Few shot learning in NLP from text classification task
Few-shot learning
문제 정의
우린 여러가지 데이터셋이나 task에서 몇가지 문제들을 마주하게된다. 실무에서나 프로젝트 진행시에 데이터셋에 대한 label이 없는 경우가 종종 있을 것이다. 또한 data science 부서에서 일하게 된다면 데이터셋의 rows가 중요하진지 덜중요한지에 대한 레이블링을 자동적으로 판별해주는 method를 원할때도 있을 것이다. 이건 단순한 이진 분류기로, 레이블링 데이터는 아마 극단적으로 길거나 매우 다루기 힘든 작업일 수도 있다.
이러한 종류의 problem들은 좀 다른 방식으로 정의될 필요가 있다. 다음은 우리가 난관에 봉착할 수 있는 scenario들을 정의한 것이다.
- Zero-shot learning : 각 class에 대해 레이블된 관측이가 있으나 몇몇 class는 관측치가 없는 경우. (이번 글에선 다루지 않음)
- One-shot learning : 각 class에 대한 관측치가 오직 1개인 경우
- Few-shot learning : 각 class에 대한 관측치가 2개 이상 있는 경우
One-shot과 Few-shot에 대해 더 쉽게 생각하기 위해 task를 email classification이라 생각해보자. 실제로, business user에게 10개의 메일 중, 중요한 메일과 중요하지 않은 메일을 각각 분류하길 요청하는건 매우 쉬운 일일 것이다.
아마 이 레이블링은 5분도 안되어서 끝날텐데.., 여기서 의문점 : 고작 10개의 데이터 가지고 뭘 할 수 있지??
Solution
Few-shot learning 대개 CV 분야에서 연구되어져왔다. 주로 Face Recognition 알고리즘과 같은 task 에서 전형적으로 사용되어져왔다. 각 사람마다 1개 또는 2개의 사진을 가지고 있고 누구인지 사진을 통해 추려내야만 할 것이다. 그런데 NLP 분야에선 좀 생소하게 느껴질 것으로 생각된다.
대부분의 few-shot learning task에선 어떠한 point에서 발생되는 거리의 개념이 존재한다. Siamese networks에선 anchor과 다른 positive 예시들 사이의 거리를 최소화하고 anchor와 negative 예시들의 사이를 최대화하는 것이 주요 문제일 것이다.
최근 논문에서의 few-shot learning에 대해 다룬것이 몇가지 존재한다.
- 샴 네트워크에서 CNN보단 LSTM base를 사용한다는 것과 이걸 위해 One-shot learning을 사용한다는 것
- word embedding을 one-shot 또는 few-shot 기반으로 학습하는 방법
- 또는 사전학습된 단어와 문서 embedding network를 사용하고 build a metric on top
우린 마지막 solution에 집중할것이고 이번 글은 Few-Shot Text Classification with Pre-Trained Word Embeddings and a Human in the Loop 논문을 다룰 예정임
Few-shot with Human in the Loop
Concept
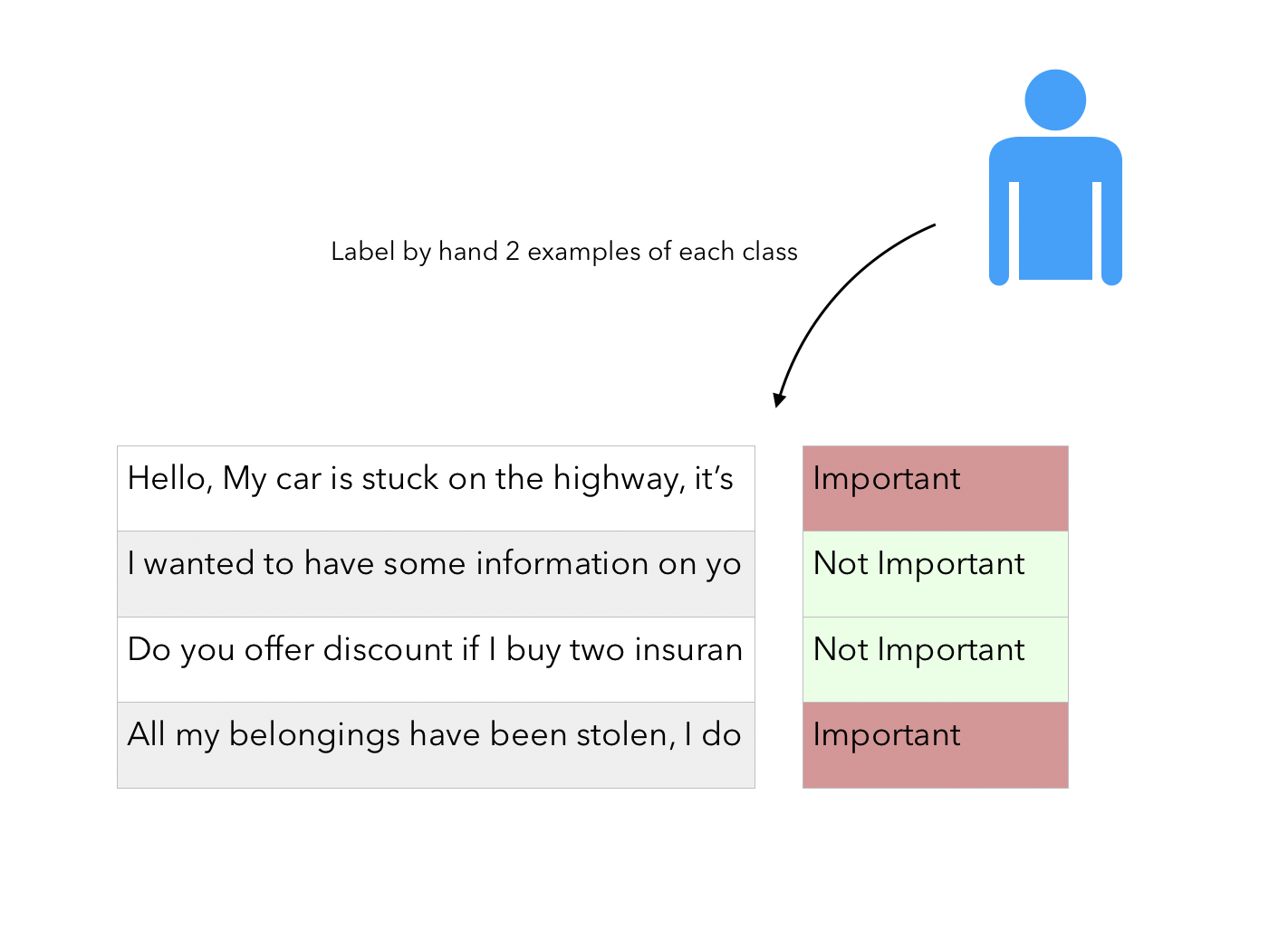
“Human in the loop”이 있다는 사실은 단순히 라벨이 지정되지 않은 데이터의 잠재적으로 큰 corpus가 있고 사용자가 각 class의 몇 가지 예에 label을 지정해야 한다는 사실을 의미한다.
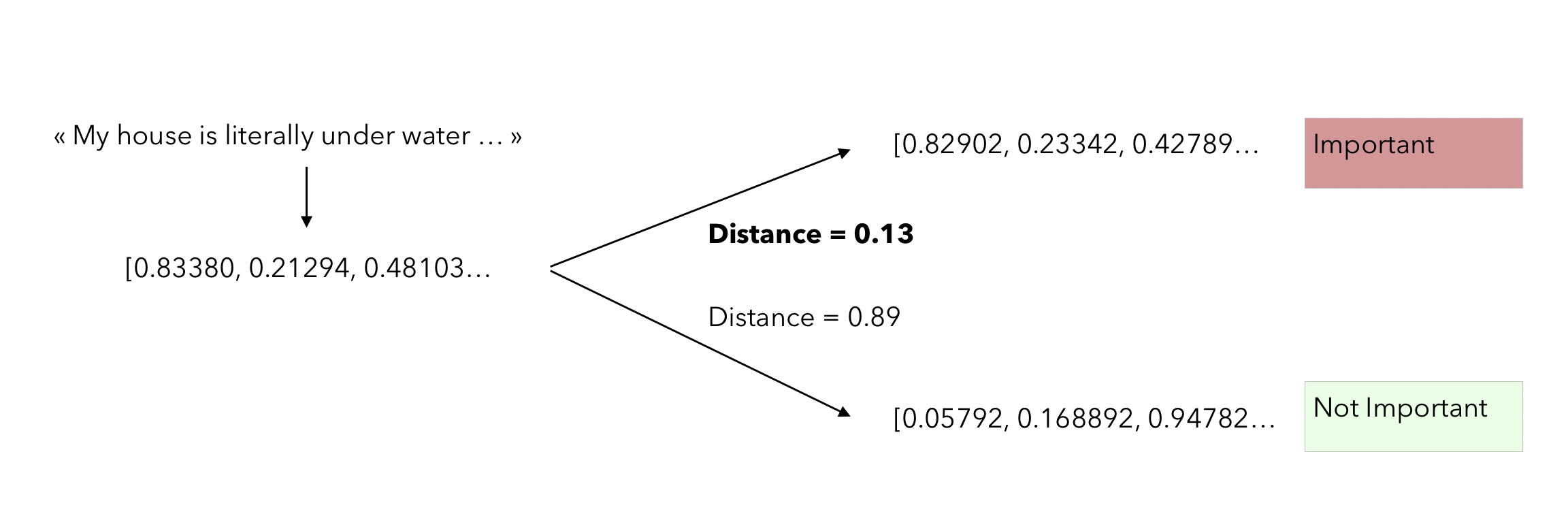
그 후에, 사전학습된 word embedding 모델을 사용하고, 각 email의 average embedding을 계산할 것이다.


이 각 class에 대한 average embedding은 고차원의 space에 대한 centroid로 보여집니다. 이로부터 새로운 관측치는 들어올 것이고, 단순하게도 두개의 centroid로부터 얼마나 멀어져 있는지 확인해볼 필요가 있습니다. 그리고 가장 가까운 점에 대해서도 말입니다. 이 distance metric은 해당 논문에서 cosine distance로 사용되었습니다.
다음은 새로운 문장이 들어왔을때 classification하는 프로세스입니다.