EfficientNet - Rethinking Model Scaling for Convolutional Neural Networks [2020]
Introduction
그간의 scale up 방법은 detph, width, resolution (image size)을 증가시켜주는 방법이긴 하지만 정확도와 효율성 측면에선 그렇게 좋은 방법이 아니라고 논문의 저자는 주장하고 있음.
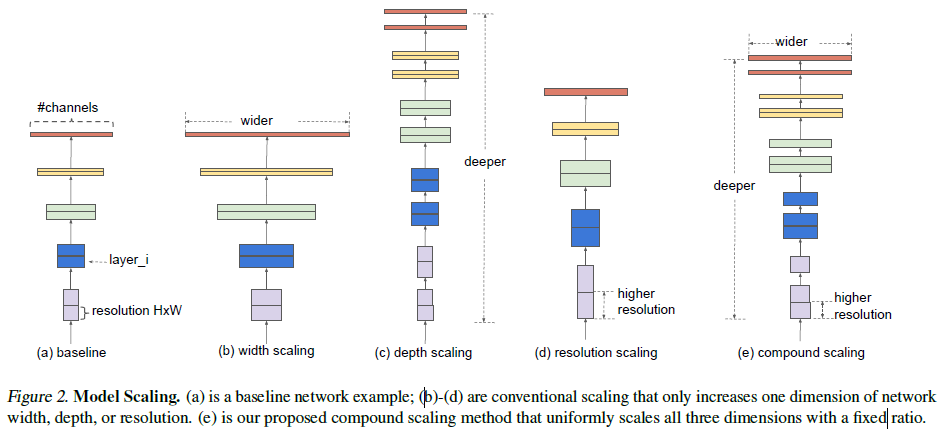
ConvNets의 scale up 방법을 다시 생각하고 연구한 결과, 균일한 scaling 방법을 제안. 만약 이미지 사이즈가 커지면 network는 receptive field와 더 많은 channel을 더 큰 이미지와 잘 맞게 하기 위해 많은 레이어를 필요로 할 것. 이전의 이론적인 연구와 empirical 연구를 통해 두 이론은 서로 연관이 있음이 밝혀졌음.
scaling method는 특히 baseline network에 매우 의존적인데 연구진은 새로운 baseline network를 개발하여 이를 EfficientNets이라고 부르기로 하였음.
Related Work
ConvNet Accuracy
AlexNet 이후로 수 많은 아키텍쳐를 갖는 모델들이 등장했고 많은 downstream task에 있어서 높은 정확도를 뽑았지만 하드웨어의 한계에 봉착했고 이에 따라 더 높은 정확도는 더 높은 효율성을 요하게 되었음.
ConvNet Efficiency
mobile에서도 돌아가는 여러 가지 모델이 탄생하였으나 비싼 튜닝 비용과 이를 실전에 적용하는 문제에 봉착하였고 이에 연구진은 모델의 효율성에 포커싱하여 연구를 진행하였고 model scaling을 재정의하였음.
Model Scaling
ResNet의 경우 scale down(ResNet-18) 또는 network depth를 조정하여 scale up(ResNet-200)한 경우가 존재함. 그러나 여전히 ConvNet을 어떻게 하면 효율적이고 정확도 높게 학습시킬 수 있을까? 라는 의문점이 존재함. 이에 본 연구진은 공학적이며 실증적인 연구를 통해 ConvNet을 width, depth, resolution의 차원을 모두 높이는 scaling 방법을 연구하였음.
Compound Model Scaling
Problem Formulation
ConvNet은 종종 다수의 stage로 나누며 각각의 stage에서 모든 레이어들은 같은 아키텍쳐를 갖는다. 예를들면, ResNet은 5개의 stage를 가지고 있고 다운샘플링하는 첫번째 레이어만 제외하고 모두 같은 Conv 타입을 갖는다. 그러므로 ConvNet을 다음과 같이 정의할 수 있다.
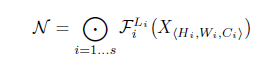
- $F_{i}^{L_i}$는 $F_i$ 레이어를 $L_i$ 만큼 반복
- $(H_i, W_i, C_i)$ ==> Input Tensor, Image Channel을 의미
최초 input_shape은 (224, 224, 3) » 최종 output_shape은 (7, 7, 512)
레이어($F_i$)의 변화 없이 model scaling을 legnth($L_i$)와 width($C_i$), resolution($H_i$, $W_i$)의 확장만으로 실행하였음. design space를 더 줄이기 위해 연구진은 모든 레이어들을 일정한 비율로 제한하였음. 연구진의 목표는 정확도를 최대화하며 문제들에 대해 최적하하는 방향.
Scaling Dimensions
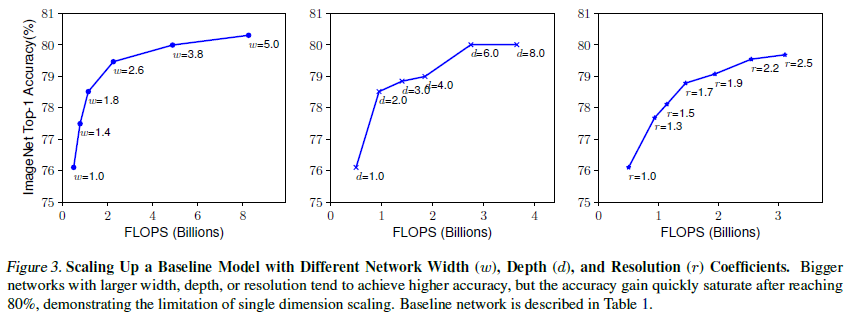
Depth($d$) : 더 깊은 ConvNet은 값비싸며 더 복잡한 특징을 가지고 새로운 task에 대해 더 잘 일반화 할 수 있음. 그러나 깊은 네트워크는 또한 vanishing gradient문제 때문에 학습하기 어려움. 비록 ResNet에서 쓰인 skip_connection과 같은 테크닉과 batch_normalization으로 학습 문제를 완화할 수 있지만 매우 깊은 네트워크는 정확도가 감소할 것임 (ResNet-1000이 ResNet-101과 비슷한 정확도를 보이는 것과 같음). Figure3 가운데 이미지 참고
Width($w$) : Scaling 네트워크 width는 주로 규모가 작은 모델에서 사용되어짐. 폭넓은 네트워크는 특징을 더 잘 캐치하고 학습하기 쉬운 특징을 지니는 경향이 있지만 더 높은 level의 특징은 잡지 못하는 단점이 존재함. 연구진의 실증적인 결과는 Figure 3의 왼쪽에 나타나며 네트워크가 더 큰 $w$ 값을 가짐에 따라 정확도가 매우 빠르게 saturate됨을 밝혀냈음.
Resolution($r$) : 보통 resolution이 높으면 당연히 좋은 결과를 얻지만 매우 높은 resolution (600, 600) 같은 경우엔 정확도가 떨어짐.
Observation1 : 네트워크의 width, depth, resolution의 scaling up이 performance에 긍정적인 영향을 주지만 사이즈가 큰 모델에선 정확도가 감소할 수 있는 경향이 존재함.
Compound Scaling
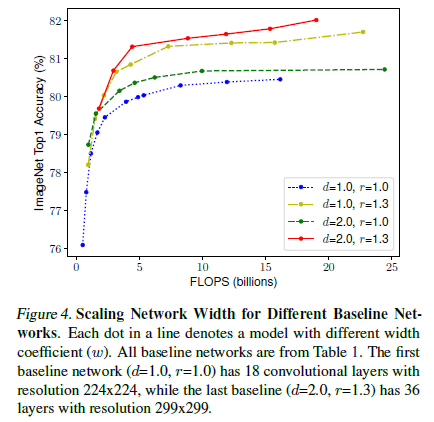
연구진은 경험적으로 서로다른 scaling dimension들이 독립적이지 않음을 밝혀내음. 높은 해상도의 이미지(resolution)를 사용할 때, 연구진은 네트워크의 depth를 더 크게 적용하였음. 더불어서 resolution이 높을 수록 width를 더 증가였음. 기존의 단일 차원 스케일링이 아닌 다양한 스케일링 차원을 조정하고 균형을 맞출 필요가 있음을 시사합니다.
$depth$, $resolution$ 값의 스케일링 없이 $width$ 값만 스케일링 한다면 Figure 4와 같이 정확도는 빠르게 saturate되었음. 더 깊고($d$ = 2.0) 더 높은 해상도($r$ = 2.0)의 scaling 결과, 같은 FLOPS cost + 더 높은 정확도의 결과로 나타났음.
Observation2 : 더 나은 정확성과 효율성을 추구하기 위해서는 네트워크의 모든 차원을 균형 있게 조정하는 것이 중요합니다.
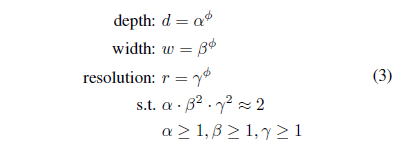
위와 같은 새로운 compound scaling method 방식을 제안.
$\phi$ 값은 user-specified coef이며 이는 모델 스케일에 따라 더 많은 resource를 사용할 수 있게 해줌.
EfficientNet Architecture
모델 스케일링은 베이스라인 network에서 layer operator $F_i$를 바꾸지 않기에 좋은 베이스라인 network는 또한 좋게 작용할 수 있음. 우리는 기존 모델을 사용하긴 했지만 연구진의 스케일링 방법의 효율성을 더 피력하기 위해 또한 새로운 mobile-size 베이스라인을 개발하였으며 이를 EfficientNet이라 부르겠음.
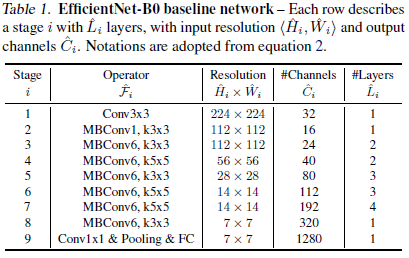
Table 1에 EfficientNet-B0의 구조가 나타나있고 main building block은 MBConv를 변환하였으며 추가적으로 squeeze-and-exitation optimization을 적용하였음. 여기에 연구진의 compound scaling method를 2개의 step에 걸쳐 적용하였음.
- STEP1:
- $\phi == 1$, $\alpha = 1.2$, $\beta = 1.1$, $\gamma = 1.15$, 각각의 squared 값이 2가 안넘게!
- STEP2:
- $\alpha$, $\beta$, $\gamma$ 값을 고정하고 Equation 3을 적용해 다른 $\phi$ 값과 함께 베이스라인 network를 scale up 하였음
Experiments
Scaling Up MobileNets and ResNets
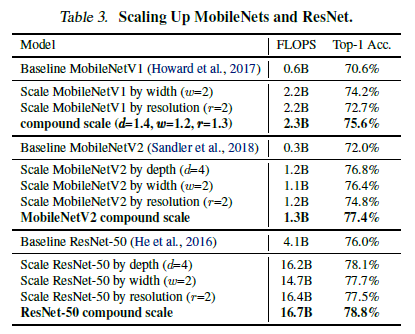
PoC 차원에서, 연구진의 scaling method를 MobildNets, ResNet에 적용하였음.
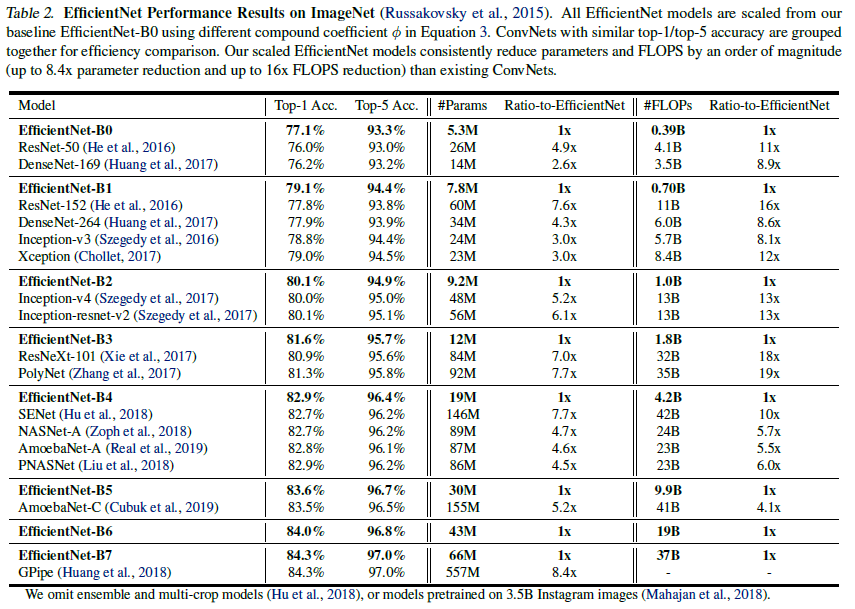
ImageNet Results for EfficientNet
SiLU 활성화 함수 사용하였으며 dropout은 EfficientNet-B0에서 B7 모델까지 0.2 ~ 0.5 값을 선형적으로 증가시켜줬음. 또한 25k 개의 데이터를 무작위로 선택하여 학습셋과 minival 셋을 만들었고 early_stop_checkpoint을 통해 기존의 validation셋에 적용시켜 validation 정확도를 산출해냈음.
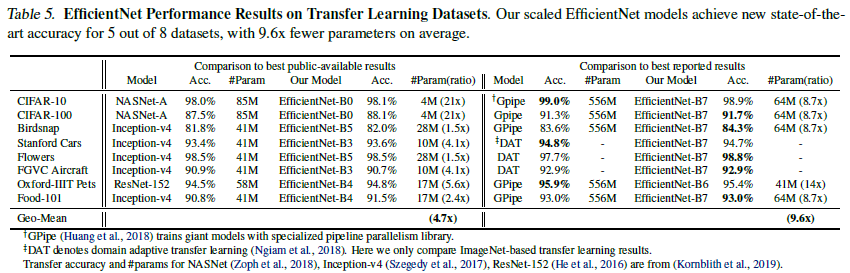
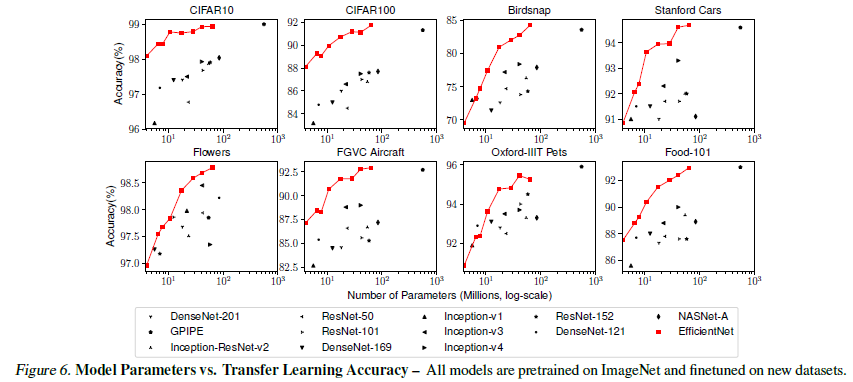
Transfer Learning Results for EfficientNet
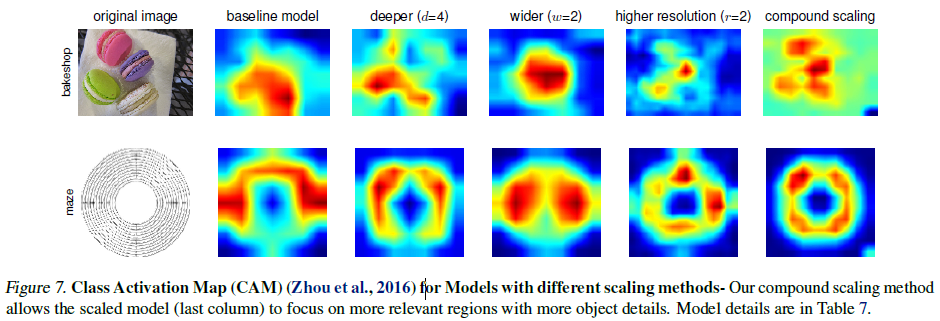
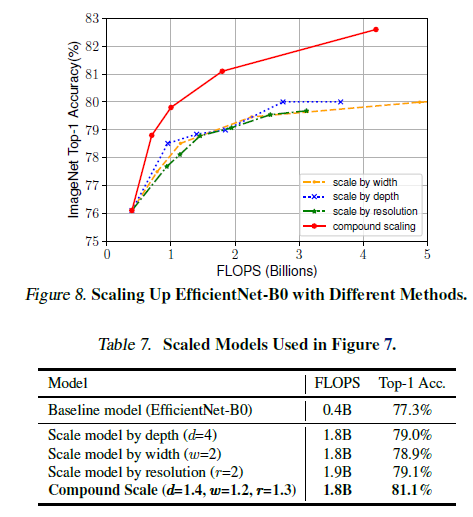
Table 6에 나타난 대표적인 데이터셋에 모델 평가를 진행하였음. 또한 새로운 데이터셋에 파인튜닝도 진행.
Discussion
Figure 8에 나타나 있듯이, 연구진의 scaling 방법과 다른 scaling method의 성능 차이를 확인 할 수 있음. 일반적으로 모든 scaling method는 정확도를 높여주고 FLOPS를 낮춰줌. 그러나 연구진의 compound scaling method는 더 높은 정확도를 기록함.
연구진의 compound scaling method가 어떻게 더 높은 performance를 기록할 수 있었는지 연구하기 위해 Figure 7의 activation map을 구성하였음. 이미지는 무작위하게 ImageNet validation set에서 선택 되었음. figure에서 보다시피, 연구진의 scaling method는 좀 더 연관되어있는 지역에 집중하려는 경향이 보임. 반면에 다른 모델들은 객체의 결핍 또는 이미지 내의 모든 객체들에 대해서 잡아내지 못함.
의의
- 특정한 scaling method를 통해 높은 정확도와 낮은 FLOPS을 기록
- 연산 측면에서도 매우 훌륭함
- scaling-law 측면에서 앞으로의 연구가 기대되는 논문이다