Chat Vector - A Simple Approach to Equip LLMs with Instruction Following and Model Alignment in New Languages [2024]
Background
- LM의 대단한 진보에도 불구하고 오픈소스 데이터의 제한 등으로 인해 특징 지역의 언어 LM 개발 침체
- non-English LLM의 개발엔 상당한 resource 필요
Chat-Vector
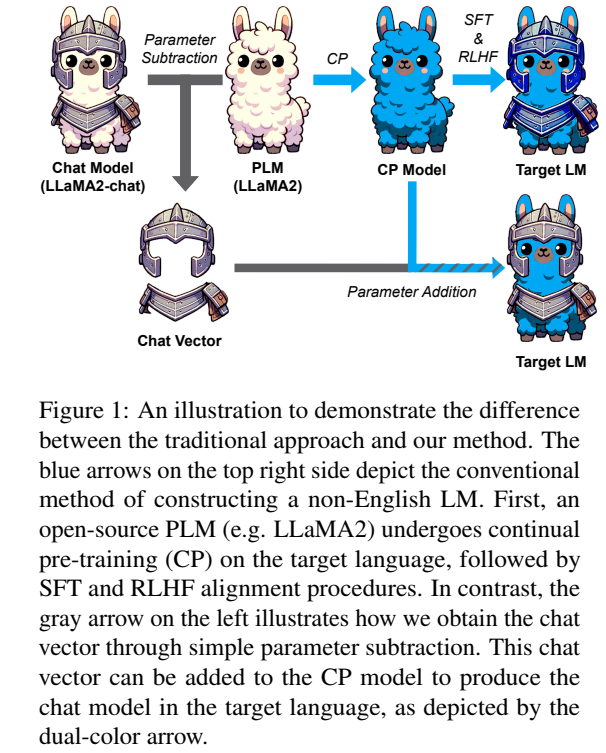
- non-English LLM을 처음부터 끝까지 개발하기엔 매우 많은 resource가 필요하기 결과적으로 Llama2, BLOOM과 같은 foundation model이 탄생
- Chat vector는 단지 base model에 상응하는 chat 모델로부터 사전학습된 base model의 가중치를 빼 만들어짐
- 특정 CP(continual pre-training) 모델에 target model의 언어 능력 + SFT 학습된 모델(informative model)의 task-specific한 instruction 능력
- 3가지 측면을 고려하여 특정 언어(논문에선 중국어) LM 생성
- toxicity
- instruction
- multi-turn dialogue
- CP
- 타겟모델에서의 모델의 이해능력과 생성능력을 강화시켜주기위해 사전학습모델을 초기화하고 타겟모델의 텍스트 데이터와 사전학습을 진행
- 다음은 다음 토큰을 예측하기 위한 모델의 loss definition
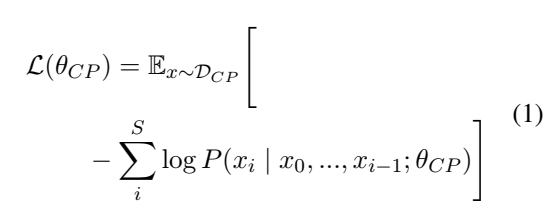
- Chat Vector
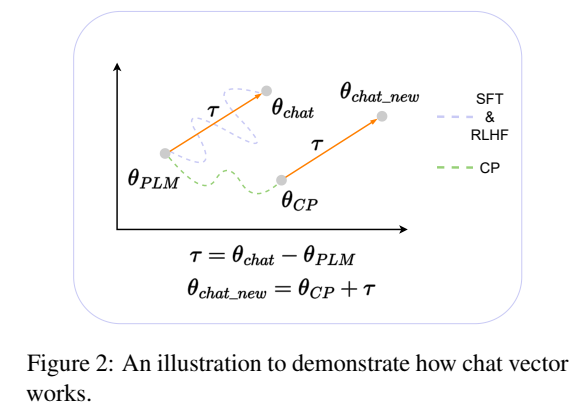
- 파인튜닝된 모델의 가중치를 기존 모델에서 뺌으로써 가중치 산출
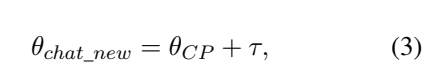
- 위 공식을 통해 얻어진 가중치를 각 원소끼리 더해줘서 최종 모델 완성
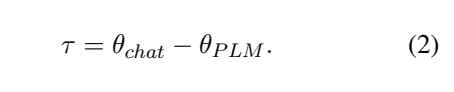
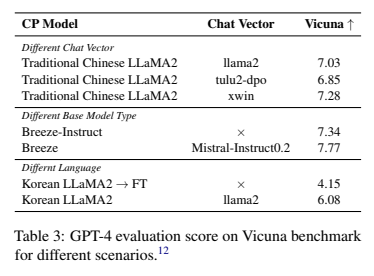
Performance
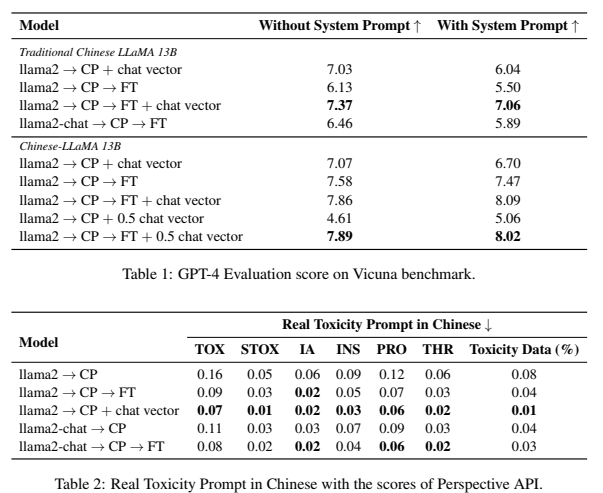
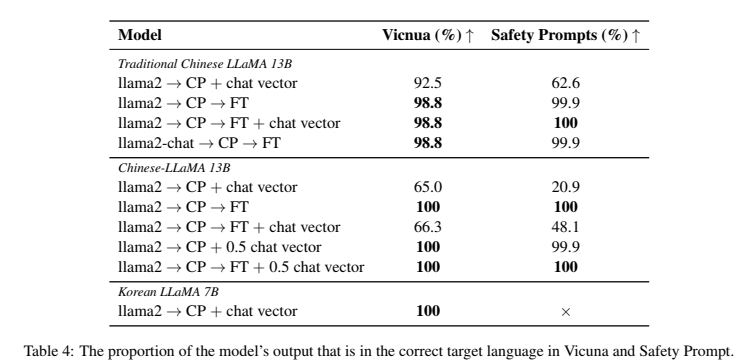
의의
- 간단하게 다양한 언어, IT 모델, task-spcific 모델간의 방법론적인 확장