Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing (AlphaLLM) [2024]
Introduction
Self-correction & self-learning 계열 LLM의 2가지 핵심 전략
- 모델 자신의 response를 이전의 response의 feedback에 근거하여 지속해서 재정의
- PPO나 DPO 방식으로 학습된 reward model을 통해 직접 response를 샘플링
그러나 LLM이 자신의 출력에 대해 효과적으로 비평하여 응답 품질을 향상시키거나 응답의 품질을 나타내는 scalar reward를 적용할 수 있는지는 특히 복잡한 계획 및 추론을 요구하는 상황에서 지속적인 연구 주제로 남아있었음. MCTS와 reinforcement learning을 통해 모델이 self-play하고 인간과 동등한 성능에 부합하며 심지어 게임과 같은 복잡한 task에서 인간을 능가하는 성능을 보여주었음. 이로 말미암아 self-improving하는 novel paradigm을 접목한 MCTS + LLM이 가능하지 않을까? 라는 자연스러운 질문이 제기되었음.
MCTS + LLM의 challenge
- Limited Data - 양질의 LLM을 위한 데이터가 필요로 함
- Search Efficiency - 다양한 token의 결합은 search space를 확장시킬것이고 이는 MCTS의 효율성에 악영향을 미칠 것
- Imperfect Feedback - AlphaGO의 명확한 win/loss feedback과 달리, LLM 분야에서의 feedback은 다소 주관적이고 미묘한 차이가 존재
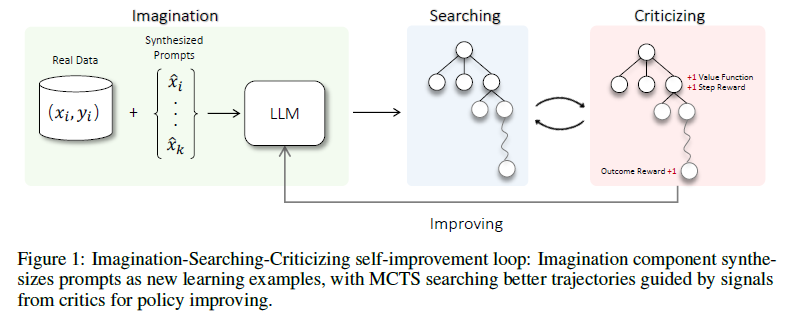
총 3개의 components로 이루어짐
- Imagination: Prompt들을 합성 & 데이터 부족 현상 완화
- ηMCTS: 언어모델 task에서 효율적인 searching / 특히 긴 시간 범위와 큰 행동을 가진 RL 문제에 대해 여러 수준의 시간적 추상화를 통한 계획이 중요하다는 것이 밝혀짐 / MDP(Markov Dicision Process) problem 옵션을 선택하여 text-generation process를 만들어내는 방법을 제시
- Critic Model(for ηMCTS): 향후 reward를 측정하는 value function / LLM이 산술 계산 및 코드 실행과 같이 평가에 어려움을 겪는 복잡한 작업의 정확한 피드백을 보장하기 위해, 비평가에게 어떤 도구를 사용할지, 언제 사용할지, 효과적으로 사용하는 방법을 동적으로 결정할 수 있는 능력을 강화
Related Work
Search with LLM Feng et al. 2023 연구에서 MCTS 알고리즘을 결합한 LLM이 존재하나 search step을 좀 더 유연하게 수정하였으며 다수의 critic signal을 search process를 더 효율적으로 안내하게 하기 위해 병합
LLM Self-improving Self-improving의 중요한 부분은 좋은 response와 그렇지 못한 것에 대한 잘 분별하는 능력을 어떻게 얻을것인가 하는 문제입니다. 최초의 연구에서 이 문제를 잘 다루기 위해 LLM에 다양한 task에 대한 input query들과 그에 상응하는 output을 생성하도록 요청하였으며 그 이후 수작으로 직접 실증적인 rule에 의해 의존하였으며 그 이후의 연구에선 몇가지 원칙들을 정하고 guidance를 정해 LLM에 response의 품질 직접 평가하게 만들었습니다. 연구자들은 LLM이 input 데이터에 대해 직접 원칙들을 지정하길 원했습니다. 그러나 이를 위해서는 LLM이 각 특정 사례에 대해 이러한 원칙을 적용하고 올바른 판단을 내릴 수 있는 강력한 능력이 필요합니다. 이전 연구와는 달리, 우리는 LLM의 자기 개선을 위해 MCTS(Monte Carlo Tree Search)의 감독을 활용할 것을 제안합니다. MCTS의 output을 사용하여 LLM을 계속해서 훈련합니다. MCTS의 output은 기존의 sampling 데이터보다 더 품질이 더 좋기에 가능하며 이 품질의 차이는 LLM이 self-improving을 가능하게 만들어줍니다.
Preliminaries
Problem Formulation
LLM은 이전 토큰의 컨텍스트에 의존하여 각 토큰을 순차적으로 생성합니다. 정책은 Markov process이며 체인 룰로 조건부 확률 분포를 표현합니다.