BERT - Pre-training of Deep Bidirectional Transformers for Language Understanding [2018]
요약
-
masked language model(MLM)을 사용하여 deep directional 구조를 가진다. BERT는 input token 전체와 masked token을 한번에 Transformer encoder에 넣고 원래 token을 예측하므로 deep directional함. 특정위치에 있는 단어들을 마스킹 후, 예측하도록 만듦 -
Pre-trained representation이 고도로 엔지니어링된 많은 작업별 아키텍쳐의 필요성을 감소시킨다는 것을 보여줌
BERT
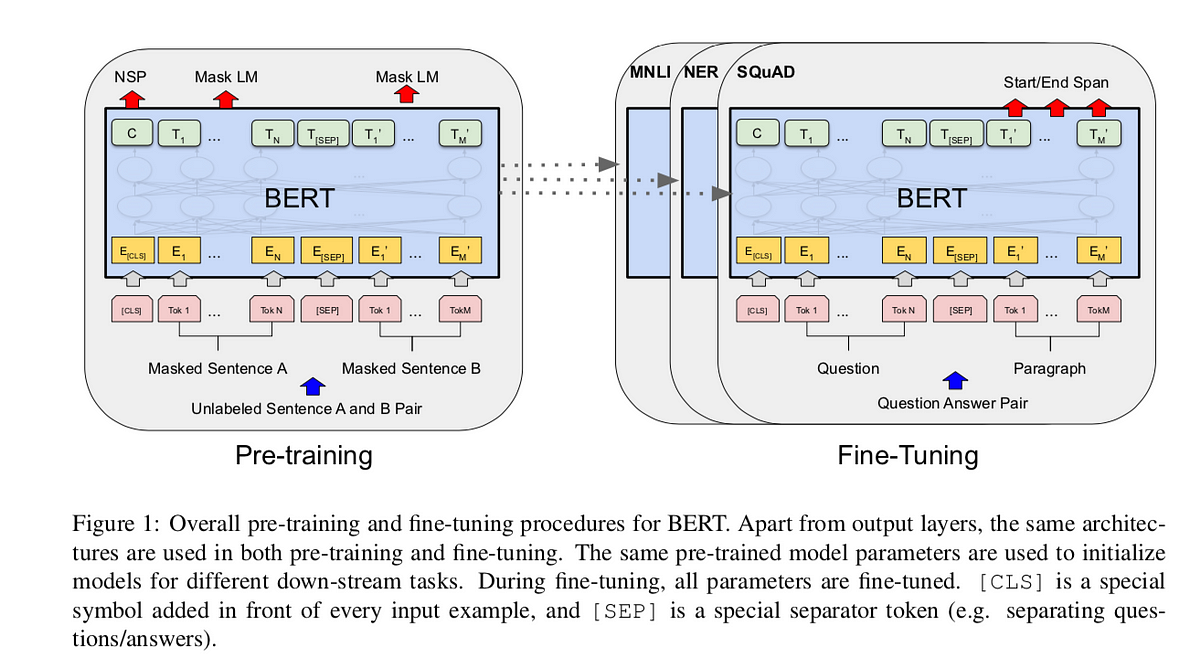
BERT의 구조는 Transformer와 유사하지만 Pre-training과 Fine-tunning 시의 구조를 조금 다르게하여 전이학습(Transfer Learning)을 용이하게 만드는 것이 핵심입니다.
Model Architecture
- multi-layer bidirectional Transformer encoder 구조
- BERT는 모델의 크기에 따라 base모델과 large모델로 구분
- base model : 110M of Parameteres
- large model : 340M of Parameters
- BERT base model은 OpenAI GPT 모델과 hyperparameter가 동일. OpenAI GPT 모델은 제한된 self-attention을 수행하는 transformer decoder 구조이지만, BERT는 MLM과 NSP를 위해 self-attention을 수행하는 transformer encoder 구조
- 2개의 문장이 Input으로 받게될시, 반드시
[CLS]토큰,[SEP]토큰모두 입력. - 이후 일련의 레이어를 거친후, 최종 special [CLS] 토큰의 hidden vector를 산출하게 되는데 이는 단순한 NSP와 같은 task에서 사용될 수 있을 것이다.
-
그 이후의 토큰들은 각 레이어를 거친후, 나타나는 $N^(th)$ 토큰의 최종 hidden vector들은 Mask LM task를 수행한다.
- 이 두가지의 task를 동시에 진행시키는것이 BERT
Input/Output Representation
 [Input Representation]
[Input Representation]
- BERT의 다양한 down-stream task를 다루기위해 Input은 ‘single sentence’, ‘pair of sentence(Question-Answer)’로 정의 될 필요가 있다.
- Sentence : 실제 언어학적인(완벽한) 문장이 아니여도되는 연속적인 text의 나열
- Sequence : 실제 BERT에 입력될 Input값으로 이는 단순한
single sentence일수도있고 두개의 문장이 결합한two sentences packed together일수도 있겠다.
- BERT의 input은 3가지 embedding 합으로 이루어져있다.
- WordPiece embedding을 사용
- 모든 문장의 첫번째 토큰은
[CLS]이다. - 전체의 Transformer 층을 다 거치고 난 뒤의 이러한
[CLS] token은 총합한 token sequence라는 걸 의미한다. classification task의 경우, 단일 문장 또는 연속한 문장의 classification을 쉽게 할 수 있다. - sentence pair는 하나의 문장으로 묶어져 입력된다. 문장을 구분하기 위해 2가지 방식을 사용한다.
[SEP] token을 사용하거나segment embedding을 사용해 sentence A 또는 sentence B embedding을 더해준다. - 이후, Transformer에서 보았듯이 각각의 Position에 대한 Positional Embedding이 들어가게 될 것이다.
Token Embedding+Segment Embedding+Positional Embedding= Input Representation
Pre-training BERT
ELMo와 GPT는 left-to-right 또는 right-to-left 언어 모델을 사용해 pre-training을 수행한다. 하지만 BERT는 이와 다르게 2가지의 새로운 unsupervised task로 pre-training을 수행한다.
Task 1. Masked LM (MLM)
Input token 중 랜덤(15%)하게 mask하고 이를 학습해 주변 단어의 context만 보고 masked token을 예측한다.

Bi-directional한 Transformer Encoder를 쓰되, 실제 Input에 해당하는 단어들을 임의의 비율(15%)로 마스킹을 시키고 모델이 학습을 통해서 실제 가려진 값을 잘 예측하도록 학습시키는 것이 바로 BERT의 pre-training 첫번째 task인 MLM.
text를 tokenization 하는 방법은 WordPiece를 사용한다. 기존 언어모델에서 left-to-right를 통해 문장 전체를 예측하는 것과는 대조적으로 [MASK] token만을 예측하는 Pre-training task를 수행한다. 이 [MASK] token은 pre-training에만 사용되고 fine-tuning에는 사용되지 않는다. 이 miss-match를 해결하기위한 방법으로 논문에선 다음을 제시하고있다.
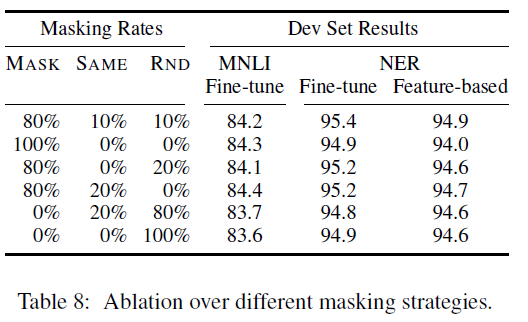
- 80% : token을 [MASK]로 바꾼다.
- 10% : token을 random word로 바꾼다.
- 10% : token을 원래 단어로 놔둔다.
80-10-10의 비율로 지정했을때, 가장 준수한 성능을 낸다는 것이 논문저자들의 주장이며, 논문에선 다음과 같은 결과를 도출해내었다. 이는 다소 heuristic 측면이 나타나고 있다.
Task 2. Next Sentence Prediction (NSP)

QA(Question-Answer)나 NLI(Natural Language Inference)와 같은 경우는 기본적으로 2개 이상의 문장들에 대한 관계를 이해해야 풀어낼 수 있는 것인데 문장단위의 LM의 경우는 이 관계를 잘 이해할 수 없다는 것이 논문저자들의 지적이다. 이를 위해 BERT에서는 binarized NSP task를 수행한다.
두 문장을 pre-training시에 같이 넣어줘서 두 문장이 이어지는 문장인지 아닌지를 맞춘다. 50%는 실제로 이어지는 문장(IsNext), 50%는 랜덤하게 추출된 문장(NotNext)를 넣어줘 BERT가 예측하도록 한다.
pre-training후, task는 97% ~ 98% 정확도를 달성함.
Hyper-parameter
- Maximum token length : 512
- Batch size : 256
- Adam with learning rate of 1e-4, beta1 = 0.9, beta2 = 0.999
- L2 weight decay of 0.01
- Learning rate warmup over the first 10,000 steps, linear decay of the learning rate
- Dropout Probability of 0.1
- GeLU activation function
- $BERT_{BASE}$ took 4 days with 16TPU / $BERT_{LARGE}$ took 4 days with 64TPU
- Pretrain the model with sequence length of 128 for 90% of the steps
- The rest 10% of the steps are trained with sequence legnth of 512
Fine-tuning BERT
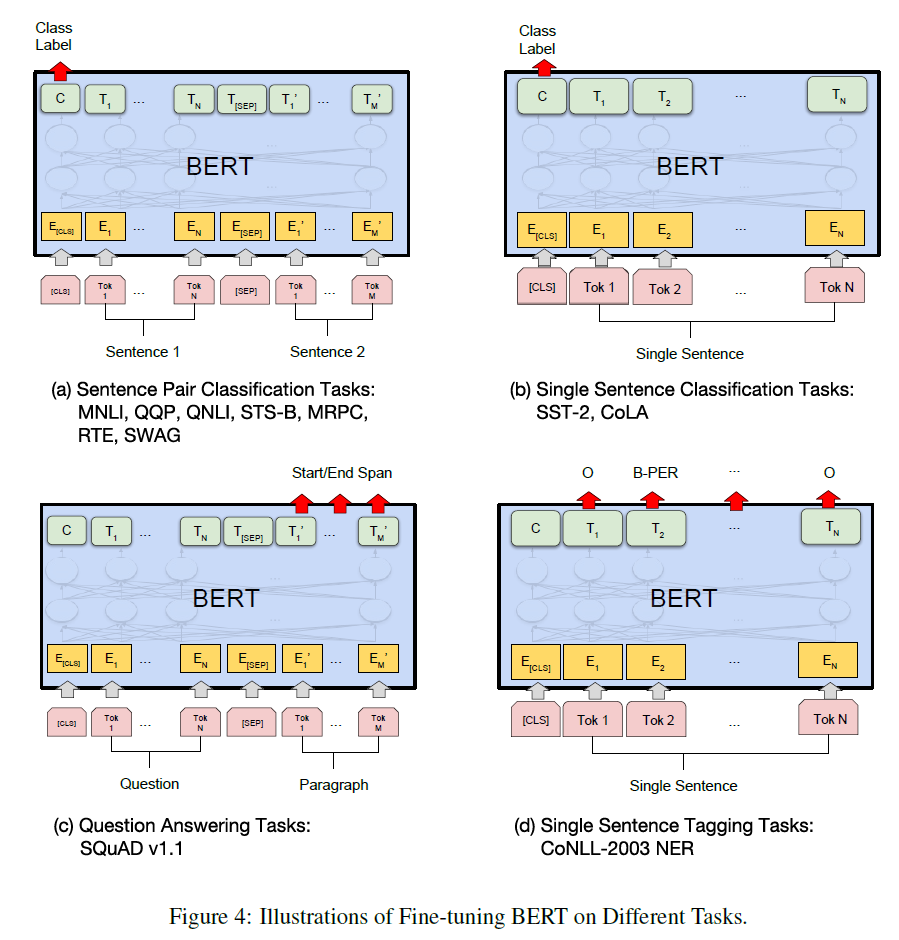
-
트랜스포머의 Self-attention 메커니즘이 BERT가 단일 텍스트 또는 텍스트 pair를 포함하는지 여부와 적절한 Input과 Output을 교환하여 많은 다운스트림 작업을 모델링 할 수 있도록 해주기 때문에 Find-tuning은 간단하다.
-
텍스트 pair와 관련있는 어플리케이션의 경우, 일반적인 패턴은 양방향 교차 Attention을 적용하기 전에 텍스트 pair를 독립적으로 Encode하는 것이다.
-
대신, BERT는 Self-attention을 이용하여 연결된 텍스트 pair를 Encoding하는 것은 두 문장 사이의 양방향 교차 Attention을 효과적으로 포함하기 때문에, 이러한 두 가지 단계를 통합하기 위해 Self-attention 메커니즘을 사용한다.
-
각 작업마다 간단히 Task-specific한 Input과 Output을 BERT와 연결하고, 모든 파라미터들을 End-to-End로 Fine-tuning 한다.
Input
- Pre-training한 문장 A와 B는 아래 것들과 유사
- Paraphrasing의 문장 pair
- Entailment의 Hypothesis-Premise pair
- QA의 Question-Passage pair
- 텍스트 분류 또는 시퀀스 태깅의 축약된 테스트
Ouput
토큰표현은 QA 또는 시퀀스 태깅 같은 토큰-수준 작업데 대한 Output 계층에 공급[CLS]표현은 감성 분석, Entailment 같은 분류에 대한 Output 계층에 공급
Ablation Study
- 기존 NSP task를 차용하지 않은 모델과 BERT의 pre-training task(QA + NSP) 적용했을때의 성능 차이를 보여주는 파트
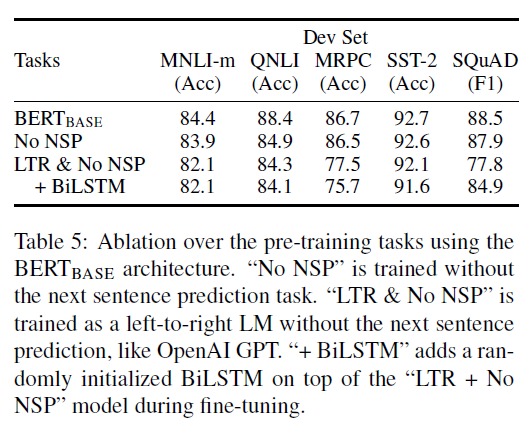
- 모델 사이즈
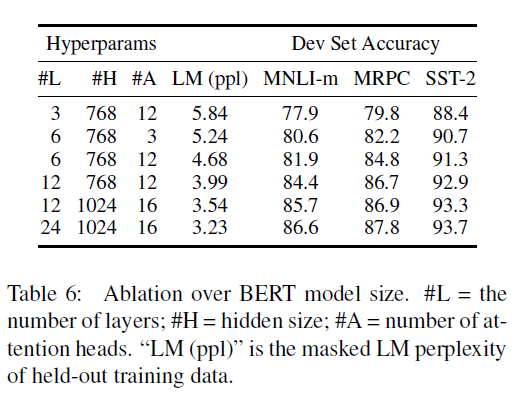
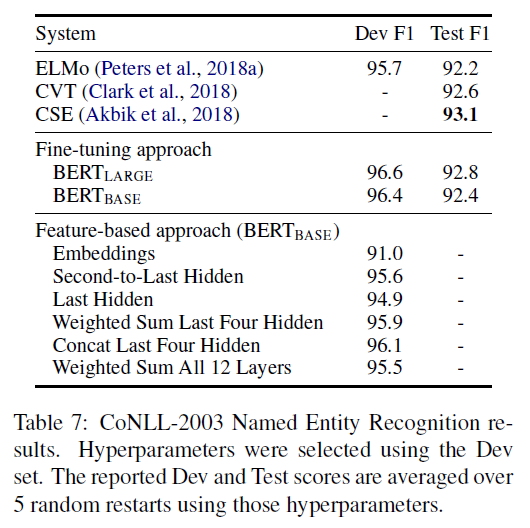
- Fine-tuning을 거치지않고 pre-training된 모델만 가지고 downstream-task를 수행했을때의 성능
BERT의 한계점
BERT는 일반 NLP모델에서 잘 작동하지만 Bio, Science, Finance 등 특정 분야의 언어모델에 사용하려면 잘 적용되지않는다. 사용 단어들이 다르고 언어의 특성이 다르기 때문이다. 따라서 특정 분야에 BERT를 적용하려면 특정분야의 특성을 수집할 수 있는 언어데이터들을 수집하고 언어모델 학습을 추가적으로 진행해주어야 한다.