Training for DeepSpeed and FairScale
DeepSpeed & FairScale
DeepSpeed
DeepSpeed는 세계에서 가장 크고 강력한 언어 모델인 MT-530B, BLOOM과 같은 것들을 활용 가능하다. 이건 쉽게 사용할 수 있는 딥러닝 최적화 소프트웨어고 이 능력은 전례없는 스케일과 속도를 구가해내고 있다. DeepSpeed를 통해 할 수 있는 사항들은 다음과 같음.
- 수백만개 또는 수천억개의 파라미터를 가진 dense모델이나 sparse모델을 학습하거나 추론할 수 있음
- 뛰어난 시스템 처리량을 달성하고 수천 개의 GPU로 효율적으로 확장
- 리소스 제약이 있는 GPU 시스템에서 훈련/추론
- 추론을 위한 전례 없는 짧은 지연 시간과 높은 처리량 달성
- 극한의 압축을 통해 낮은 비용으로 탁월한 추론 지연 시간 및 모델 크기 감소 달성
설치
pip install deepspeed
pip install transformers[deepspeed]
TORCH_CUDA_ARCH_LIST: 현재 사용 중인 GPU에 따라 달라져야함.
# input
CUDA_VISIBLE_DEVICE=0 python -c 'import torch; print(torch.cuda.get_device_capaability())'
# OUTPUT
_CudaDeviceProperties(name={자신의 그래픽 카드}, major={major}, minor={minor}, total_memory={그래픽카드 메모리}, multi_processor_count={mp_cnt})
torch.distributed.launch:DeepSpeedEngine 초기화 과정으로 기존 Distributed Data Parallel을 사용할 때 초기화 하는 과정인torch.distributed.init_process_group()과 같은 역할
deepspeed --num_gpus=2 your_program.py <normal cl args> --deepspeed ds_config.json
- example :
Hugginface의examples/pytorch/translation/run_translation.py를DeepSpeed로 사용.
deepspeed examples/pytorch/translation/run_translation.py \
--deepspeed tests/deepspeed/ds_config_zero3.json \
--model_name_or_path t5-small --per_device_train_batch_size 1 \
--output_dir output_dir --overwrite_output_dir --fp16 \
--do_train --max_train_samples 500 --num_train_epochs 1 \
--dataset_name wmt16 --dataset_config "ro-en" \
--source_lang en --target_lang ro
단일 GPU 사용
- ZeRO Offload를 사용하기 위한 경우
DeepSpeed(ZeRO)의 메모리 관리로 보다 큰batch_size사용 가능- 간단한
ds_config.json파일을 아래와 같이 만들어 쓰기만 해도 성능이 좋음
ds_config.json
{
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true,
"cpu_offload": true
}
}
Jupyter Notebook에서 사용하기
# DeepSpeed requires a distributed environment even when only one process is used.
# This emulates a launcher in the notebook
import os
os.environ['MASTER_ADDR'] = 'localhost'
os.environ['MASTER_PORT'] = '9994' # modify if RuntimeError: Address already in use
os.environ['RANK'] = "0"
os.environ['LOCAL_RANK'] = "0"
os.environ['WORLD_SIZE'] = "1"
# Now proceed as normal, plus pass the deepspeed config file
training_args = TrainingArguments(..., deepspeed="ds_config_zero3.json")
trainer = Trainer(...)
trainer.train()
- Jupyter Notebook 환경에선 Multi-GPU 사용 불가능
ZeRO-2에서 많은 기능을 활성화한 ds_config.json 파일
{
"fp16": {
"enabled": "auto",
"loss_scale": 0,
"loss_scale_window": 1000,
"initial_scale_power": 16,
"hysteresis": 2,
"min_loss_scale": 1
},
"optimizer": {
"type": "AdamW",
"params": {
"lr": "auto",
"betas": "auto",
"eps": "auto",
"weight_decay": "auto"
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": "auto",
"warmup_max_lr": "auto",
"warmup_num_steps": "auto"
}
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"overlap_comm": true,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"contiguous_gradients": true,
"cpu_offload": true
},
"gradient_accumulation_steps": "auto",
"gradient_clipping": "auto",
"train_batch_size": "auto",
"train_micro_batch_size_per_gpu": "auto",
}
FairScale

FairScale의 장점
Usability: 최소 머신에서도 작동 가능Modularity: 트레이닝 loop를 균일하게 작동Performance: 최고의 성능을 뽑아낼 수 있음
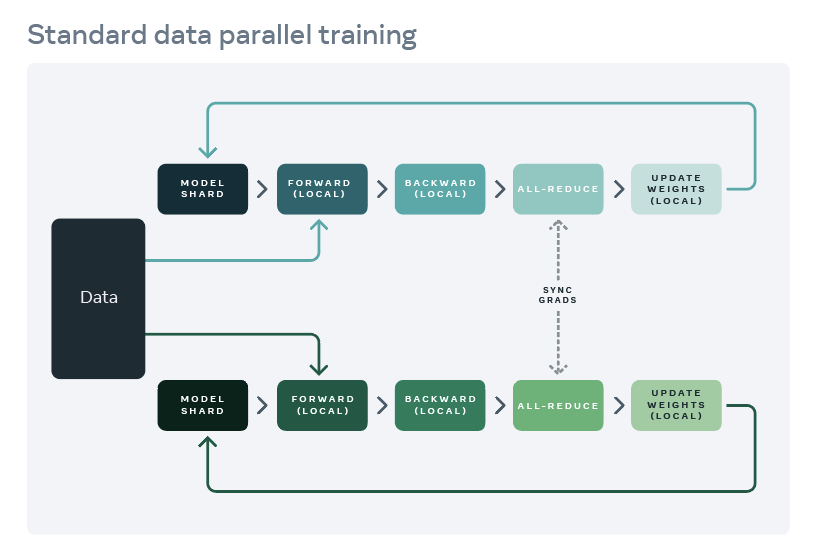
기존 머신러닝 학습은 Data Parallelism을 통해 작동되어왔으나 최근 연구를 통해 모든 “scaling”
목적에 부합하지 않음을 밝혀냈음.
설치
- torch >= 1.8.1
pip install fairscale -
GPU-support 활성화 하기위해선,
BUILD_CUDA_EXTENSIONS=1뿐만 아니라 적절한TORCH_CUDA_ARCH_LIST를 설정해줘야함. - 만약
conda,pip두 가지 방법 모두 실패시,pip install에--no-build-isolation을 추가해주자.
최적화, gradient와 model sharding
기존 torch.nn.parallel.DistributedDataParallel(DDP)은 OSS에서 사용하면 cost가 낭비될 수 있음. 그런 다음 optimizer 상태를 sharding하는 것은 optimizer를 fairscale.optim.OSS로 감싸는 문제일 뿐입니다. DDP는 SharededDDP를 대신해서 사용되어질 수 있음. 근데 메모리 절약은 잘 안 될 수 있음. 예시 코드는 다음과 같음.
import torch
from fairscale.optim.oss import OSS
from fairscale.nn.data_parallel import SharededDataParallel as ShardedDDP
def train(rank, world_size, epochs):
# initializing 과정
dist_init(rank, world_size)
# 문제 정의
model = MyModel().to(rank)
dataloader = MyDataLoader()
loss_ln = MyLossFunction()
# optimizer 정의
base_optimizer_arguments = {
'lr' : 1e-4
}
# OSS로 base_optimizer를 감싸주자(Wrap)
base_optimizer = torch.optim.SGD
optimizer = OSS(
params = model.parameters(),
optim = base_optimizer,
**base_optimizer_arguments
)
# ShardedDDP로 모델을 Wrap (적절한 rank로 gradients 줄여줄수 있음)
model = SharededDDP(model, optimizer)
# train
model.train()
for e in range(epochs):
for (data, target) in dataloader:
data, target = data.to(rank), target.to(rank)
model.zero_grad()
outputs = model(data)
loss = loss_fn(outputs, target)
loss.backward()
optimizer.step()
파라미터들은 FullySharededDataParallel(FSDP) API를 사용하여 sharde 되어질 수 있음. 이는 모델을 감싸는 형태이며 위의 SDP API와 비슷함.
import torch
from fairscale.nn.data_parallel import FullyShardedDataParallel as FSDP
def train(
rank: int,
world_size: int,
epochs: int):
# process group init
dist_init(rank, world_size)
# Problem statement
model = myAwesomeModel().to(rank)
dataloader = mySuperFastDataloader()
loss_ln = myVeryRelevantLoss()
# optimizer specific arguments e.g. LR, momentum, etc...
base_optimizer_arguments = { "lr": 1e-4}
# Wrap a base optimizer into OSS
base_optimizer = torch.optim.SGD # any pytorch compliant optimizer
# Wrap the model into FSDP, which will reduce parameters to the proper ranks
model = FSDP(model)
# Any relevant training loop. For example:
model.train()
for e in range(epochs):
for (data, target) in dataloader:
data, target = data.to(rank), target.to(rank)
# Train
model.zero_grad()
outputs = model(data)
loss = loss_fn(outputs, target)
loss.backward()
optimizer.step()
Single GPU 환경에서 offloadmodel 사용
fairscale.experimental.nn.offload.OffloadModel API는 사용자들이 제한된 GPU resource로 큰 모델을 학습하는것을 가능케함으로써 엄청난 양의 분산 학습을 가능케합니다. OffloadModel API는 주어진 모델을 wrap하고 거의 동등하게 shard 합니다. 각각 분산된 모델은 CPU에서 GPU로 forward pass를 통해 복사되어집니다. 그러고나서 다시 역으로 복사되어집니다. 이와 같은 과정은 backward pass동안 반복되어집니다. 또한 OffloadModel은 mixed 정확도 학습과 메모리를 줄이기 위한 활성화함수 checkpointing, 처리량을 줄이기 위한 초정밀 batches들을 지원합니다.
torch.nn.Sequential 모델에서 작동 가능합니다.
from torch.utils.data.dataloader import DataLoader
from torchvision.datasets import FakeData
from torchvision.transforms import ToTensor
from fairscale.experimental.nn.offload import OffloadModel
um_inputs = 8
num_outputs = 8
num_hidden = 4
num_layers = 2
batch_size = 8
transform = ToTensor()
dataloader = DataLoader(
FakeData(
image_size=(1, num_inputs, num_inputs),
num_classes=num_outputs,
transform=transform,
),
batch_size=batch_size,
)
model = torch.nn.Sequential(
torch.nn.Linear(num_inputs * num_inputs, num_hidden),
*([torch.nn.Linear(num_hidden, num_hidden) for _ in range(num_layers)]),
torch.nn.Linear(num_hidden, num_outputs),
)
OffloadModel API를 사용하기위해 model을 감싸줘야함. forward / backward pass 연산을 위해 원하는 device를 명시해줘야함. OffloadModel에 sharding할 숫자를 설정해줄 수 있음. 여기선 3으로 설정. 활성화함수 체크포인팅의 디폴트 값은 off고 microbatches 값은 1임.
offload_model = OffloadModel(
model=model,
device=torch.device("cuda"),
offload_device=torch.device("cpu"),
num_slices=3,
checkpoint_activation=True,
num_microbatches=1,
)
torch.cuda.set_device(0)
device = torch.device("cuda")
criterion = torch.nn.CrossEntropyLoss()
optimizer = torch.optim.SGD(offload_model.parameters(), lr=0.001)
# To train 1 epoch.
offload_model.train()
for batch_inputs, batch_outputs in dataloader:
batch_inputs, batch_outputs = batch_inputs.to("cuda"), batch_outputs.to("cuda")
start = time.time_ns()
optimizer.zero_grad()
inputs = batch_inputs.reshape(-1, num_inputs * num_inputs)
with torch.cuda.amp.autocast():
output = offload_model(inputs)
loss = criterion(output, target=batch_outputs)
loss.backward()
optimizer.step()
이 외에도 메모리 cost effencienty를 위해 fairscale.nn.checkpoint_activations.checkpoint_wrapper, fairscale.optim.adascale.AdaScale, fairscale.nn.Pipe 등과 같은 방법이 있음.