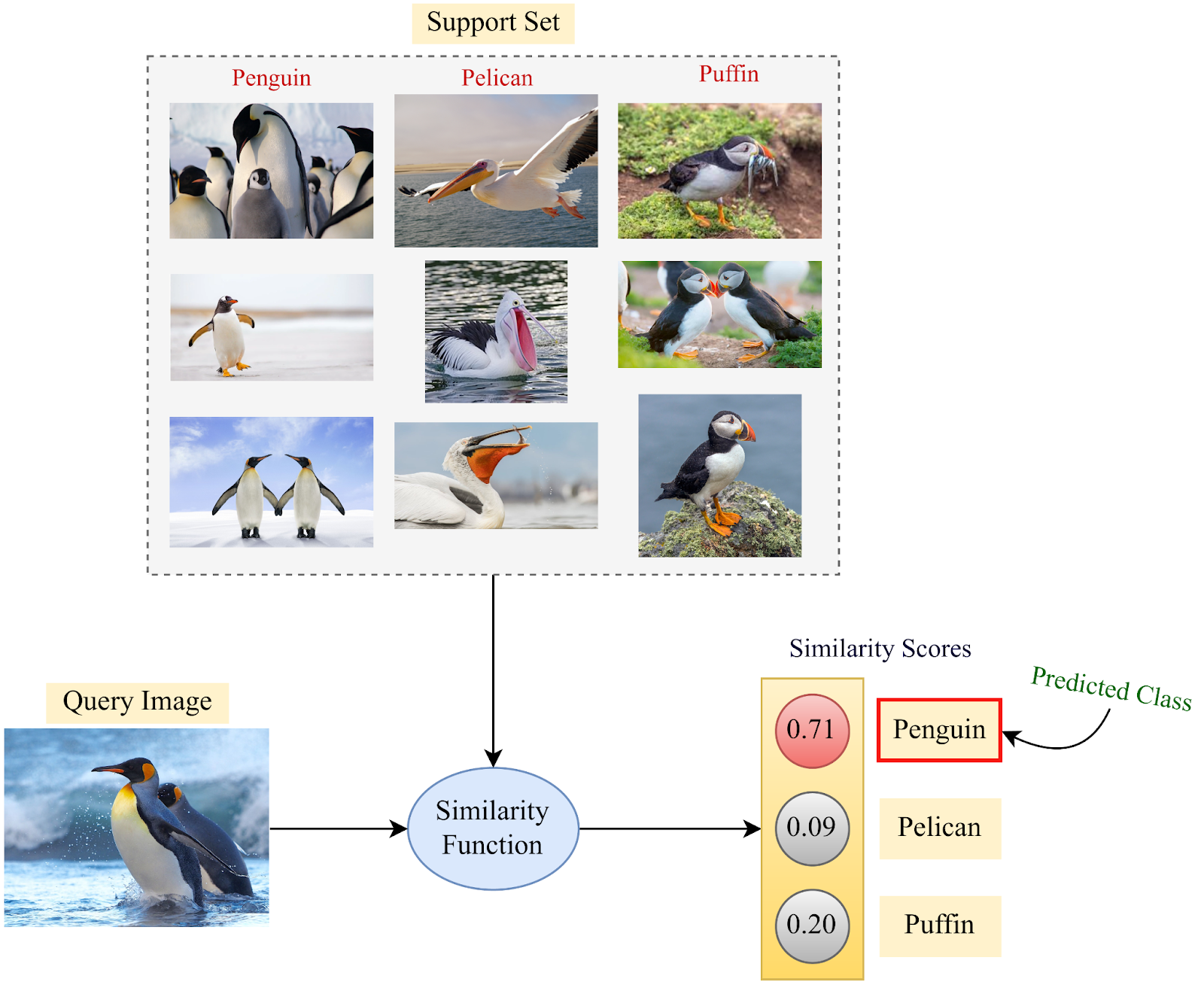
이제 유사도함수와 같은 파라미터를 사용하여 스케일이 큰 데이터셋을 학습할 수 있습니다. supervised 방식으로 딥 모델을 사전 학습하는 데 사용되는 학습 집합을 이러한 목적으로 사용할 수 있습니다. 유사도 함수의 파라미터가 학습될때, support set의 정보를 사용함으로써 query set에서 유사도 확률값을 계산하기위해 Few-shot learning을 사용할 수 있을것입니다. 그후에, support set에서 가장 높은 유사도 값을 가진 클래스가 Few-shot model로부터 class label을 예측할 것입니다.
Siamese Network (샴 네트워크)
FSL용어중에, 유사도 함수들은 모두 “함수”일 필요가 없습니다. 그저 일반적으로 nerural networks일 뿐입니다. 가장 잘 알려진 예로 샴 네트워크가 있습니다. 이 이름은 물리적으로 연결되어진 “샴 쌍둥이”에서 기인합니다. one-to-one인 전통적인 뉴럴네트워크와 달리 샴 네트워크는 2개 또는 3개의 인풋을 가지며 하나의 아웃풋으로 나타납니다.
샴 네트워크를 학습하는 2가지 방식이 존재합니다.
Method 1: Pairwise Similarity
샴네트워크에 두개의 인풋이 상응하는 레이블과 함께 주어집니다. 첫번째로, 무작위하게 데이터셋에서 샘플을 하나 선택합니다. 그러고 나서 다시 한번 더 무작위로 선택합니다. 만약 두번째 샘플이 똑같은 첫번째 샘플과 같은 class라면 레이블에 1.0 값을 ground truth로 할당합니다. 다른 모든 class의 경우, 0.0이라는 레이블이 ground truth로 할당됩니다.

따라서 네트워크는 유사도 매칭 기준을 레이블된 예시들을 통해서 필수적으로 학습합니다. 이 예시는 다음과 같습니다. 이미지들은 첫번째로 그들에 상응하는 표현정보를 얻기 위해 같은 사전학습된 특징 추출기(전형적인 Convnet)를 개별적으로 지납니다. 그러고나서 얻어진 두개의 표현정보들은 유사도 점수를 얻기 위해 dense layer와 활성화함수(sigmoid)를 통해 합쳐지고 통과되어집니다. ground truth 유사도 점수가 사용되어지기 위해 샘플들이 같은 클래스에 속하는지 속하지 않는지 알 수 있습니다.
Method 2: Triplet Loss
Triplet Loss는 method1의 확장판이라 할 수 있는데 학습 전략이 조금 다릅니다. 첫째로, “anchor” 샘플이라고 불리는 데이터셋에서 무작위하게 하나의 샘플을 고릅니다. 다음에 2개의 다른 샘플들 고릅니다. 하나는 anchor 샘플에서 같은 class(positive sample)를 고르고 하나는 다른 class 샘플(negative)을 고릅니다.
3개의 샘플이 골라지면, embedding 공간에서의 상응하는 표현정보를 얻기 위해 동일한 Neural Network에 passing합니다. 그런 후에 anchor와 positive 사이의 L2 norm distance (‘d+’), anchor와 negative 사이의 L2 norm distance (‘d-‘)를 연산합니다. 이 파라미터들은 Loss-function을 정의할 수 있게 해줍니다.

여기서 “>0”은 최대 함수의 두 항이 같지 않도록 하는 여백입니다. 여기서 목표는 아래 그림과 같이 앵커 샘플과 네거티브 샘플의 표현을 임베딩 공간에서 최대한 멀리 밀어내고 앵커 샘플과 네거티브 샘플의 표현을 최대한 가깝게 당기는 것입니다.

import torch
import torch.nn as nn
triplet_loss = nn.TripletMarginLoss(margin = 1.0, p = 2)
anchor = torch.randn(100, 128, requires_grad = True)
positive = torch.randn(100, 128, requires_grad = True)
negative = torch.randn(100, 128, requires_grad = True)
output = triplet_loss(anchor, positive, negative)
output.backward()
FSL을 위한 접근법
FSL에 대한 접근 방법은 총 4개의 카테고리에서 분류되어져 왔습니다. 이 글에선 3가지만 다루겠습니다.
Data-Level
Data-level FSL 접근법은 간단은 개념입니다. 만약 FSL 모델 학습이 성능이 학습데이터의 결핍의 이유로 성능이 저해되었다면 더 많은 데이터가 추가되어져야합니다. 즉, support set에 클래스당 2개의 레이블이 지정된 샘플이 있다고 가정하면 충분하지 않을 수 있으므로 다양한 기술을 사용하여 샘플을 보강해 볼 수 있습니다.
비록 데이터 증강이 각각의 set에 전체적으로 새로운 정보가 제공되지 않을지라도 FSL 학습에 도움이 될 것입니다. 다른 방식은 unlable data를 support set에 추가하는 방식으로 FSL problem은 준지도학습(semi-supervised) 방식을 차용합니다. FSL 모델은 더 많은 정보를 위해 비정형 데이터를 사용할 수 있으며 이를 통해 Few-shot 성능이 향상됨이 증명되었습니다.
다른 방법들은 또한 generative network(e.g., GAN model)을 사용하여 기존 데이터 배포에서 완전히 새로운 데이터를 합성하는 방법이 존재합니다. 그러나 GAN 기반의 접근방식은 학습시에 많은 레이블된 데이터를 필요로 합니다.
Parameter-Level
FSL에서 데이터의 사용가능성은 제한되어있으므로 overfitting은 빈번하게 발생합니다. 왜냐하면 샘플들은 확장적이며 고차원의 공간을 차지하기 때문입니다. Parameter-Level FSL 접근방식은 meta-learning의 사용방식을 포함하는데 이는 모델의 파라미터를 효율적으로 제어하는 방식입니다.
매개변수 공간을 제약하고 정규화 기법을 사용하는 FSL 방법은 매개변수 수준 접근법의 범주에 속합니다. 모델들은 제공하는 타겟 예측값을 위해 매개변수 공간 안에서 최적의 루트를 찾기 위해 학습합니다.
Metric-Level
Metric-Level FSL 접근법은 데이터 포인트 간의 거리 함수를 학습하는 것을 목표로 합니다. 이미지에서 특징을 추출하고 임베딩 공간에서 이미지 사이의 거리를 계산합니다. 이 거리 함수는 유클리드 거리, Earth mover distance, 코사인 유사도 기반 거리 등이 될 수 있습니다. 이는 샴 네트워크에 대해 언급할 때 다뤘던 내용입니다.
이러한 접근 방식을 사용하면 특징 추출기 모델을 훈련하는 데 사용된 훈련 세트 데이터를 사용하여 거리 함수의 매개 변수를 조정할 수 있습니다. 그런 다음 거리 함수는 support set와 query set 간의 유사도 점수(샘플이 임베딩 공간에 얼마나 가까이 있는지)를 기반으로 추론을 도출합니다.
One-shot Learning
One-shot Learning은 support set이 각 클래스당 오직 하나의 데이터로 이루어진 task를 의미합니다. 실생활에서 찾아볼 수 있는 예시로는 스마트폰의 안면인식 기능이 one-shot learning으로 작동하는 것일겁니다.
Few-show learning 적용
딥러닝 분야에서 Few-show learning은 다양한 task로 확장되어 지고 있는 실정입니다. 그러나 이 글에선 2가지의 예시만 보여드리겠습니다.
Image Classification (CV)
FSL는 Image Classification task에서 광범위하게 사용되어져 왔습니다. 아래에 몇가지 예시가 준비되어있습니다.
DeepEMD: Few-Shot Image Classification with Differentiable Earth Mover’s Distance and Structured Classifiers 논문에서 Few-Shot 이미지 분류에 대한 흥미로운 접근법이 소개되었습니다. 두개의 복잡한 구조화된 표현방식을 비교하는 자연스러운 방식은 building block들을 단지 비교하는 것일겁니다. 어려운 점은 학습에 대한 대응하는 지도방식이 없으며 모든 building block이 항상 다른 구조에서 대응하는 요소를 찾을 수 있는 것은 아니라는 점입니다. 이 문제를 풀기위해 저자는 Few-Shot classification을 공식화하였습니다. 저자들은 두개의 이미지에서 유사도를 추출하여 최적의 매칭 cost를 사용하는 것을 제안하였습니다.

두 이미지에서 생성된 특징 표현이 주어졌을 때, 저자들은 EMD를 채택하여 구조적 유사성을 계산합니다. EMD는 원래 이미지 검색을 위해 제안된 구조적 표현 간의 거리를 계산하기 위한 metric입니다. 모든 요소 쌍 사이의 거리가 주어지면 EMD는 최소한의 비용으로 두 구조 사이의 최적의 매칭 플로우를 얻을 수 있습니다. 이는 구조 표현을 다른 구조로 재구성하는 데 드는 최소 비용으로도 해석할 수 있습니다.
NLP
자연어 처리에서 레이블을 얻기 쉽지 않기에 FSL은 NLP 분야에서 최근에 유명해지고 있습니다.
예를들어, Diverse Few-Shot Text Classification with Multiple Metrics 논문에서 text classification task를 FSL, 특히 metric-learning 접근방식을 통해 다루었습니다. 연구자들은 meat-learner를 선택했고 meta-training taks에서 task 클러스터링을 사용해 target task를 학습하는 방식을 사용하여 다중의 metric을 결합하였습니다. meta-training동안 저자들은 클러스터에 meta-training task를 구분하는 방식을 제안하였고 각 클러스터들의 task는 서로 연관되어있습니다.

그런 다음 각 클러스터 내에서 저자는 딥 임베딩 함수를 metric으로 훈련합니다. 이렇게 하면 공통 metric이 동일한 클러스터 내의 작업 간에만 공유되도록 할 수 있습니다. 또한 메타 테스트 중에 각 대상 FSL 작업은 서로 다른 클러스터에 의해 정의된 metric의 선형 조합인 작업별 메트릭에 할당됩니다. 이러한 방식으로 다양한 Few-Shot 작업은 이전 학습 경험에서 서로 다른 지표를 도출할 수 있습니다.