EfficientNetV2 - Smaller Models and Faster Training [2021]
Introduction
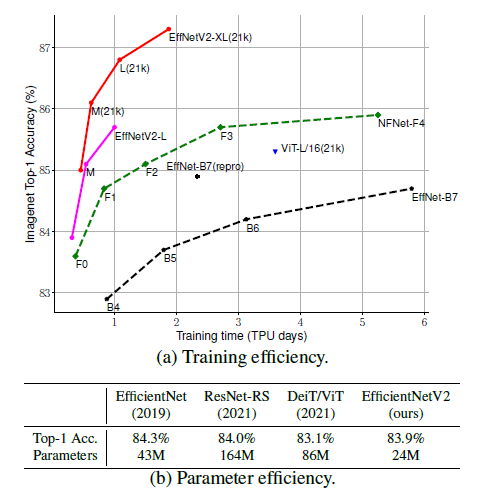
최근 학습 효율성은 정말 큰 중요한 맹점임. ConvNets에선 attention layer를 합성곱 신경망에서 추가하여 학습 속도를 올리는데 집중하였음. ViT는 Transformer block을 사용함으로써 큰 스케일의 데이터셋을 사용할때 학습 효율성을 증가시키기도 하였음. 그러나, 파라미터 수가 너무 크기에 resource가 너무 비쌈.
이에 연구진은 training-aware의 NAS(neural architecture search)의 결합 + 학습속도와 파라미터효율성을 향상시키기위한 scaling를 사용함.
이전 연구에서 알아낸 점
- 매우 큰 이미지의 사이즈는 학습을 느리게 함
- depthwise conv는 초기 레이어에서 느림
- 동등하게 매 stage에서의 scaling up은 차선책
이러한 관점에서, Fused-MBConv와 같은 추가적인 ops와 함께 search space를 구성했고 training-aware NAS를 적용했음. 또한 모델 정확도, 학습속도, 파라미터 사이즈를 동등하게 최적화하기 위한 scaling도 진행.
연구진의 학습은 이미지 사이즈를 학습동한 점진적으로 증가시킴으로써 점차 속도가 올라갔음. 점진적인 resizing을 FixRes, Mix&Match와 같은 많은 사전 연구에서 더 작은 이미지를 학습시에 사용했으나 모든 이미지의 사이즈에 대해 같은 규제를 가하여 정확도를 떨어뜨리곤 했음. 이에 연구진은 다른 이미지 사이즈에서 같은 규제를 유지시키는건 그다지 이상적이지 않은 방법론임을 밝혀냈음. 큰 사이즈를 가진 이미지는 overfitting 방지를 위해 더 강한 규제를 필요로 함. 이러한 연구를 통해 progressive learning 방법을 제안. 작은 이미지 사이즈엔 약한 규제(dropout or augmentation)를 사용한 후에 점차 이미지 사이즈와 더 강한 규제를 증가시켰음. 이전 연구에서도 pregressive resizing을 시도했었으나 우린 정확도 drop 없이 학습 속도를 높일 수 있었음.
Related Work
Progressive Training
transfer learning, GANs, adversarial learning, LM과 같은 연구에서 학습 셋팅이나 network를 급격하게 바꿔 조금 다른 형태로 progressive training을 연구한 사례가 있음. Progressive resizing Howard, 2018은 대개 본 연구와 연관이 있고 학습 속도를 높이려 했음. 그러나 정확도 drop 좀 있었음. 다른 비슷한 연구는 Mix&MatchHoffer et al., 2019이며 각 batch마다 무작위하게 다른 이미지 사이즈를 샘플링하였음. 앞서 소개한 두 연구 모두 모든 이미지 사이즈에 모두 같은 규제를 사용하였고 이에 정확도 drop이라는 결과를 낳았음. 연구진은 좀 다른 형태로 규제를 가할 뿐만 아니라 학습 속도와 정확도를 향상시켰음.
Neural acrchitecture search (NAS)
네트워크 구성 process를 자동화함으로써 NAS는 image classification, Object Detection, segmentation task에서 network 구조를 최적화하곤 했음. 대개 NAS 연구는 FLOPs 효율성이나 inference 효율성에 대해 집중되어졌음. 그러나 이전 연구 방향과 달리, 이 논문에서는 NAS를 학습과 파라미터 효율성을 최적화하는데 사용했음.
EfficientNetV2 Architecture Design
- training-aware NAS
- scaling
- EfficientNetV2 model
Review of EfficientNet
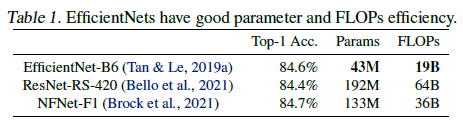
최근 다른 연구에서 학습 또는 추론 속도를 큰 모델에서 얻을 수 있다곤 하는데 파라미터와 FLOPs의 효율성 관점에서 EfficientNet보다 성능이 안좋다. 본 논문에서 연구진은 파라미터 효율성을 유지하면서 학습 속도를 높이는에 집중하였다.
Understanding Training Efficiency
생략
Depthwise convolutions are slow in early layers but effective in later stages
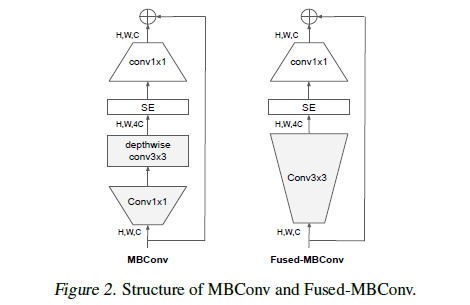
EfficientNet의 학습 병목현상은 확장된 Depthwise Convolution으로부터 야기되었음. DC는 일반적인 convolution보다 더 적은 파라미터와 FLOPs를 가지고 있음. 그러나 종종 완전히 accelerator에서 활성화 되지 않음. 최근 Fused-MBConv가 Gupta & Tan, 2019 제안되었고 후에 다른 연구에서도 쓰였으며 mobile 또는 서버 accelerator에서 더 잘 활용되어지는 것을 확인했음. MBConv에서의 depthwise conv3x3 + expansion conv1x1 를 단일의 regular Conv3x3으로 대체 할 수 있음. 이 2개의 block을 구조적으로 비교하기위해 EfficientNet-B4에서 orginal MBConv를 Fused-MBConv로 점차 교체하였음. 그 결과 좋은 성능을 이끌어냈고 MBConv와 Fused-MBConv를 적절하게 결합하는 것이 좋은 성능이 낸다는 것을 밝혀냈으며 적절합 조합은 이루어져야 할 듯.
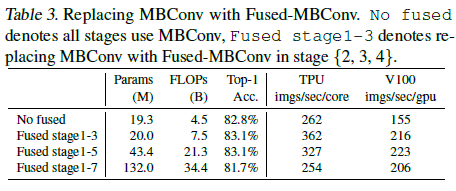
Equally scaling up every stage is sub-optimal
non-uniform scaling strategy를 사용하여 점진적으로 더 많은 레이어들을 추후의 stage에서 추가하는 전략을 사용. 추가적으로 EfficientNet은 매우 적극적으로 이미지 사이즈를 높였기에 memory를 많이 잡아먹고 학습 속도가 너무 느렸음. 이 이슈를 해결하기 위해 연구진은 scaling rule을 조금 수정하고 최대 이미지 사이즈를 제한하였음.
Training-Aware NAS and Scaling
NAS Search
Training-Aware NAS 프레임워크는 대개 이전의 NAS 연구에 기초하고 있으나 정확도와 파라미터 효율성, 학습 효율성을 동등하게 최적화 하는 방향임. 특히 backbone으로 EfficientNet을 사용하였음. 연구 범위는 stage기반의 factorized space로 이는 Conv operation type(MBConv, Fused-MBConv), kernel size(3x3, 5x5), expansion ratio(1, 4, 6)로 구성되어 있음. 반면에 pooling skip ops과 같은 불확실한 연구 옵션을 줄이거나 backbone의 channel size를 재사용함으로써 연구 범위를 줄일 수 있었음. 연구 범위가 더 좁기 때문에 reinforcement learning이나 더 큰 네트워크에서의 간단한 random search를 적용해 볼 수 있었음. 특히 1000개의 모델까지 샘플링하거나 학습시에 이미지 사이즈를 줄여 10epochs에서 학습해 볼 수 있었음.
EfficientNetV2 Architecture
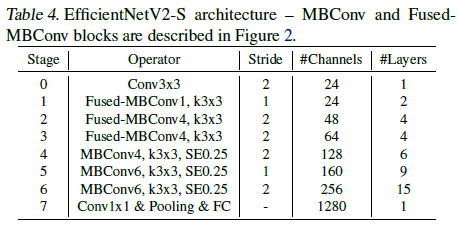
Backbone EfficientNet과 다른 점
- MBConv와 Fused-MBConv를 둘 다 사용했다
- 더 적은 expansion ratio는 메모리를 적게 쓰려는 경향이 있기에 MBConv에서 더 적은 expansion ratio를 선호한다
- 3x3 kernel size보다 더 적은 값을 선호하지만 더 적은 kernel size를 사용하는 결과로부터 보상을 얻기 위해 많은 레이어를 추가한다
- 메모리나 파라미터 이슈때문에 마지막 stride-1 stage를 제거하였다
EfficientNetV2 Scaling
몇 가지 최적화 작업을 추가
- 최대 추론 이미지 사이즈를 480으로 제한
- 속도에서 이득을 보기 위해 추후의 stage에선 몇개의 레이어를 더 추가 (Table4 참고)
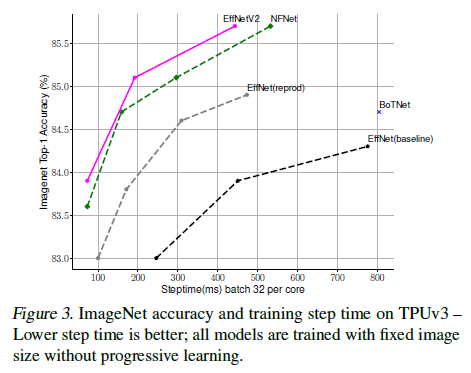
Training Speed Comparison
생략
Progressive Learning
Motivation
가설 - 정확도 감소는 unbalance한 규제로부터 발생한다
EfficientNet-B7은 dropout_rate = 0.5와 같이 B0 모델(0.2)보다 더 강한 규제를 사용하여 오버피팅을 방지함. 같은 네트워크에서라도 더 작은 이미지는 더 적은 네트워크 capacity를 요하며 따라서 더 약한 규제를 필요로 함. 그와 반대로 더 큰 이미지는 더 많은 연산을 사용하고 더 큰 capacity를 사용.
가설을 검증하기 위해 연구진은 모델을 학습했고 다른이미지 사이즈와 다른 데이터 증강방법과 함께 샘플링 했음. 이미지가 작아질때 약한 증강과 최고의 정확도를 기록했으나 큰 이미지에선 더 강한 증강을 시행했음. 이러한 insight로 말미암아 연구진은 적응적으로 학습시에 이미지 사이즈에 따라 규제를 조정하였고, 이는 progressive learning의 방법으로 이끌었음.

Progressive Learning with adaptive Regularization

Epoch이 적을땐, 더 적은 규제와 더 적은 사이즈의 이미지를 사용하여 모델을 학습하였음. 그러고나서 점차 이미지 사이즈를 증가시켰을 뿐만 아니라 더 강한 규제를 추가함으로써 학습을 더 어렵게 만들었음. 앞선 (Howard, 2018)의 연구와는 다소 다른점을 언급.

각 stage의 시작에서 네트워크는 모든 가중치를 이전의 stage로부터 상속함. 가중치(position embedding)들이 input length에 의존적인 Transformer와 달리 ConvNet의 가중치는 이미지 사이즈와 독립적이며 이에 따라 쉽게 상속받을 수 있음.
mainly three types of regularizations
- Dropout
- RandAugment
- Mixup
Main Results
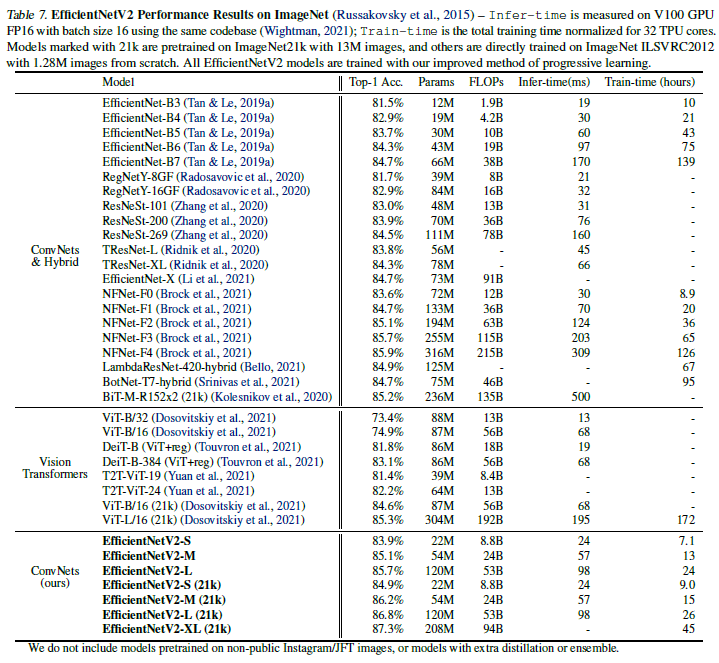
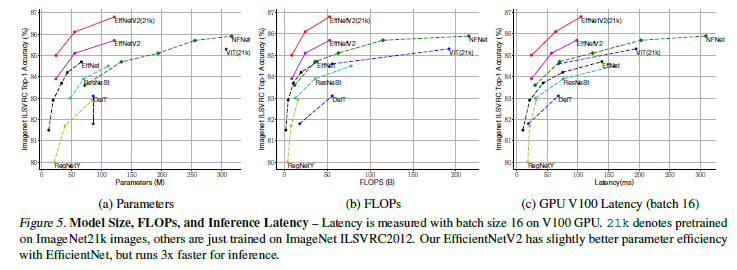
성능에 대한 내용으로 생략
Ablation Studies
Comparison to EfficientNet
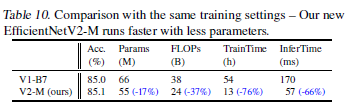
Progressive learning을 EfficientNet에 적용한 결과, 학습 속도와 정확도가 과거 연구했을 때보다 더 향상되었음. 그러나 V2 모델 만큼은 아니었음. V2모델은 전 모델에 비해 파라미터가 17% 줄었음에도 불구하고 FLOPs는 37% 더 낮았고 학습 속도는 4.1배 빨랐으며 추론 속도는 4.1배 더 빨랐음.
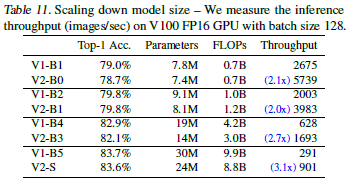
Scaling Down : 대개 큰 scale을 가지는 모델에 대해 집중하였음. 규모를 줄인 EfficientNetV2을 더 작은 모델과 비교해보자. 쉬운 비교를 위해, 모든 모델들은 progressive learning없이 학습되어졌음.
Progressive Learning for Different Networks
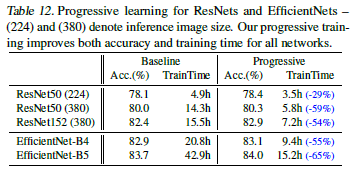
다른 네트워크 에서도 ablation study를 진행하였음. 위 결과는 baseline model과 ResNet을 비교한 결과임. 그 결과 학습시간에서 뚜렷한 차이를 보였으며 모델의 정확도 또한 소폭 증가하였음을 확인할 수 있다. 또한 더 확장성과 모델의 정확도를 위해 이미지 사이즈를 224에서 380으로 증가시켜 연구를 진행하였음.
Importance of Adaptive Regularization
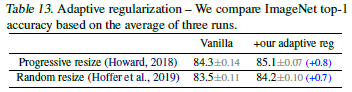
본 연구의 main insight는 Adaptive Regularization으로 이는 급격하게 이미지 사이즈 규격을 조정하는 방법. 본 논문에선 간결함을 위해 단순한 progressive approach을 사용하였지만 다른 접근법과도 결합할 수 있는 일반적인 방법을 사용할 수도 있음.
2가지 셋팅을 통해 Adaptive Regularization울 연구하였음.
- 이미지 사이즈를 점진적으로 증가
- 각각의 배치에서 다른 이미지 사이즈를 가진 데이터를 무작위하게 샘플링
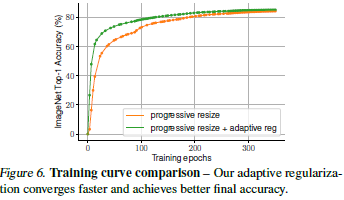
의의
- Regularization을 통해 모델 성능 향상. 더불어서 모델링 관점에서 구조의 변화를 시도
- 적은 파라미터를 가짐에도 가공할만한 성능을 뽑아냄
- 새로운 backbon 모델을 ideation 해냈음