LoftQ - LoRA-Fine-Tuning-Aware Quantization for Large Language Models [2023]
LoftQ
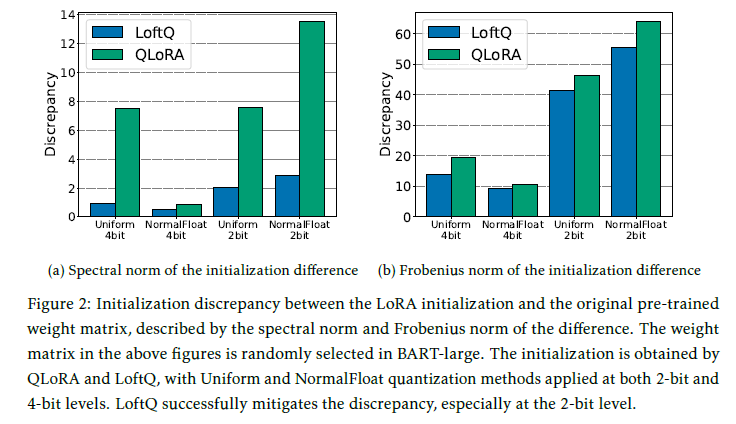
- LoftQ라고 불리는 새로운 quantization framework를 소개. 이 프레임워크는 낮은 순위의 근사치를 적극적으로 통합하여 양자화와 함께 작동하여 원래의 high-precision 사전학습된 가중치를 공동으로 근사화합니다.
Experiments
- Uniform Quantization: 클래식 quantization 방식. 연속적인 간격을 균일하게 간격을 2N 카테고리로 균일하게 나누고, de-quantization을 위한 로컬 최대 절대값을 저장
-
NormalFloat4 & 2-bit variant NormalFloat2: QLoRA논문에서 제안한 quantization 방식. high-precision이 가우스 distribution에서 추출된다고 가정하고 에서 추출한 high-precision을 동일한 확률을 갖는 이산 슬롯에 매핑
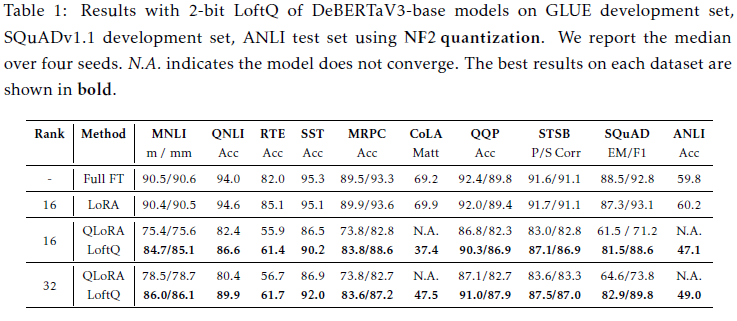
- 총 3가지 모델에 대해서 실험 진행
- Encoder-only model - DeBERTaV3
- GLUE, SQuADv1.1 ANLI benchmark 수행
- quantization방식과 lora rank, learning rate값을 수정해가며 ablation study
- 결과적으로 LoftQ가 꾸준하게 강건하고 사전학습된 가중치를 보존하면서 효율적으로 performance를 향상시키는 것을 발견
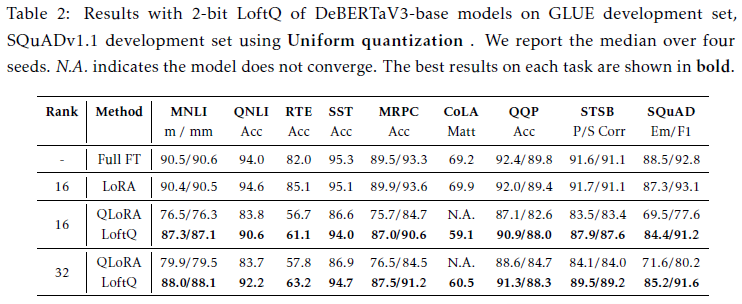
- Encoder-Decoder Model - BART
- MHA, FFN의 인-디코더 레이어에 LoftQ방식을 통해 weight matrices 적용
- XSum, CNN/DailyMail benchmark 수행
- LoftQ surpass full precision LoRA at both ranks on 8, 16
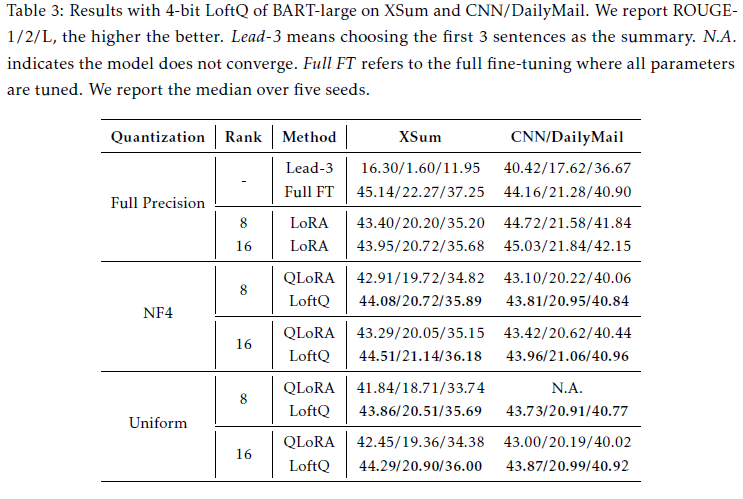
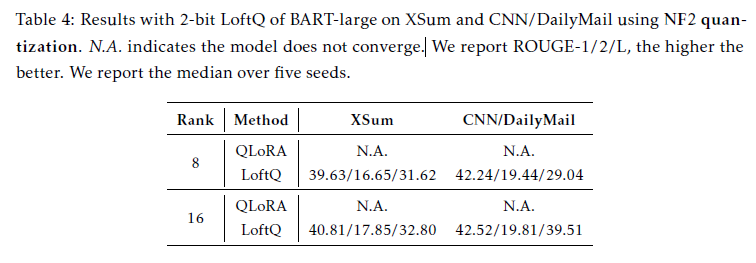
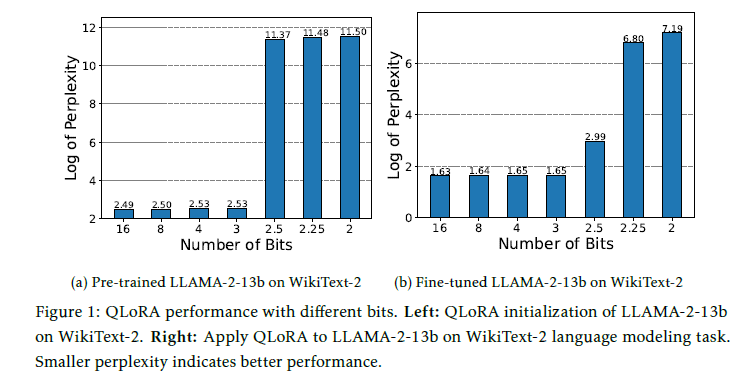
- Decoder-only Model - LLAMA2 (7b & 13b)
- NLG, GSM8K, WikiText-2(ppl) benchmark 수행
- 위와 유사하게 MHA, FFN의 모든 레이어에 LoftQ방식을 통해 가중치 행렬 적용
- WikiText-2 benchmark에서 꾸준하게 QLoRA를 뛰어넘음
- QLoRA 2bit-precision은 수렴에 실패했으나 LoftQ는 7.85의 ppl을 달성
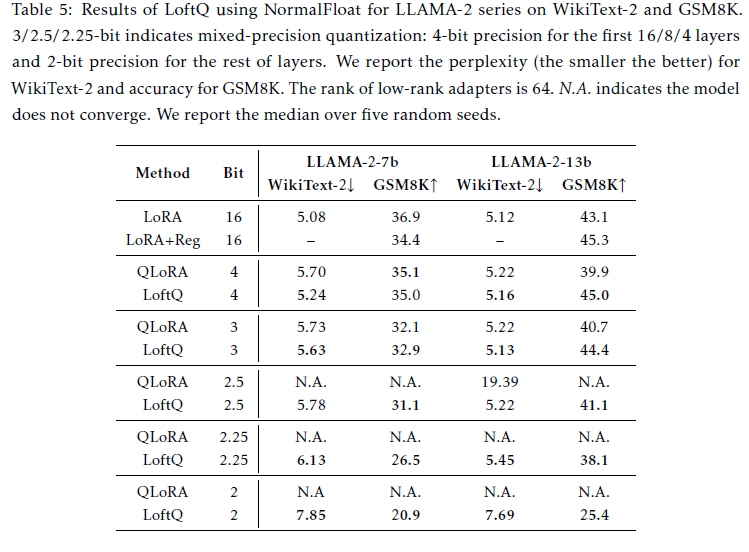
- GSM8K benchmark에서 LLAMA2-13b 모델이 full-precision LoRA를 뛰어넘음
- full-precision LoRA Fine-tuning시, 규제의 lack이 과적합을 야기한다는 것을 시사
- Table5에 나타난 regularization이 13b full-precision LoRA FT 성능을 이끌어냈으나 7b 모델에선 실패하였음. 즉, 13b 모델이 과적합에 취약하며, 양자화에는 이러한 과적합을 극복하기 위한 암시적 정규화 기능이 있음을 나타냄
- 성능과 정확도간의 커스텀화된 trade-off관계를 제공하기 위해 연구진은 또한 첫 4개의 레이어에선 4bit를 사용한 mixed-precison, 그리고 나머지 행렬에 대해선 2bit를 적용하였음. 그 결과 7b GSM8K에서 7b모델에선 5.9%의 성능향상이 나타났고 13b모델에선 12.7%의 성능이 향상
- Analysis
- 최적의 alternating step $T$ 값을 찾기 위한 실험 진행
- 특정 포인트아래로 alternating step이 증가하면 성능이 감소하는 경향이 나타남. 이 현상은 갭이 작아질수록 alternating optimization이 각 단계에서 일관되게 갭을 최소화하기가 더 어려워지기 때문에 발생하는 것으로 추정됨. 이러한 문제는 양자화 반식에 내재된 오류 때문에 발생. 그럼에도 부룩하고 LoftQ 연구진의 방법이 alternating step T에 민감하지 않으며 downstream task fine-tuning 성능을 일관되게 향상시킬 수 있음을 보여줌
결론
- 다양한 benchmark에서 성능 측정을 해본 결과, QLoRA method를 앞질렀으며 encoder-only, encoder-decoder, decoder-only 모델에서 강건한 성능을 나타냈음. 게다가 연구진의 양자화 framework는 낮은-bit quantization에서 특히 강건하며 효율적임
Appendix
GLUE with 4-bit
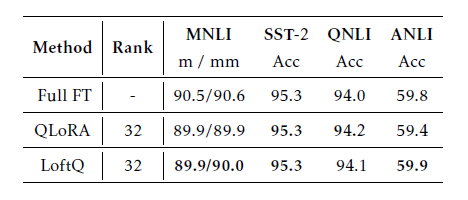
- full-finetuning 모델과 비슷한 성능을 기록
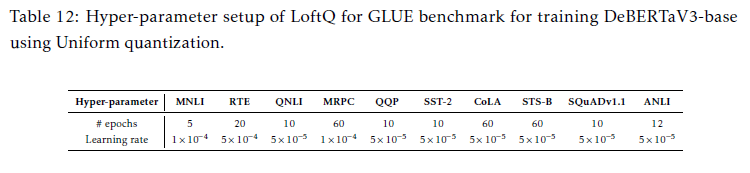

- learning rate: {1e-5, 5e-5, 1e-4, 5e-4}
- uniform quantization & nf2 quantization
- batch size: 32
- 5 iteration (LoftQ)
- table12는 nf2 적용한 DeBERTaV3-base 모델
Summarization
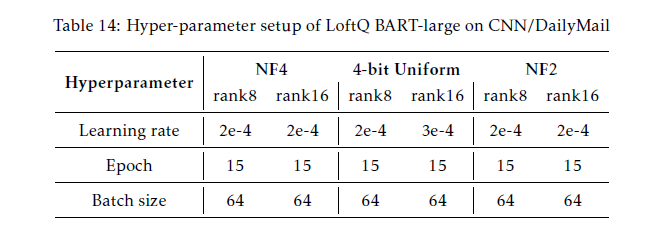
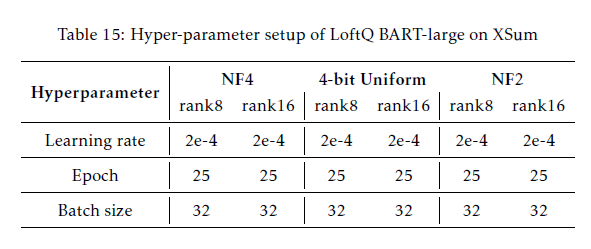
- Optim: Adam
- learning rate: {1e-5, 5e-5, 7e-5, 2e-4, 3e-4, 4e-4}
- 1 iteration (LoftQ)
- model: BART-large
NLG
- learning rate: {1e-5, 5e-5, 7e-5, 1e-4, 3e-4, 4e-4}
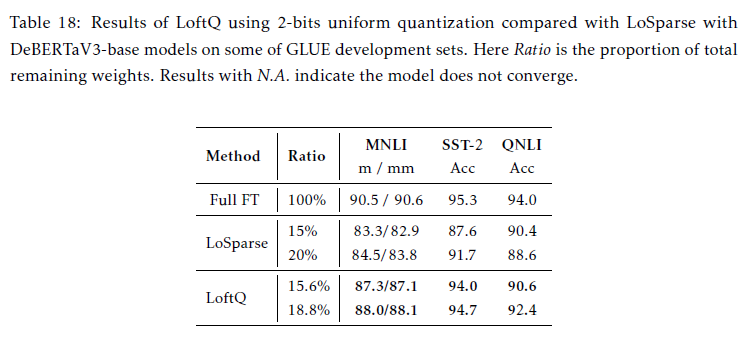
Pruning 비교
- SOTA pruning Losparse와 비교 실험
- LoftQ는 학습과 저장소의 메모리가 모두 꾸준하게 감소, 대조적으로 pruning은 전체적인 full-precision matrix를 필요로하며 이는 학습 stage동안 어떠한 메모리 감소가 이루어지지 않았음