(vLLM) When set `-tp>2` option, Not working inference
Environment
- python: 3.10
- nvidia-driver: 535.183.01
- cuda: 12.4
- torch: 2.4.0+cu124
- vllm: 0.6.3.post1
Problem
-tp>2flag option 사용했을 때, 모델이 메모리에 로드는 가능하나,v1/chat/completions/api 호출 시 답변을 생성하지 못하는 현상- 재부팅 후, 최초 실행시엔 잘 작동하나 모델을 off-load하고 재실행 했을때 답변 생성 불가
Script
python -m vllm.entrypoints.openai.api_server --model $MODEL_NAME --dtype bfloat16 --port 8081 -tp 2 --enforce-eager > "$LOGFILE" 2>&1
Error Message
INFO 03-12 06:00:54 logger.py:37] Received request chat-8eee432560b948a88f57fe4114e19ab8: prompt: '<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\n친절한 챗봇으로서 상대방의 요청에 최대한 자세하고 친절하게 답하자. 모든 대답은 한국어(Korean)으로 대답해줘.\n블랙홀에 대해 초등학생도 알기 쉽게 설명해주세요.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\n블랙홀에 대해 초등학생도 알기 쉽게 설명해주세요.<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n', params: SamplingParams(n=1, presence_penalty=0.0, frequency_penalty=0.0, repetition_penalty=1.0, temperature=0.7, top_p=1.0, top_k=-1, min_p=0.0, seed=None, stop=[], stop_token_ids=[], include_stop_str_in_output=False, ignore_eos=False, max_tokens=130985, min_tokens=0, logprobs=None, prompt_logprobs=None, skip_special_tokens=True, spaces_between_special_tokens=True, truncate_prompt_tokens=None), guided_decoding=GuidedDecodingParams(json=None, regex=None, choice=None, grammar=None, json_object=None, backend=None, whitespace_pattern=None), prompt_token_ids: [128000, 128006, 9125, 128007, 271, 108200, 104834, 24486, 102783, 245, 103850, 229, 43139, 27796, 126761, 101482, 21028, 127296, 19954, 82273, 113760, 123154, 101360, 108280, 104834, 102893, 108386, 124295, 13, 107036, 126958, 34804, 104008, 32179, 17155, 46295, 8, 43139, 126958, 34983, 59269, 246, 627, 105551, 114957, 124800, 19954, 112107, 84415, 102278, 111291, 49085, 102066, 21121, 123261, 58901, 114942, 34983, 92769, 13, 128009, 128006, 882, 128007, 271, 105551, 114957, 124800, 19954, 112107, 84415, 102278, 111291, 49085, 102066, 21121, 123261, 58901, 114942, 34983, 92769, 13, 128009, 128006, 78191, 128007, 271], lora_request: None, prompt_adapter_request: None.
INFO 03-12 06:00:56 metrics.py:349] Avg prompt throughput: 0.0 tokens/s, Avg generation throughput: 0.0 tokens/s, Running: 0 reqs, Swapped: 0 reqs, Pending: 0 reqs, GPU KV cache usage: 0.0%, CPU KV cache usage: 0.0%.
INFO 03-12 06:00:56 engine.py:290] Added request chat-8eee432560b948a88f57fe4114e19ab8.
ERROR 03-12 06:01:27 client.py:250] RuntimeError('Engine loop has died')
ERROR 03-12 06:01:27 client.py:250] Traceback (most recent call last):
ERROR 03-12 06:01:27 client.py:250] File "/data/envs/llm_test/lib/python3.10/site-packages/vllm/engine/multiprocessing/client.py", line 150, in run_heartbeat_loop
ERROR 03-12 06:01:27 client.py:250] await self._check_success(
ERROR 03-12 06:01:27 client.py:250] File "/data/envs/llm_test/lib/python3.10/site-packages/vllm/engine/multiprocessing/client.py", line 314, in _check_success
ERROR 03-12 06:01:27 client.py:250] raise response
ERROR 03-12 06:01:27 client.py:250] RuntimeError: Engine loop has died
CRITICAL 03-12 06:01:36 launcher.py:99] MQLLMEngine is already dead, terminating server process
INFO: 192.168.0.17:45520 - "POST /v1/chat/completions HTTP/1.1" 500 Internal Server Error
INFO: Shutting down
INFO: Waiting for application shutdown.
INFO: Application shutdown complete.
INFO: Finished server process [1064306]
[1;36m(VllmWorkerProcess pid=1064554)[0;0m WARNING 03-12 06:01:57 shm_broadcast.py:396] No available block found in 60 second.
/usr/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked semaphore objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
/usr/lib/python3.10/multiprocessing/resource_tracker.py:224: UserWarning: resource_tracker: There appear to be 1 leaked shared_memory objects to clean up at shutdown
warnings.warn('resource_tracker: There appear to be %d '
Solution
재부팅 이후 최초 실행시엔 잘 동작하기에 프로세스 찌꺼기가 남아 있어서 에러가 발생한다고 판단하여 여러 프로세스를 죽이는 명령어를 시도해봤으나 전혀 효과를 보지 못함
(#2466) vLLM Distributed Inference stuck when using multi -GPU, (#3974) [Bug]: LLM is not getting loaded on multiple GPUs but works fine on a single GPU 이슈를 참고하여 스크립트에 NCCL_P2P_DISABLE=1 환경변수 + --enforce-eager flag 추가해줬음에도 해결되지 못함
(#2728 )Mixtral GPTQ with TP=2 not generating output 이슈에 비슷한 현상 발견.
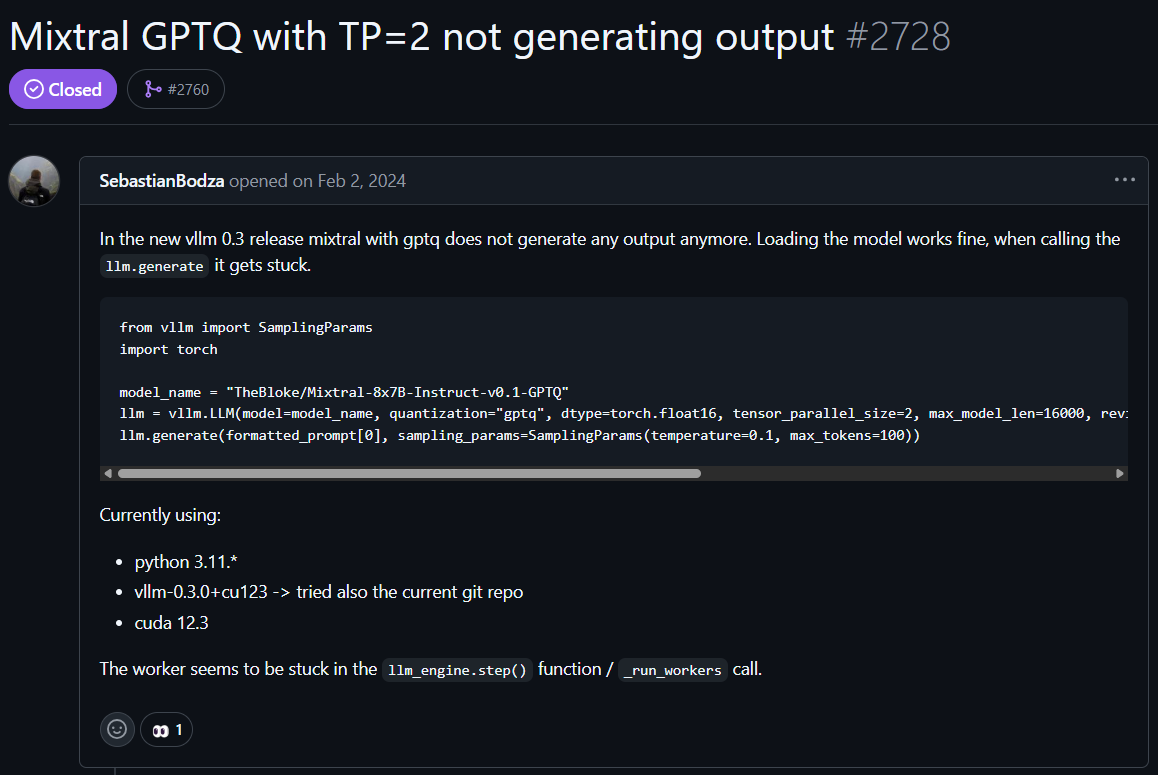
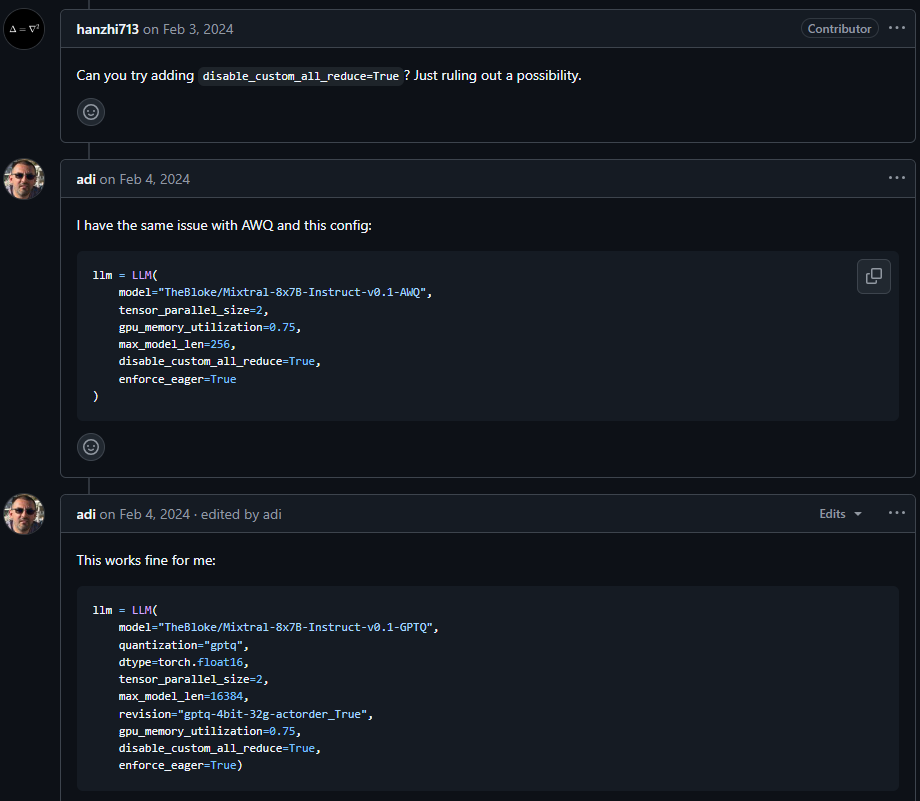
결국 disable-custom-all-reduce 옵션을 통해 해결할 수 있었음
Script
python -m vllm.entrypoints.openai.api_server --model $MODEL_NAME --dtype bfloat16 --port 8081 -tp 2 --enforce-eager --disable_custom_all_reduce > "$LOGFILE" 2>&1
What is disable-custom-all-reduce?
아래는 grok3의 답변을 발췌한 내용.
vLLM에서 `--disable-custom-all-reduce` 플래그는 분산 환경에서 GPU 간 통신을 최적화하는 데 사용되는 커스텀 `all-reduce` 연산을 비활성화하는 옵션입니다. 이 플래그의 역할과 배경을 이해하려면, 먼저 `all-reduce` 연산과 vLLM의 분산 처리 방식에 대한 기본적인 이해가 필요합니다. 아래에서 이 플래그에 대해 자세히 설명하겠습니다.
1. All-Reduce란 무엇인가?
all-reduce는 분산 컴퓨팅에서 자주 사용되는 집합 연산으로, 여러 노드(또는 GPU)에서 계산된 데이터를 모두 합치거나 특정 연산을 수행한 후, 그 결과를 모든 노드에 공유하는 작업을 의미합니다. 예를 들어, 딥러닝 모델 학습이나 추론에서 여러 GPU가 병렬로 계산한 그래디언트나 중간 결과를 하나로 통합할 때 사용됩니다. 일반적으로 NVIDIA의 NCCL(NVIDIA Collective Communications Library)이 이 연산을 효율적으로 처리하는 데 사용됩니다.
vLLM은 대규모 언어 모델(LLM)을 고속으로 서빙하기 위한 엔진으로, GPU 간 통신 효율성을 높이기 위해 기본적으로 NCCL을 사용합니다. 하지만 특정 상황에서 NCCL의 기본 구현보다 더 나은 성능을 제공할 수 있는 커스텀 all-reduce 구현을 제공합니다.
2. vLLM의 Custom All-Reduce
vLLM은 자체적으로 개발한 커스텀 all-reduce 구현을 통해 GPU 간 통신 성능을 최적화하려고 시도합니다. 이 커스텀 구현은 특히 NVLink(고속 GPU 간 연결 기술)를 지원하는 환경에서 성능 향상을 가져올 수 있습니다. NVLink는 GPU 간 데이터를 PCIe보다 훨씬 빠르게 전송할 수 있어, 통신 병목 현상을 줄이는 데 유리합니다.
커스텀 all-reduce는 다음과 같은 상황에서 유리할 수 있습니다:
NVLink 지원 환경: NVLink를 통해 GPU 간 직접 통신이 가능할 때, NCCL의 기본 토폴로지보다 더 효율적인 데이터 전송 경로를 설계할 수 있습니다.
특정 워크로드: vLLM의 워크로드(예: 긴 시퀀스 처리, 대규모 배치 크기)에서 NCCL의 일반적인 접근법보다 더 나은 성능을 발휘하도록 최적화되었습니다.
그러나 이 커스텀 구현은 모든 하드웨어 환경이나 소프트웨어 구성에서 잘 작동하지 않을 수 있습니다. 예를 들어:
NVLink가 없는 환경(PCIe만 사용하는 경우)에서는 성능 향상이 미미하거나 오히려 느려질 수 있습니다.
GPU 간 P2P(Peer-to-Peer) 통신이 제대로 지원되지 않는 경우(드라이버 문제 등) 실패할 가능성이 있습니다.
3. --disable-custom-all-reduce 플래그의 역할
--disable-custom-all-reduce 플래그는 vLLM이 커스텀 all-reduce 구현을 사용하지 않고, 대신 NCCL의 기본 all-reduce 구현으로 돌아가도록 강제하는 옵션입니다. 이 플래그를 사용하는 주요 이유는 다음과 같습니다:
(1) 호환성 문제 해결
NVLink 미지원 환경: 두 개 이상의 GPU가 PCIe로만 연결된 경우, 커스텀 all-reduce가 제대로 동작하지 않거나 성능이 떨어질 수 있습니다. 이 경우 NCCL로 전환하면 안정성이 보장됩니다.
P2P 통신 실패: GPU 간 P2P 통신이 하드웨어 또는 드라이버 문제로 지원되지 않을 때, 커스텀 all-reduce가 비활성화되도록 강제할 수 있습니다.
AMD GPU 사용: AMD ROCm 환경에서는 NVIDIA의 NVLink 및 NCCL 최적화가 적용되지 않으므로, vLLM은 자동으로 커스텀 all-reduce를 비활성화합니다. 이 플래그는 이를 명시적으로 설정하는 데 사용될 수 있습니다.
(2) 성능 디버깅
개발자나 사용자가 커스텀 all-reduce와 NCCL 간 성능 차이를 비교하고 싶을 때 이 플래그를 사용해 커스텀 구현을 끄고 테스트할 수 있습니다.
(3) 기본 동작 변경
과거 vLLM 버전에서는 커스텀 all-reduce가 기본적으로 활성화되어 있었으나, 2024년 2월경 GitHub PR(#2808)을 통해 기본값이 비활성화로 변경되었습니다. 따라서 최신 버전에서는 이 플래그를 명시적으로 설정하지 않아도 NCCL이 기본적으로 사용됩니다.
...
7. 결론
--disable-custom-all-reduce 플래그는 vLLM의 커스텀 all-reduce 최적화를 비활성화하고 NCCL의 기본 구현으로 전환하는 데 사용됩니다. 이는 주로 호환성 문제 해결, 성능 디버깅, 또는 특정 하드웨어 환경에서의 안정성 확보를 위해 필요합니다. 최신 vLLM 버전에서는 이미 기본값이 비활성화로 설정되어 있으므로, 특별한 경우가 아니라면 이 플래그를 명시적으로 사용할 필요는 줄어들었습니다. 그러나 여전히 특정 환경에서 문제를 해결하거나 테스트를 위해 유용하게 활용될 수 있는 옵션입니다.