Constitutional AI - Harmlessness from AI Feedback [2022]
Introduction
LLM assistant를 RLHF로 helpful하면서 harmless하게 정렬해왔음. 문제는 harmlessness를 학습시키려면 사람이 모델의 유해 출력에 대해 선호 비교 라벨을 수만 개 달아야 한다는 점. 이는 비용이 클 뿐 아니라, red team 작업자가 유해 콘텐츠에 반복 노출되는 부담도 동반함. 게다가 기존 helpful-harmless(HH) RLHF 모델은 harmless해지려다 민감한 질문에 무조건 “답할 수 없음”식으로 회피(evasive)하는 경향이 있어, harmlessness를 helpfulness와 맞바꾸는 한계가 있었음.
연구진(Anthropic, Bai et al.)은 다음을 묻는다. 사람이 단 하나의 harmlessness 라벨도 달지 않고, 모델 자신의 판단(AI feedback)만으로 harmless한 assistant를 만들 수 있는가? 유일한 인간 감독은 모델 행동을 규율하는 자연어 원칙 몇 개(이를 constitution이라 부름)뿐. 그래서 이 방법을 Constitutional AI(CAI)라 명명함.
이 논문의 novel한 점
- harmlessness에 대한 인간 라벨을 전혀 쓰지 않음. 인간 감독을 수만 개의 비교 라벨에서 약 16개의 자연어 원칙(constitution)으로 압축함.
- 모델이 스스로 자기 응답을 비판(critique)하고 수정(revision)하여 supervised 학습 데이터를 생성(SL-CAI).
- preference label을 사람이 아니라 모델이 생성하여 RLAIF(RL from AI Feedback)로 강화학습.
- chain-of-thought 추론을 도입해 AI의 harmlessness 판단을 단계적으로 풀게 함으로써 정확도와 투명성을 함께 끌어올림.
- 그 결과 harmless하면서도 회피하지 않는(non-evasive) — 유해 요청을 거부할 때 그 이유를 설명하는 — assistant를 얻음.
Preliminary / Related Work
이 논문은 Anthropic의 helpful & harmless RLHF assistant 연구의 직접적인 후속임. 기존 RLHF는 인간이 만든 선호 비교 데이터로 preference model(PM)을 학습하고, 그 PM을 보상 신호로 삼아 policy를 강화학습으로 최적화함. 이 틀로 helpfulness와 harmlessness를 동시에 올리려 했으나, 두 목표가 본질적으로 상충(tension)해서 harmlessness를 강하게 누르면 모델이 민감한 주제에 무조건 회피해 버리는 부작용이 있었음.
또한 harmlessness 데이터를 모으려면 red team(사람)이 직접 모델에서 유해 출력을 끌어내야 하는데, 이는 노동집약적이고 작업자의 정신적 부담이 큼. CAI는 이 인간 부담을 모델의 self-critique와 AI feedback으로 대체하려는 시도이며, 큰 모델일수록 자기 출력의 유해성을 스스로 더 잘 식별한다는 관찰(scalable oversight)에 기반함.
Method
CAI는 크게 두 단계로 구성됨. (1) Supervised stage — 모델의 self-critique·revision으로 SL 데이터를 만들어 초기 정렬을 잡고, (2) RL stage — AI가 만든 선호 라벨로 PM을 학습해 RLAIF로 성능을 끌어올림.
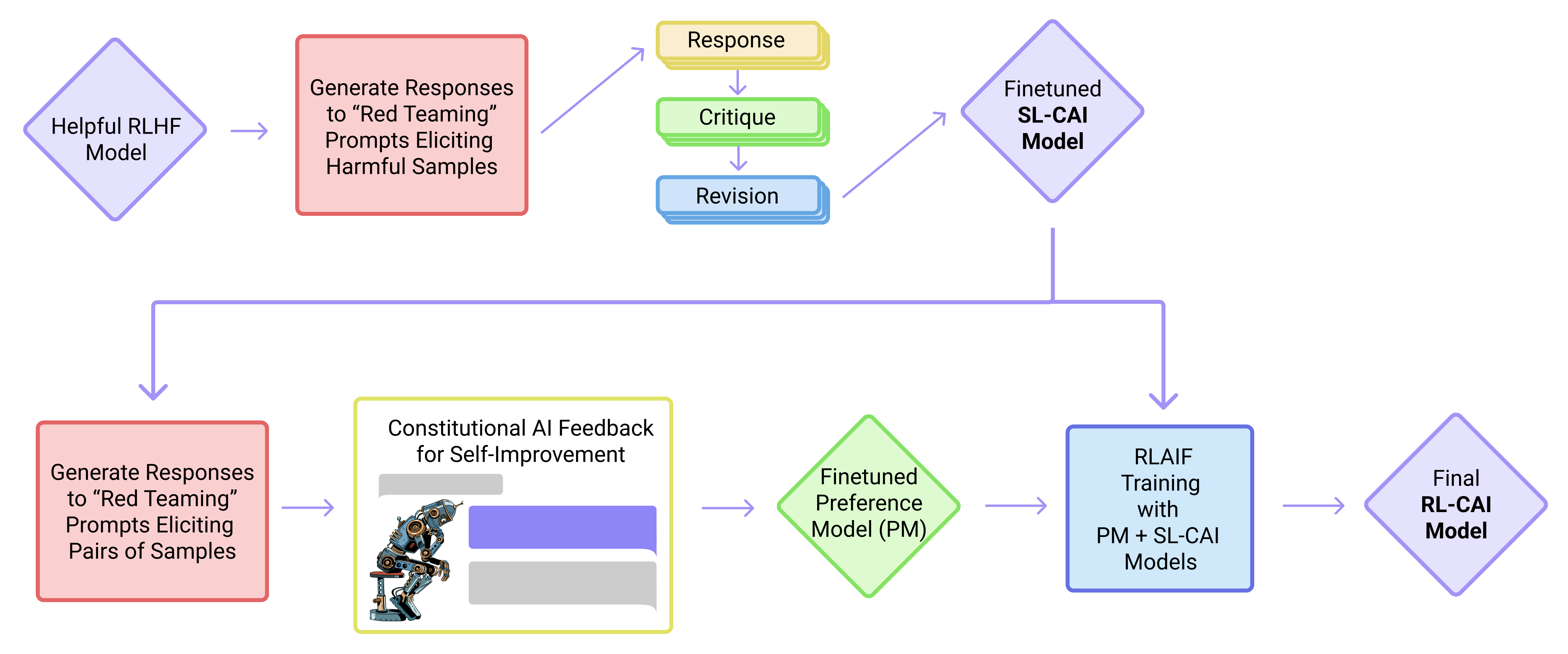
위 그림이 전체 파이프라인임. 상단(SL stage)에서 helpful RLHF 모델로 시작해 red teaming 프롬프트로 유해 응답을 유도한 뒤 Response → Critique → Revision 루프를 거쳐 SL-CAI 모델을 만들고, 하단(RL stage)에서 그 모델로 응답 쌍을 생성한 뒤 constitutional feedback으로 PM을 학습하고 RLAIF로 최종 RL-CAI 모델을 얻는 흐름을 봐야 함.
Supervised Stage: Critique → Revision
helpful-only RLHF 모델로 시작함. red teaming 프롬프트(유해 응답을 유도하는 질문)를 주면 모델은 처음엔 유해한 응답을 내놓음. 여기에 constitution에서 원칙 하나를 뽑아 “방금 응답이 왜 해롭고 비윤리적인지 지적하라”고 시켜 critique를 받고, 이어 그 비판에 따라 “응답을 다시 쓰라”고 시켜 revision을 받음. 이 비판-수정을 여러 번 반복(매번 원칙을 무작위로 교체)한 뒤, 최종 수정본들을 모아 원본 pretrained 모델을 supervised finetuning하면 SL-CAI 모델이 됨. 수정된 응답들은 거의 회피적이지 않고 민감한 주제를 사려 깊게 다룬다는 점이 핵심.
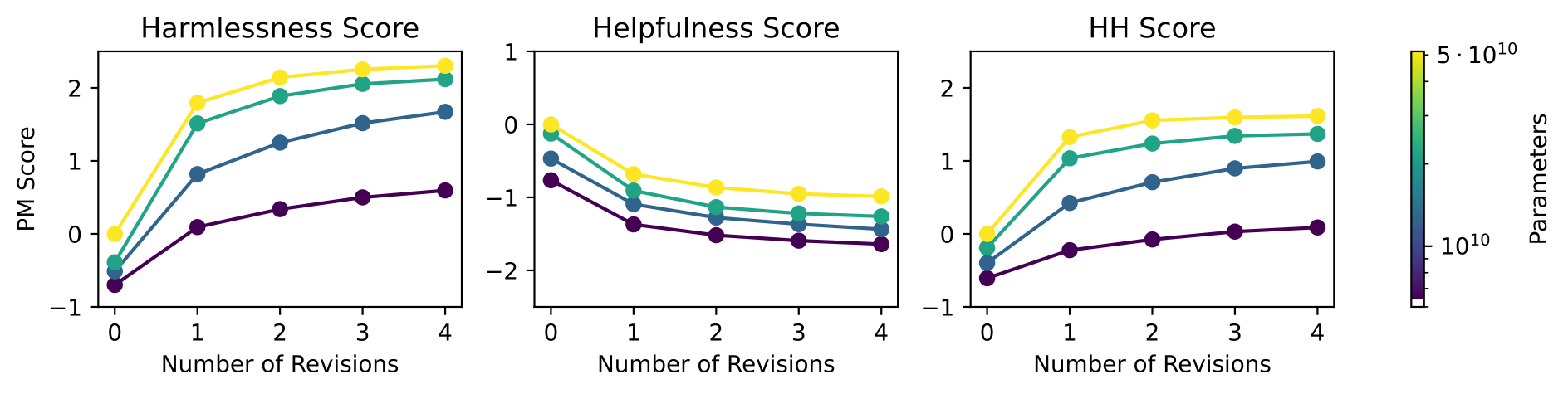
위 그림은 revision을 반복할수록 PM 점수가 어떻게 변하는지를 보여줌. 봐야 할 점은 revision 횟수가 늘수록 harmlessness 점수가 단조 증가(왼쪽)하고 종합 HH 점수도 함께 오른다(오른쪽)는 것 — 특히 큰 모델일수록 향상 폭이 큼. helpfulness는 소폭 감소(가운데)하지만 그 손실보다 harmlessness 이득이 큼. critique-revision이 실제로 작동함을 정량적으로 입증함.
RL Stage: RLAIF
RL 단계의 골자는 RLHF의 인간 선호 라벨을 AI 선호 라벨로 대체하는 것. SL-CAI 모델로 각 프롬프트에 응답을 2개 생성한 뒤, feedback 모델에게 constitution 원칙과 함께 “둘 중 어느 쪽이 덜 해로운가?”를 객관식으로 물음. 그 답의 로그확률을 정규화해 soft preference label을 만들고, 이 AI harmlessness 라벨을 기존 인간 helpfulness 라벨과 섞어 hybrid PM을 학습함. 마지막으로 그 PM을 보상으로 SL-CAI를 강화학습하면 RL-CAI 모델이 됨. constitution은 모델 행동을 규율하는 자연어 원칙 집합(논문은 16개)으로, SL에선 루프마다·RL에선 비교마다 무작위로 샘플링해 다양성과 robustness를 높임.
여기에 chain-of-thought(CoT)를 더함. feedback 모델이 객관식 답을 고르기 전 “단계적으로 생각해 보자”며 추론을 쓰게 하면 판단 정확도와 투명성이 함께 올라감. (CoT가 확률을 0이나 1로 극단화하는 문제는 40~60%로 clamp해 완화)
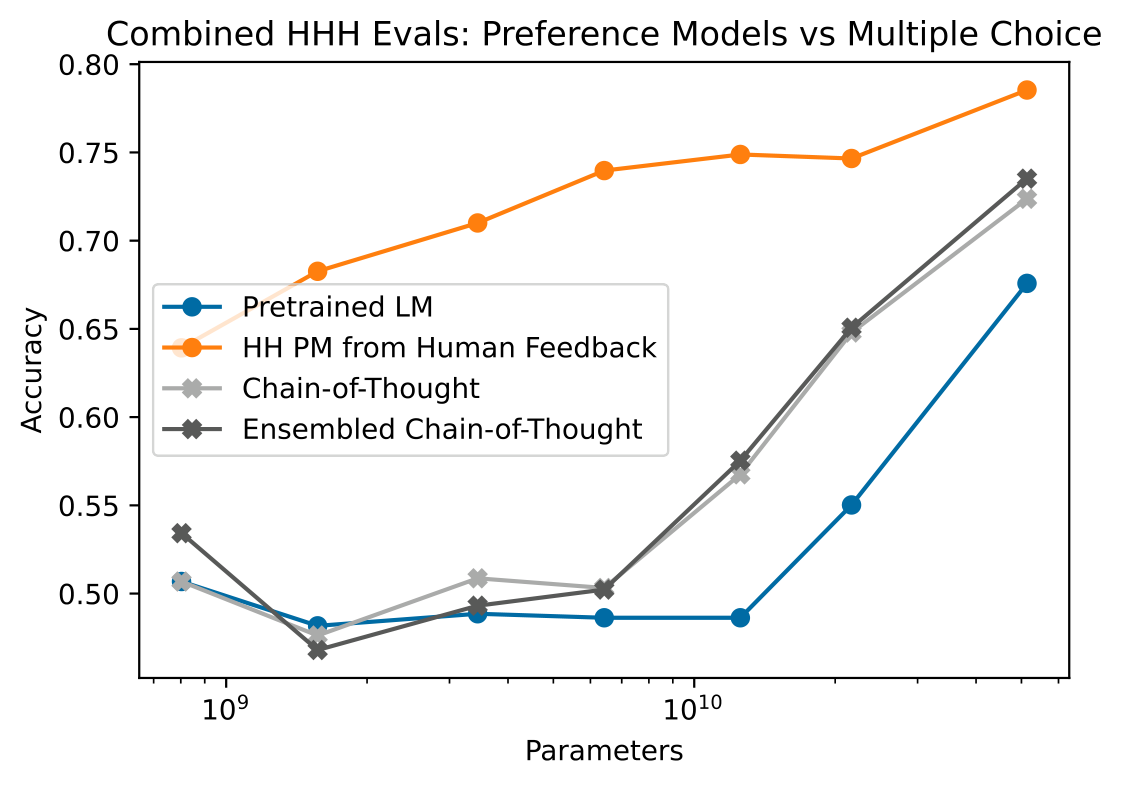
위 그림은 AI feedback이 인간 PM을 얼마나 대체할 수 있는지를 보여줌. 봐야 할 점은 모델이 커질수록 CoT/Ensembled CoT를 쓴 AI의 HHH 평가 정확도(약 0.72~0.73)가 인간 피드백으로 학습한 PM(약 0.78)에 근접한다는 것. 즉 충분히 큰 모델에서는 AI feedback만으로도 인간 PM에 버금가는 선호 신호를 얻을 수 있음.
Experiments
핵심 평가는 crowdworker가 매긴 helpfulness·harmlessness Elo로 모델들을 비교하는 것.
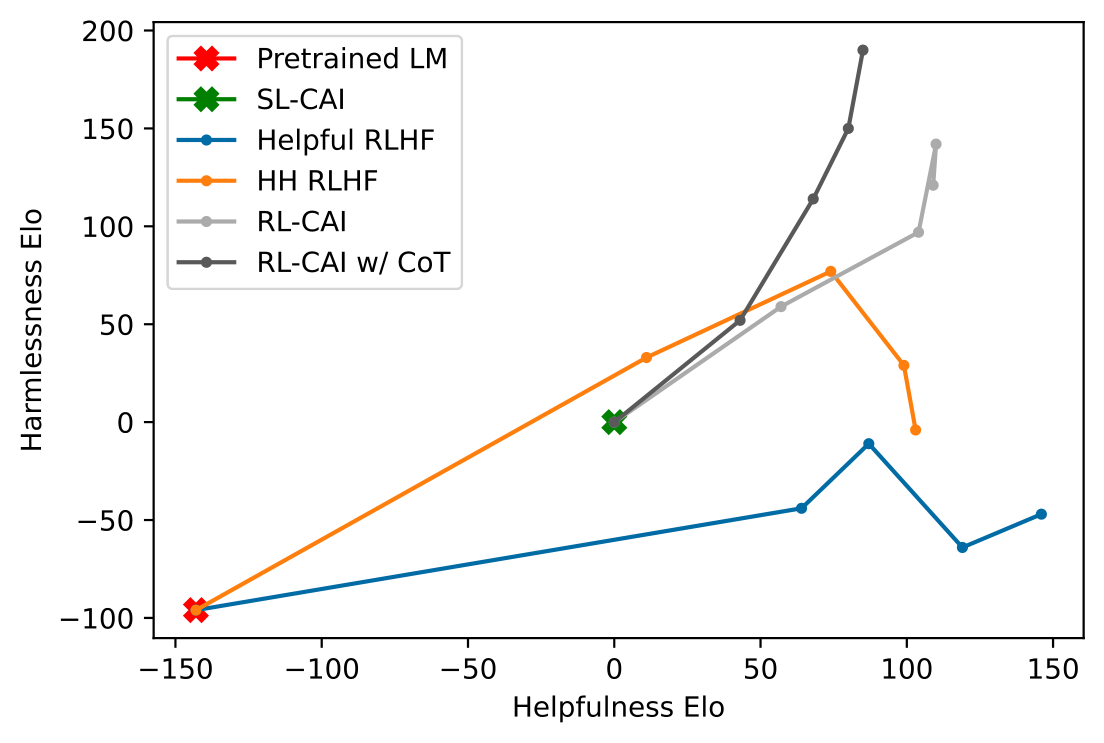
위 그래프가 이 논문의 대표 결과임. x축은 helpfulness Elo, y축은 harmlessness Elo이고, 오른쪽 위로 갈수록 좋음. 봐야 할 점은 세 가지. (1) Helpful RLHF(파랑)는 helpful하지만 harmlessness가 음수로 내려감. (2) HH RLHF(주황)는 어느 지점 이후 더 harmless해지려다 helpfulness가 도로 꺾여 오른쪽 아래로 휨 — 앞서 말한 trade-off. (3) RL-CAI와 특히 RL-CAI w/ CoT(회색·검정)는 오른쪽 위로 가장 멀리 뻗어, helpfulness를 유지하면서 harmlessness가 가장 높음. 즉 인간 harmlessness 라벨을 0개 쓴 RL-CAI가, 인간 피드백으로 학습한 HH RLHF를 두 축 모두에서 능가하며 Pareto frontier를 바깥으로 밀어냄.
정성적으로도 RL-CAI는 기존 HH 모델과 달리 거의 회피하지 않음. 민감하거나 유해한 요청에 “답할 수 없다”고 막는 대신 왜 그 요청이 문제인지 설명하면서 거절함 — harmless하면서 non-evasive하다는 본래 목표를 달성함.
정리
Constitutional AI는 (1) 인간 harmlessness 라벨 없이 자연어 원칙(constitution)만으로 감독을 압축하고, (2) self-critique·revision으로 SL 데이터를 합성하며, (3) AI가 만든 선호 라벨로 RLAIF를 돌려, harmless하면서도 회피하지 않는 assistant를 RLHF에 필적·상회하는 수준으로 학습함. 인간 감독을 “수만 개의 라벨”에서 “몇 개의 원칙”으로 옮긴 scalable oversight의 대표 사례이며, 이후 RLAIF·self-improvement 계열 연구의 토대가 됨.