mAP
mAP(mean Average Precision)
AP는 Faster R-CNN, SSD와 같이 객체탐지의 정확도를 측정하는데있어서 가장 인기있는 metric이다. AP는 0과 1사이의 값을 가지는 recall을 통해 average precision값을 계산한다. 꽤나 복잡한 얘기로 들릴수 있겠지만 예시와 함께 설명하고자한다. 그전에, precision, recall, IoU에 대해 알아보자.
Precision & Recall
Precision은 모델의 예측이 얼마나 정확한지 측정한다.
Recall은 찾은 모든 positive가 얼마나 좋은지 측정한다.

예를 들어, 암cancer에 대해 test를 진행하면 다음과 같을 것이다.

IoU(Intersection over union) = $\frac{Intersection}{Union}$
IoU는 2개의 바운더리 사이에서의 공통으로 겹치는 부분에 대해 측정한다. Ground truth(the real object boundary)와 함께 예측된 경계가 겹치는 부분들에 대해 측정하는 것을 사용한다. True positive또는 False Positive값을 예측하는 몇몇 분류 데이터셋에서 측정 IoU 임계값(Threshold)을 사전정의하기도한다.

AP
AP의 계산값을 표현할 간단한 예제를 하나 만들어보자. 이 예제의 데이터셋엔 오직 5개의 사과를 포함하고있다. 우리는 모든 이미지에서 사과에 대한 모든 예측을 수집하고 예측된 신뢰 수준에 따라 내림차순으로 순위를 매긴다. 두번째 column은 예측이 맞았는지 틀렸는지 나타나있다. 이 예제에서, IoU가 0.5 보다 크다면 예측이 correct 한게 된다.
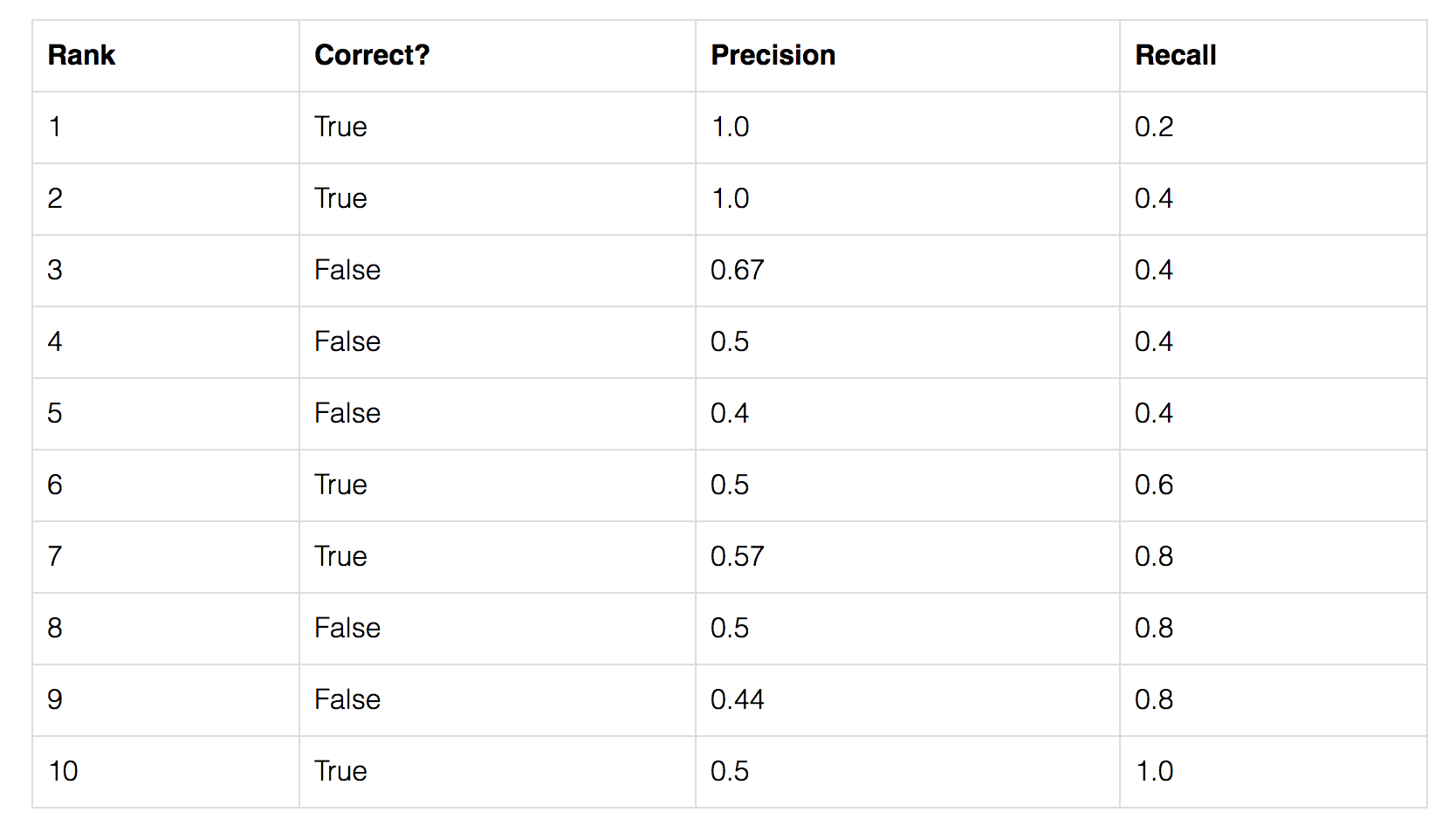
3번째 row에서의 precision과 recall을 구하는 공식을 구현해보자.
Precision : TP = 2/3 = 0.67
Recall : TP out of the Possible Positive 이니까 2/5 = 0.4
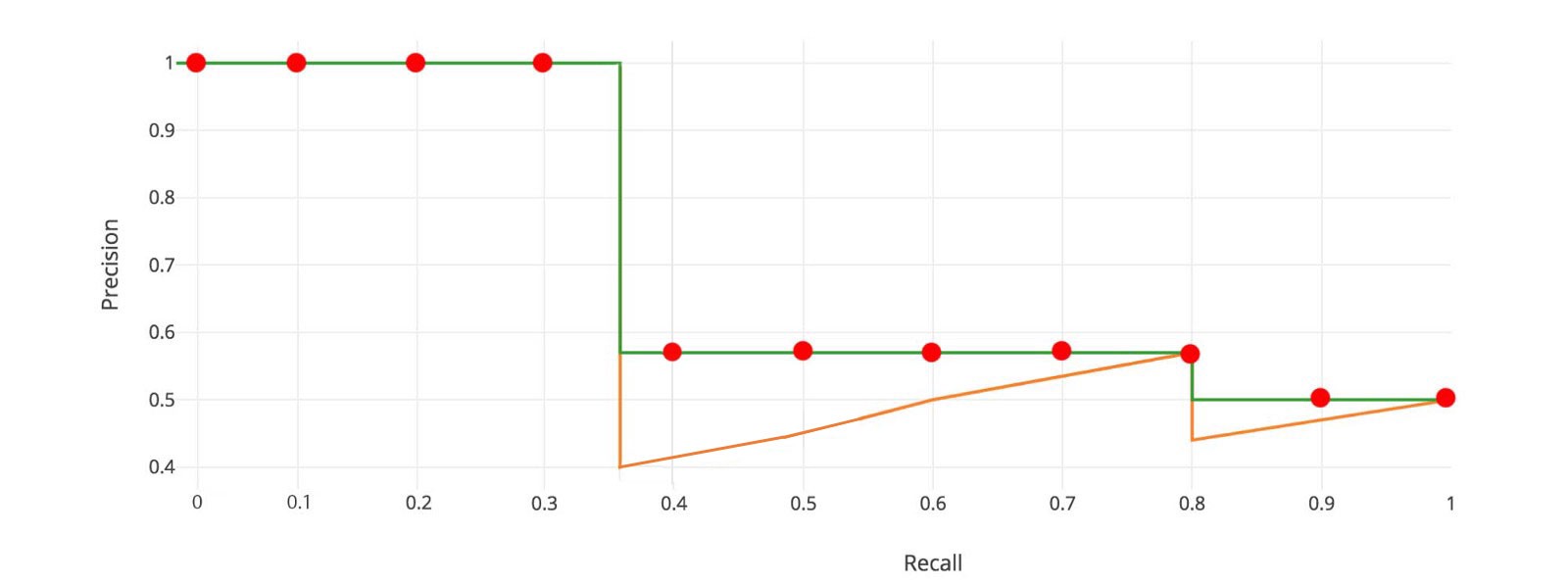
Recall값은 밑으로 보다시피, Rank를 거듭할수록 값이 커지고있다. 그러나, Precision은 지그재그 패턴이 나타난다. False Positive는 줄어들고 있음을 의미하고, True Positive는 증가하고 있음을 의미한다.
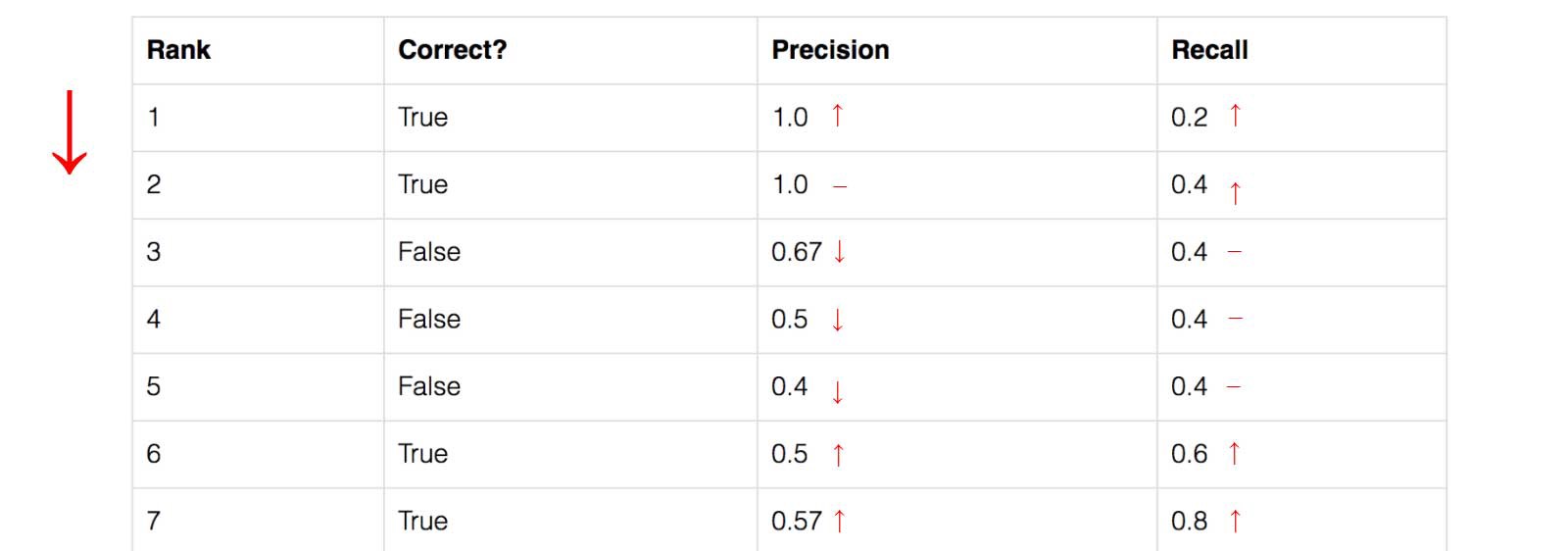
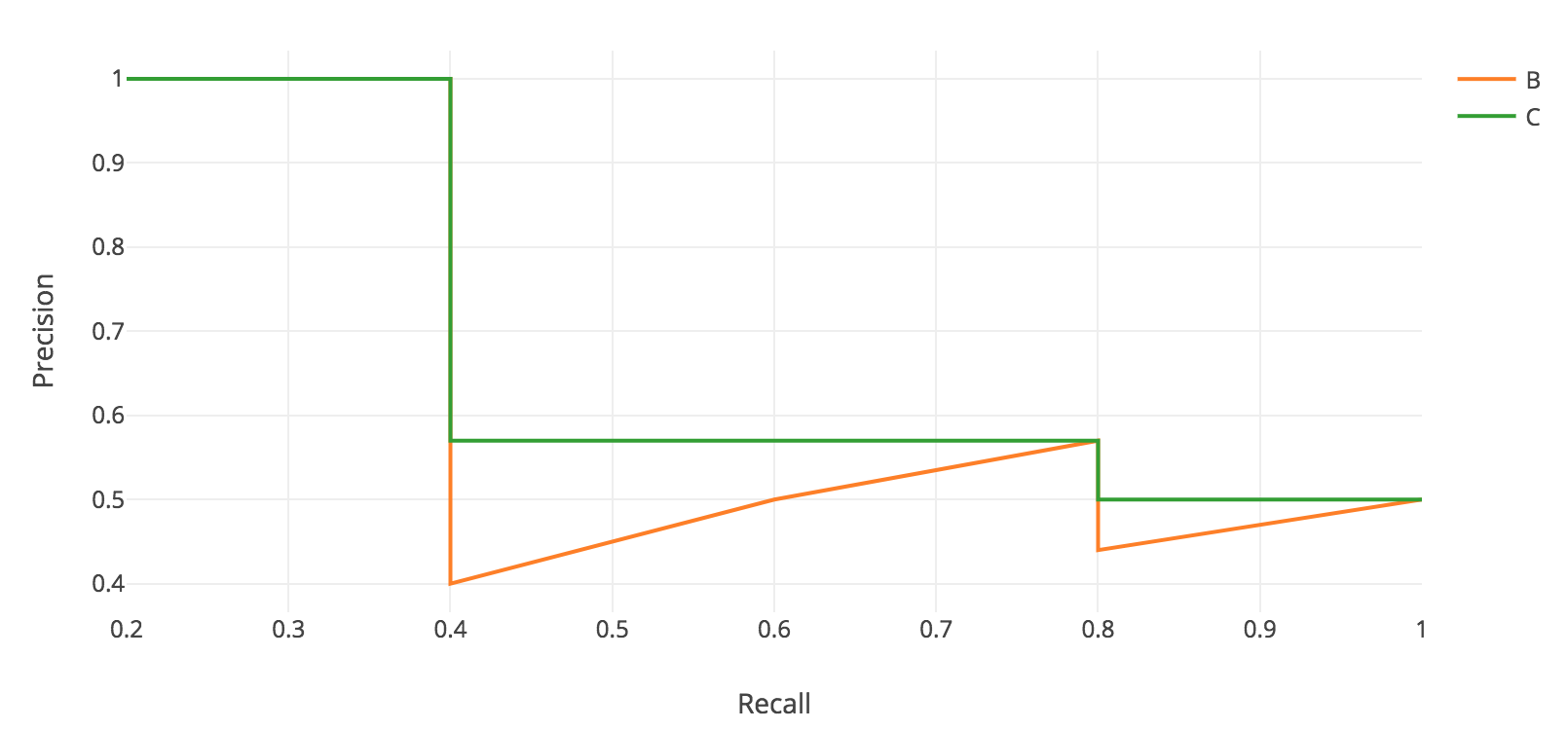
지그재그 패턴을 보기위해 precision값에 대한 recall 값을 plotting해보자.
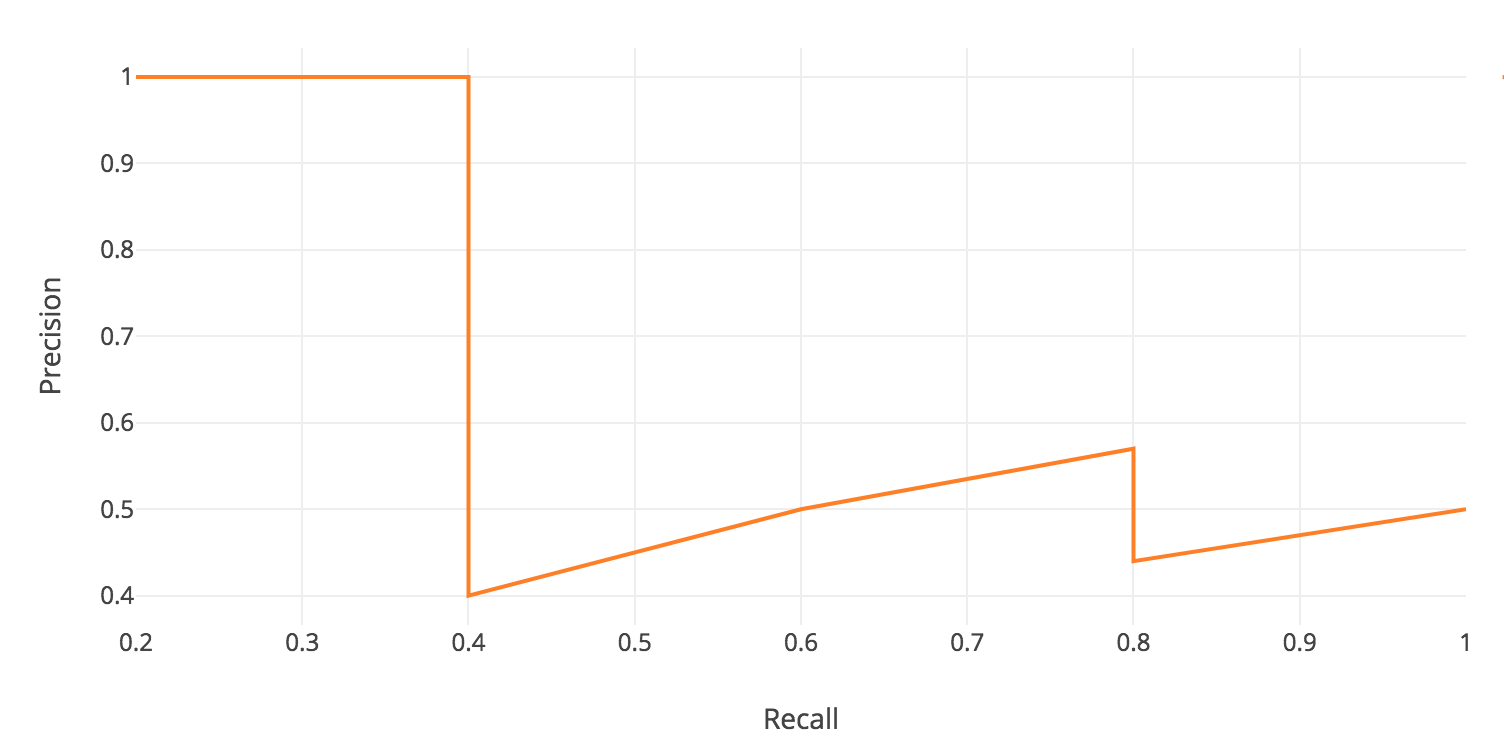
AP에 대한 일반적인 정의는 위의 precision-recall 곡선 아래의 영역을 찾는 것이다.
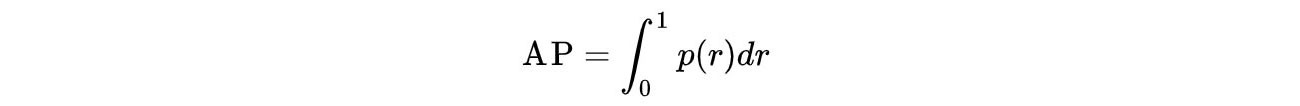
Precision값과 Recall값은 항상 0 ~ 1 의 범위를 갖는다. 그러므로, AP 또한 0 ~ 1 의 범위를 갖는다. 객체탐지를 위한 AP값 계산 전에, 지그재그 패턴을 볼 수 있다.
각 Recall Level에서 각 Precision 값을 해당 Recall Level의 오른쪽에 있는 최대 Precision 값으로 대체한다.
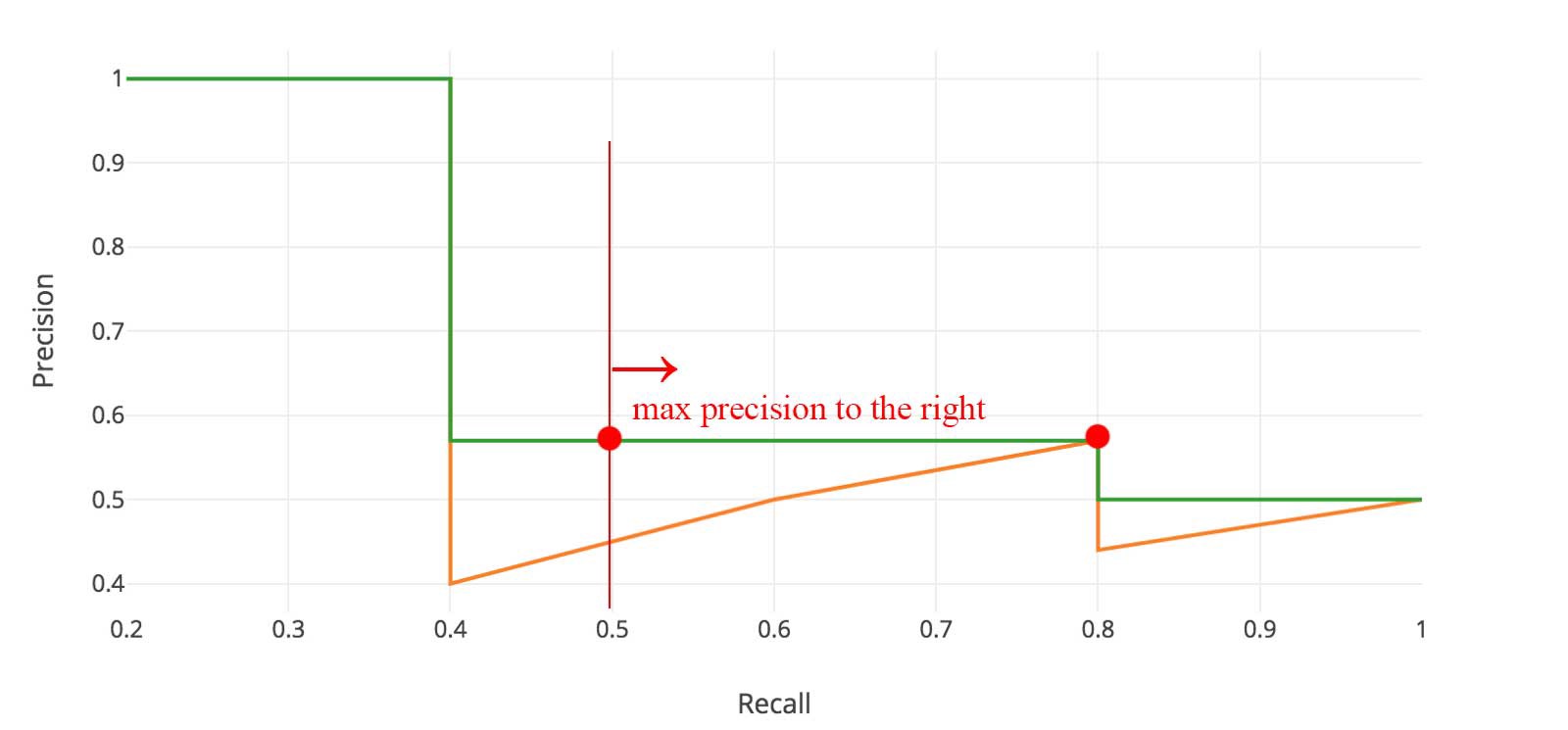
지그재그 패턴 대신에 주황색 색상의 라인이 초록색 색상의 라인으로 바뀌었다. 계산된 AP값은 랭킹의 작은 차이에도 덜 민감할 것이다. 수학적으로 표현하자면 다음과 같을 것이다.
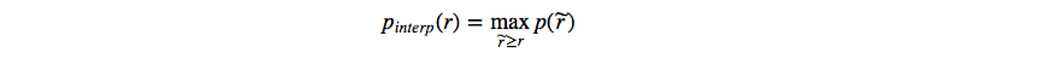
Interpolated AP
PASCAL VOC는 객체탐지 분야에서 굉장히 유명한 데이터셋이다. PASCAL VOC challenge를 위해, 만약 IoU 값이 0.5보다 크다면, 예측값은 positive일 것이다. 또한 만약 같은 객체에서 다중의 탐지가 감지된다면 첫 번째 객체에 대해선 양수로, 나머지는 음수로 계산될 것이다.
Pascal VOC2008 데이터셋에선, 평균적으로 11point의 Interpolate된 AP가 계산된다.
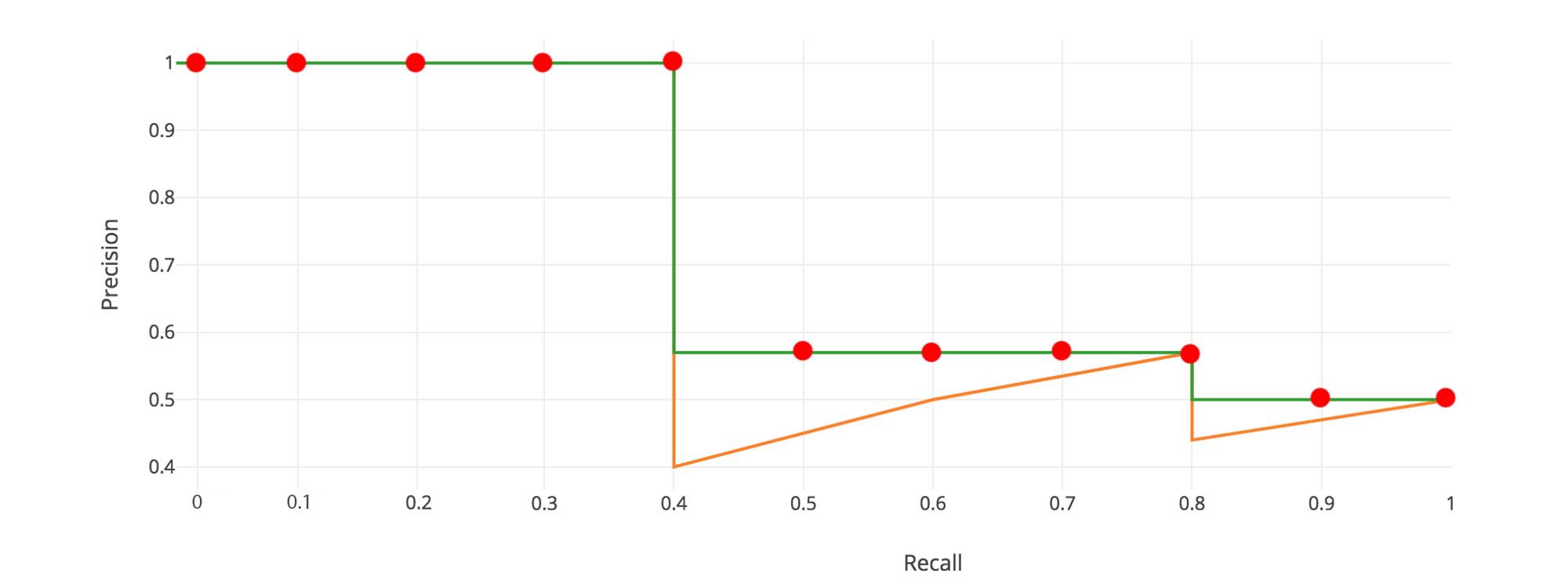
첫번째, Recall값을 0부터 1.0 point로 나누는데 11point까지 수행한다. - (0, 0.1, 0.2, …, 0.9, 1.0)
다음으로, precision 최대값의 평균을 계산한다. (for 11 recall values)
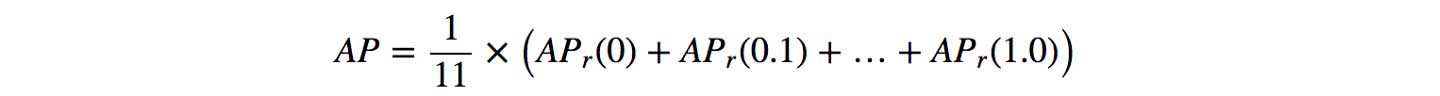
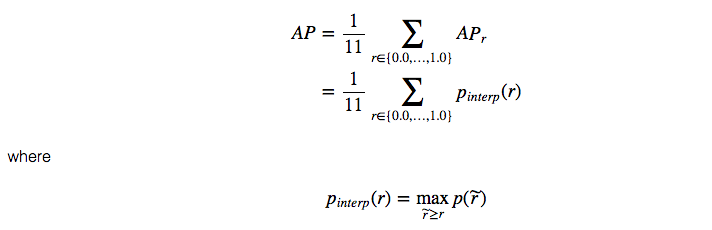
$AP_{r}$ 값이 매우 작은 값을 넘겨줄때, 남겨진 terms 들에 대해 0값을 취해줄 수 있다. 다시말해서, recall이 100%에 도달할때까지 우린 prediction을 만들어 내지 못할것이다. 만약 precision level의 최대값이 무시해도 될 정도의 level로 drop된다면 멈출 수 있을 것이다.
각기 다른 20개의 class를 가진 PASCAL VOC데이터에서 AP를 매 class를 계산할 수 있을 것이고 또한 20개의 AP 결과값들을 통해 평균값을 만들어낼 수 있을것이다.
원래의 연구원에 따르면, AP를 계산할 때 11개의 보간점을 사용하려는 의도는 다음과 같다.
The intention in interpolating the precision/recall curve in this way is to reduce the impact of the “wiggles” in the precision/recall curve, caused by small variations in the ranking of examples
그러나, 이 보간된 방법은 2개의 issue에 대해 고통받고 있다.
첫번째, 이 방법은 덜 정확하다.
두번째, AP가 낮은 방법의 차이를 측정하는 능력을 상실하였다.
그러므로, 다른 AP 공식이 2008 PASCAL VOC이후, 채택되었다.
AP(Area under curve AUC)
2010-2012 VOC은 최대 precision 값이 떨어질 때마다 모든 고유 recall값에서 곡선을 샘플링한다. 이 변화와 함께 exact한 area에 대해 측정 할 수 있을 것이다.
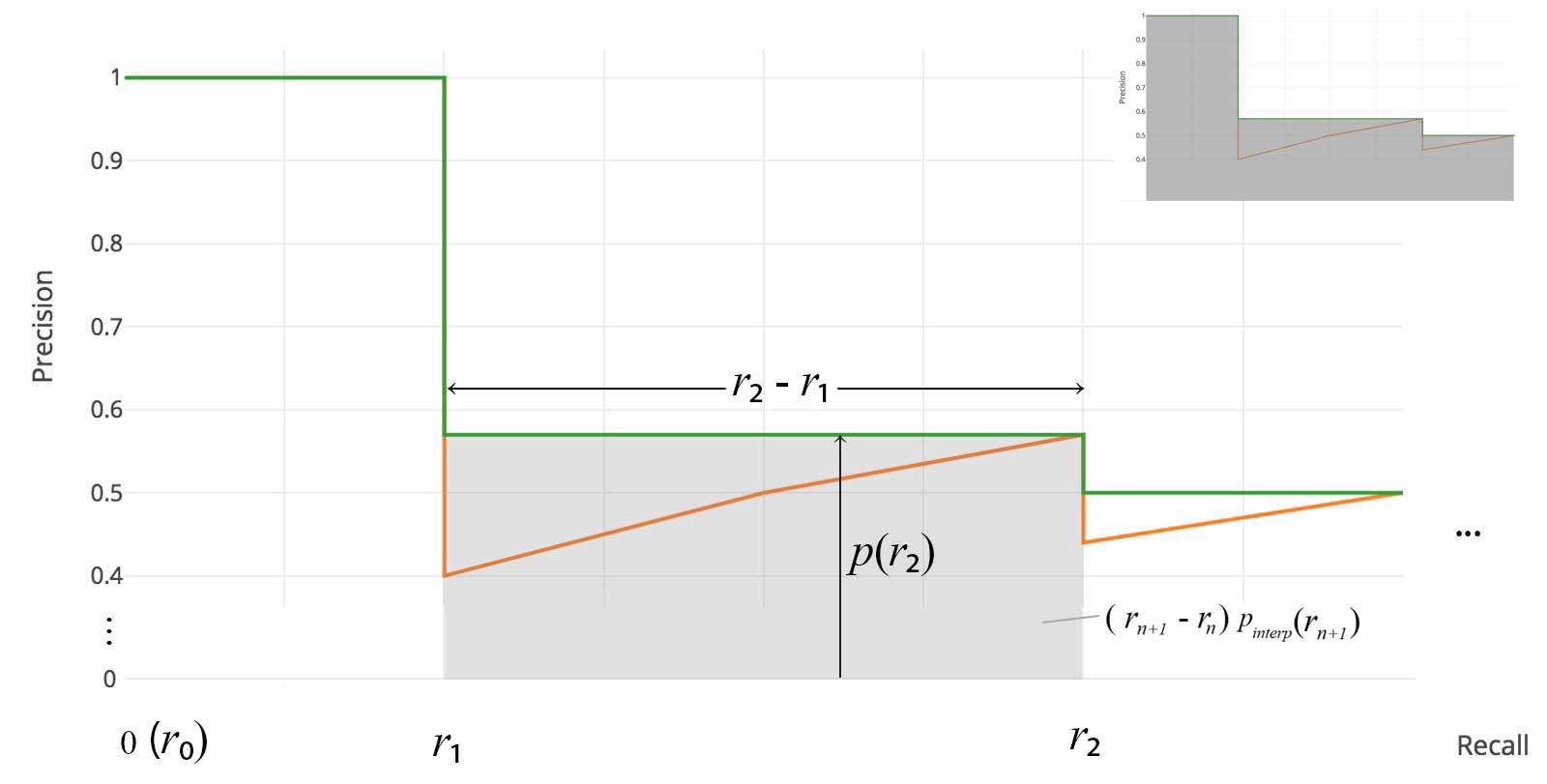
근사치, 보간 모두 필요없다. 샘플링하는 11 point 대신에 $p(r_{i})$ 를 drop하거나 AP를 계산할 때 언제든지 샘플링 할 수 있다.
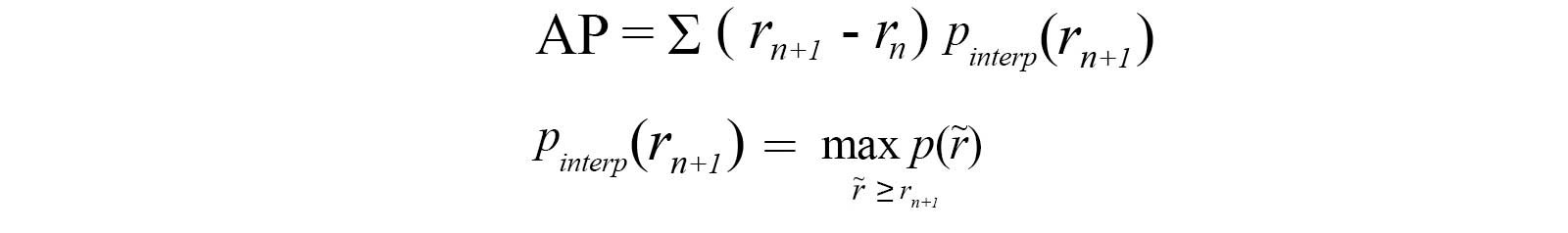
위 공식은 Area Under Curve(AUC) 라고 불린다. 아래에 나타나있듯이, 보간된 점수가 precision drop 값들에 대해 cover해주지 못할때, 두 방법들은 나뉘게 될 것이다.
COCO mAP
요즘 생산되는 논문들은 COCO 데이터셋을 통해 결과값을 도출하려는 경향이있다. COCO mAP에선 101-point Interpolated AP 정의가 계산에 사용됩니다. COCO에서 AP는 다중 IoU에 대한 평균입니다.
mAP는 AP의 평균값을 나타낸것이다. 몇몇 task에선 각 클래스에 대한 AP를 계산하고 평균화한다. 그러나 몇몇 task에선, 똑같은 값을 평균화한다. COCO task에서 예를들자면, AP와 mAP에 대해 차이점이 없다. 다음은 COCO의 인용문을 발췌해온것이다.
AP is averaged over all categories. Traditionally, this is called “mean average precision” (mAP). We make no distinction between AP and mAP (and likewise AR and mAR) and assume the difference is clear from context.
ImageNet에선 AUC 방법이 사용되어진다. 그래서 AP에 대한 모든 산출방법이 같을지라도, 다양한 값들이 만들어진다. 운좋게도, 개발툴은 이러한 metric을 계산 가능하다.
Refernce
- https://jonathan-hui.medium.com/map-mean-average-precision-for-object-detection-45c121a31173