GPT3 - Language Models Are Few-Shot Learners [2020]
그간 task-specific한 데이터셋의 필요, 파인튜닝을 통해 task-agnostic한 접근이 불가능했다. 이러한 한계점을 꺠고자 몇가지 method를 제안한다.
첫째, 실용적인 관점에서 매번 새로운 task에 대해서 항상 언어모델은 방대한 레이블된 데이터셋이 필요한 점이 한계였다. 특정한 task에 대해서 큰 지도학습 데이터셋을 수집하기란 여간 쉬운 일이 아니고 특히 이러한 과정을 매번 새로운 task에 적용시키기란 정말 어려운 일이다.
둘째, 학습데이터의 허위 상관관계를 악용할 가능성이 모델의 표현과 학습분포의 narrow와 함꼐 근본적으로 증가한다. 이로인해 사전학습과 파인튜닝 패러다임에 문제가 발생할 수 있다. 사전학습 중에 정보를 흡수할 수 있도록 모델을 크게 설계하지만 이후에는 매우 좁게 task 분포에 맞게 파인튜닝 되어진다. 이건 일반화하는 과정에서 불리하게 작용될 수 있는데 그 이유는 모델이 훈련 분포에 지나치게 특정되어 있고 그 외에는 잘 일반화되지 않기 때문이다. 따라서 특정한 benchmark에서 파인튜닝 모델의 performance는 아마 실제 performance보다 과장되어질 수 있다.
세번째, 인간은 대부분의 언어 task에서 큰 지도학습 데이터를 필요로 하지 않는다. 자연어안에서의 간단한 지시(“뭔가 행복한 듯한 문장을 묘사해주세요” 와 같은)나 기껏해야 매우 적은 demonstration(“여기 사람들이 용감하게 행동하는 두 가지 예시가 있음, 이 다음으로 용감한 예시를 하나 줘봐”와 같은)은 종종 최소한의 합리적인 수준의 역량순에서 새로운 task에 대해 효율적으로 실행할 수 있다. 현재 NLP 기술속에서 개념적인 한계 외에도 이런 접근성은 실용적인 이점을 가진다. 이건 사람들로 하여금 함께 원활하게 섞이게 해주며 많은 task과 기술들 사이에 잘 바뀔수 있게 해주는 것이다. 예를들면 긴 대화 중에 덧셈을 수행하는 대화와 같은 것들 말이다.
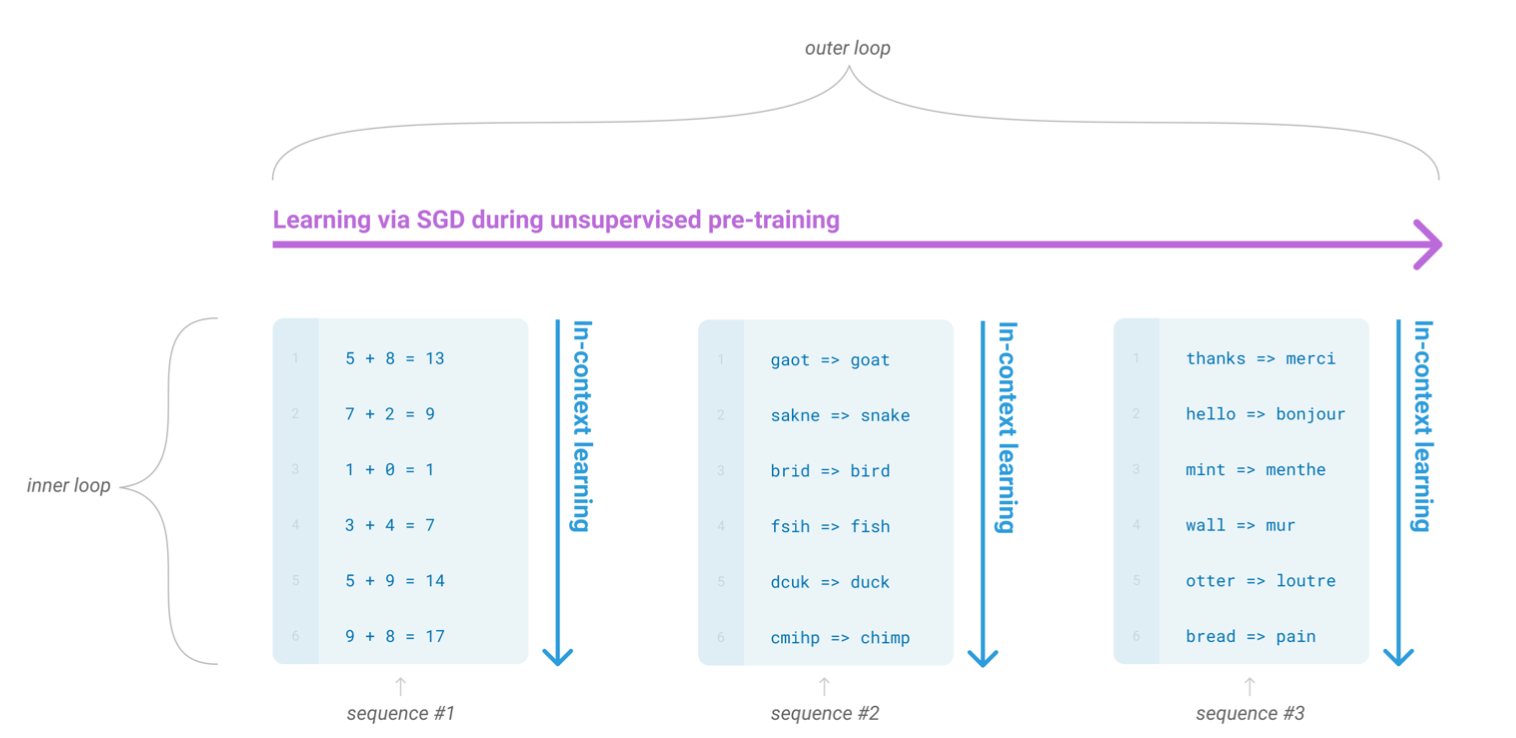
이런 문제를 해결하기 위한 잠재적인 루트는 바로 meta learning이다. 언어모델의 context딴에서 학습시간동안 패턴인지능력과 다양한 셋의 스킬을 개발하는 모델을 의미합니다. 그리고 그러고난 후에 inference 할때 이 능력을 원하는 작업에 빠르게 적응하거나 인식합니다 (위 이미지 참고). 최근연구를 통해 이걸 in-context learning이라고 부르기로 했고 task 특성의 특징에 맞게 사전학습된 언어모델의 텍스트 입력값으로 사용하는 것을 일컫습니다. 이 모델은 자연어 지시와 적은 demonstration에 영향을 받습니다. 그리고 다음에 올 단어를 간단하게 예측함으로써 추가적인 예시를 완벽하게 기대하게 만듭니다.
또한 in-context learning은 많은 기술과 task를 모델의 파라미터안에서 흡수하는것을 포함하기 때문에 in-context learning 능력은 규모에 따라 비슷하게 강력한 강점을 보일 수 있습니다.
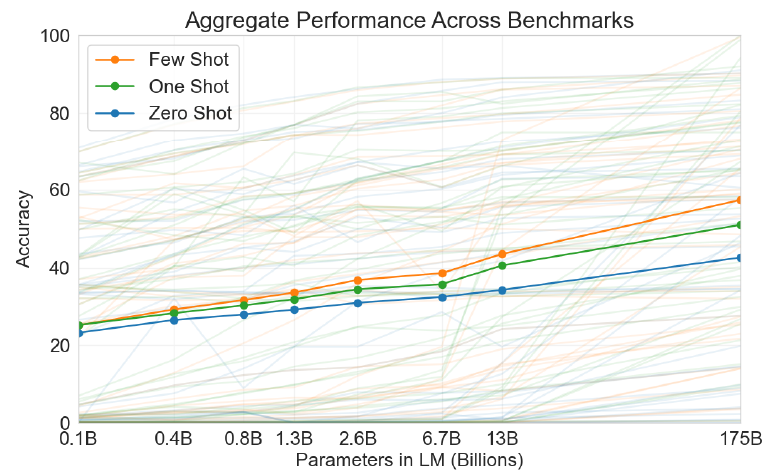
총 3가지 조건에서 평가하였다.
few-shot learning: 소수의 예시들어 in-context learningone-shot learning: 단 1개의 예시zero-shot learning: 특정 instruction에 대해 어떠한 예시도 없이 진행
실험 결과, FSL은 모델의 사이즈에 따라 성능이 급겨하게 향상되었다. 이 사례의 결과는 특히 놀랍지만, 모델 크기와 컨텍스트 예제 수에 대한 일반적인 추세는 우리가 연구하는 대부분의 작업에 적용되었다.
##