R-CNN - Rich feature hierarchies for accurate object detection and semantic segmentation [2013]
Abstract
Object Detector는 Object의 coordinate를 찾고(Localization), class를 분류(Classification)하는 작업을 진행한다. R-CNN은 이를 순차적으로 진행하는 2 Stage Detector 로, 딥러닝을 적용한 최초의 Object Detector다. R-CNN모델은 Object Detection 혹은 Inference(추론)시, 아래와 같은 순서에 의해 동작한다.

-
Selective Search 알고리즘을 통해 Object가 있을 법한 위치인 Region Proposal을 2000개 추출하여, 각각을 227x227 크기로 Warp 시켜준다.
-
Warp된 모든 Region Proposal을 Fine Tune된 AlexNet에 입력해 2000x4096 크기의 Feature Vector를 Extraction 한다.
-
추출된 Feature vector를 linear SVM 모델과 Bounding Box Regressor 모델에 입력해 각각 Confidence-score와 조정된 Bounding box coordinate값을 얻는다.
-
NMS(Non-Maximum Suppression)
알고리즘을 적용해 최소한의, 최적의 bounding box를 출력한다.
Region Proposal, Selective Search

R-CNN 모델은 구체적인 Object의 위치를 추정하기 앞서 Selective Search 알고리즘을 통해 Object가 있을법한 위치인 Region Proposal(후보 영역)을 추출한다. Selective Search 알고리즘은 색상, 무늬, 명암 등의 다양한 기준으로 픽셀을 그룹화하고, 점차 통합시켜 Object가 있을법한 위치를 Bounding Box 형태로 추천 한다. 단일 이미지에서 2000개의 Region Proposal을 extraction한 뒤, CNN 모델에 입력하기 위해 227x227 크기로 Warp(=resize)시켜준다.
- Input : Single Image
- Process : Region Proposal by Selective Search & Warp
- Output : 227 x 227 sized 2000 Region Proposal
Feature Extraction by Fine tuned AlexNet
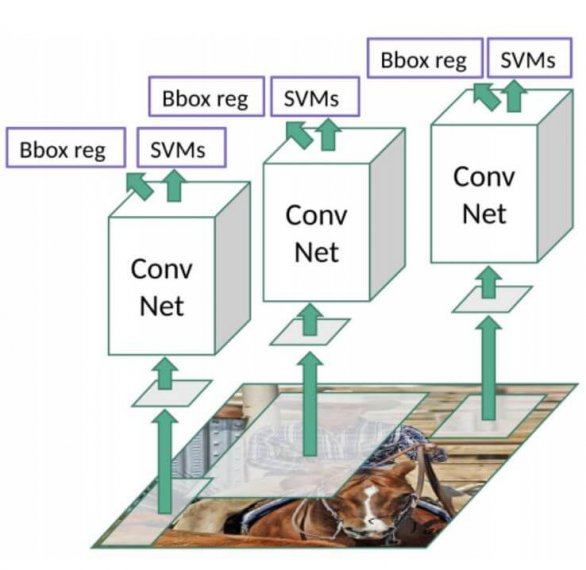
다음으로 2000개의 Region Proposal을 Fine Tune된 AlexNet에 입력해 2000(=Number of Region Proposal) x 4096(=Number of Feature Vector) 크기의 Feature vector를 추출한다. 논문의 저자는 Object Detection시, 특정 도메인에 맞는 class를 예측하기 위해서 기존의 ImageNet 데이터셋을 통해, 사전학습된 CNN모델을 도메인에 맞게 fine tune하는 방식을 제안한다. Fine tune된 모델을 사용하면 도메인에 맞게 보다 적합한 feature vector를 추출하는 것이 가능해진다.
사전학습된 AlexNet을 Fine-Tune

R-CNN 모델이 Inference(추론)시 입력으로 들어온 후보영역은 Object를 포함할 수도 있으며, Background을 포함할 수도 있다. 따라서 Fine-tune시 예측하려는 Object의 수가 N개라고 할 때 배경을 포함하여 (N+1)개의 class를 예측하도록 모델을 설계해야하며, Object와 Background를 모두 포함한 학습 데이터를 구성해야한다. 이를 위해 PASCAL VOC 데이터셋에 Selective Search 알고리즘을 적용해 Object와 Backgroun가 모두 포함된 후보영역을 추출하여 학습데이터로 사용한다.
Selective Search 알고리즘은 R-CNN 모델의 Inference할 때에도, AlexNet을 Fine-tune할 때도 사용
먼저 PASCAL VOC 데이터셋에 Selective Search 알고리즘을 적용한 후 후보영역을 추출하고, 후보영역과 Ground Truth Box 와의 IoU값을 구한다. IoU값이 0.5이상인 경우, Positive sample=Object로, 0.5 미만인 경우에는 Negative Sample=Background로 저장한다. 그리고 Positive sample = 32, Negative sample = 96, Mini batch = 128을 구성하여 사전학습된 AlexNet에 입력해 학습을 진행한다. 위 과정을 통해 fine-tune된 AlexNet을 사용해 R-CNN 모델은 추론시, Feature Vector를 추출한다.
미리 ImageNet으로 학습된 CNN을 가져와, Object Detection용 데이터셋으로 fine-tune 한 뒤, Selective Search 결과로 뽑힌 이미지들로부터 Feature Vector를 추출한다
- Input : 227 x 227 sized 2000 Region Proposal
- Process : Feature Extraction by fine tuned AlexNet
- Output : 2000x4096 sized Feature Vector
Linear SVM을 통한 분류
Linear SVM모델은 2000x4096 Feature Vector를 입력으로 받아 class를 예측하고 Confidence-score를 반환한다. 이 때 linear SVM 모델은 특정 class에 해당하는지 여부만을 판단하는 이진분류기이다. 따라서 N개의 class를 예측한다고 할 때, Background를 포함한 (N+1)개의 독립적인 linear SVM 모델을 학습시켜야한다. 다음은 단일 linear SVM 모델을 학습시키는 과정이다.
Fine-tune된 AlexNet을 사용해 Linear SVM 학습

먼저 Object와 Background를 모두 학습하기 위해 PASCAL VOC 데이터셋에 Selective Search 알고리즘을 적용해 Region Proposal을 추출한다.
AlexNet모델을 Fine-tune 할 때와는 다르게 오직 Ground Truth Box만을 Positive Sample로, IoU 값이 0.3 미만인 예측 Bounding box를 Negative Sample로 저장한다. IoU값이 0.3 이상인 bounding box는 무시한다.
positive sample = 32, negative sample = 96이 되도록 mini-batch = 128을 구성한 뒤, fine-tune된 AlexNet에 입력해 Feature Vector를 추출하고, 이를 Linear SVM에 입력하여 학습시킨다. 이때 하나의 Linear SVM 모델은 특정 class에 해당하는지 여부를 학습하기 때문에 output unit = 2이다. 학습이 한 차례 끝난 후, hard negative mining 기법을 적용해 재학습시킨다.
Hard Negative Mining

Hard Negative Mining은 모델이 예측에 실패하는 어려운 sample들을 모으는 기법으로, hard negative mining을 통해 수집된 데이터를 활용하여 모델을 보다 강건하게 학습시키는 것이 가능해진다.
예를들어, 이미지에서 사람의 안면의 위치를 탐지하는 모델을 학습시킨다고 할 때, 사람의 안면은 positive sample이며, 그 외의 Background는 Negative Sample이다. 이 때 모델이 Background라고 예측했으면 실제로 Background인 bounding box는 True Negative에 해당하는 sample이다. 반면에 모델이 안면이라고 예측했지만, 실제로 배경인 경우는 False Positive Sample에 해당한다.
모델은 주로 False Positive라고 예측하는 오류를 주로 범한다. 이는 객체 탐지 시, 객체의 위치에 해당하는 positive sample보다 배경에 해당하는 negative sample이 훨씬 많은 클래스 불균형으로 인해 발생한다. 이러한 문제를 해결하기 위해 모델이 잘못 판단한 False Positive Sample을 학습 과정에서 추가하여 재학습하면 모델은 보다 강건해지며, False Positive 라고 판단하는 오류가 줄어든다.
AlexNet에 softmax대신, 별도의 Linear SVM을 쓴 이유
Softmax함수를 사용해 class를 분류할 경우, mAP 수치가 약 2% 정도 떨어진다고 한다. AlexNet을 fine-tune할 때, 많은 데이터를 포함하는 과정에서 상대적으로 정확하지 않은 예측 bounding box를 positive sample에 포함시키게 된다. 이로 인해, 상대적으로 엄밀한 학습데이터를 사용하는 linear SVM 모델에 비해 성능이 하락하게 된다.
학습된 Linear SVM에 2000x4096 크기의 Feature Vector를 입력하면 class와 confidence-score를 반환한다.
- Input : 2000x4096의 크기를 가지는 Feature Vector
- Process : linear SVM을 통한 class 예측
- Output : 2000개의 class와 confidence-score
Detailed localization by bounding box regressor
Selective Search 알고리즘을 통해 얻은 객체의 위치는 부정확할 수 있다. 이러한 문제를 해결하기 위해 bounding box의 coordinate를 변환하여 객체의 위치를 세밀하게 조정해주는 Bouding Box Regressor 모델이 있다.
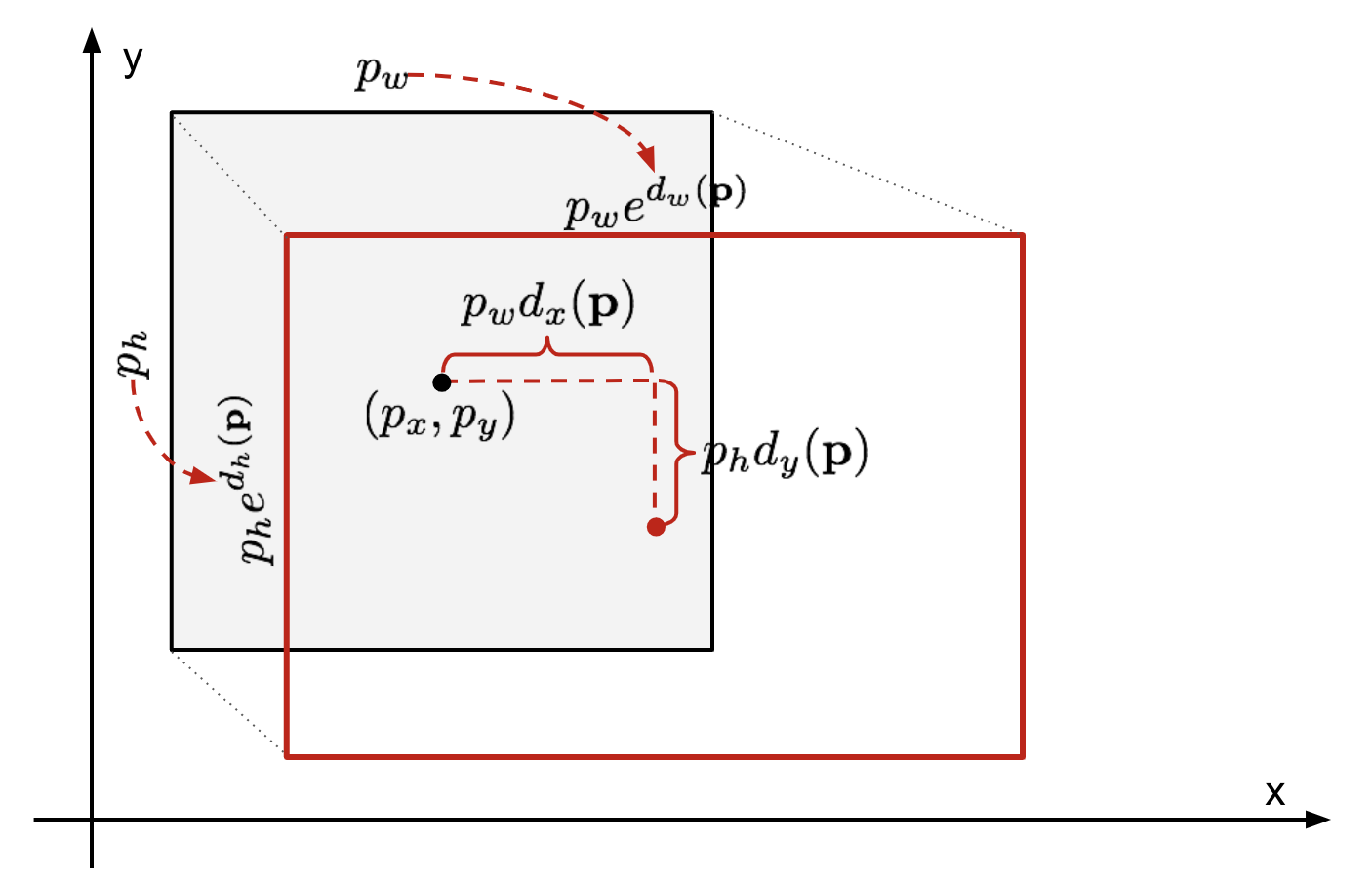
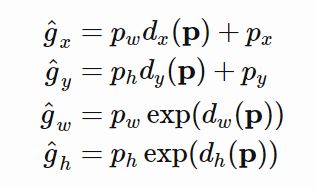
위 그림에서 회색 box는 Selective Search 알고리즘에 의해 예측된 bounding box이며, 빨간 테두리 box는 Ground Truth Box이다. Bounding Box Regressor는 예측한 Bounding Box의 coordinate $p = (p_x, p_y, p_w, p_h)$(center X, center Y, width, height)가 주어졌을 때, Ground Truth Box의 좌표 $g = (g_x, g_y, g_w, g_h)$로 변환되도록 하는 Scale Invariant Transformation을 학습한다.
Fine-tune된 AlexNet을 사용해 Bounding Box Regressor 학습

PASCAL 데이터셋에 Selective Search 알고리즘을 적용하여 얻은 추론영역을 학습데이터로 사용한다. 이 때 별도의 Negative Sample은 정의하지 않고, IoU값이 0.6 이상인 sample을 Positive Sample로 정의한다.
IoU값이 지나치게 작거나 겹쳐진 영역이 없는 경우, 모델을 통해 학습시키기 어렵기 때문이다.
Positive Sample을 Fine-tune된 AlexNet에 입력해 얻은 Feature Vector를 Bounding Box Regressor에 입력해 학습시킨다. 추론시 Bounding box regressor를 입력받아 조정된 BB coordinate값(output_unit = 4)를 반환한다.
- Input : 2000x4096의 크기를 가지는 Feature Vector
- Process : BB Regressor를 통해 BB coordinate값 변형
- Output : 2000 개의 BB coordinate값들
NMS(Non-Maximum Suppression)
정의
- 제일 큰 것을 제외하고 나머지는 압축!
- 여러개의 BB가 같은 class로 분류되면서 겹쳐있다면 자잘한 BB를 제거하는 방식
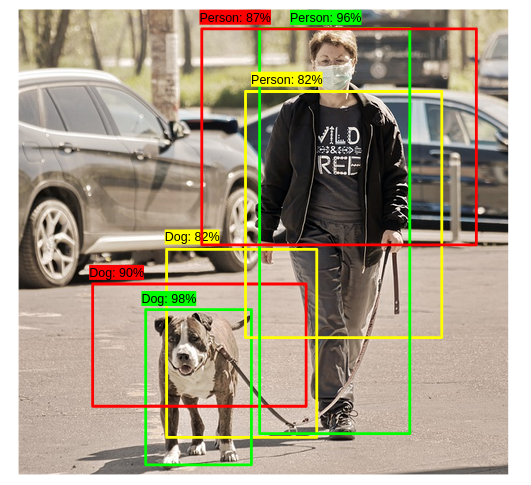
위 SVM을 통과한 Output값인 2000개의 B.B값을 전부 표시할 경우 하나의 객체에 지나치게 많은 BB가 겹칠 수 있다. 이로 인해 당연하게 객체탐지의 정확도가 떨어질 수 있을것이다. 이러한 문제를 해결하기 위해 감지된 BB중에서 비슷한 위치에 있는 box를 제거하고 가장 적합한 box를 선택하는 **NMS**알고리즘을 적용한다. NMS는 다음과 같은 순서에 따라 진행된다.
 [그림1]
[그림1]
 [그림2]
[그림2]
 [그림3]
[그림3]
 [그림4]
[그림4]
- BB별로 지정한 Confidence-score 임계값(threshold) 이하의 box를 제거한다.
- Confidence-score threshold를 0.4로 지정
- [그림4] 왼쪽 사진에서 Confidence-score가 0.3인 box를 제거
- 남은 BB를 Confidence-score에 따라 내림차순으로 정렬 > Confidence-score가 높은 순의 B.B부터 다른 box와의 IoU값을 조사 > IoU threshold 이상인 box를 모두 제거
- IoU threshold를 0.5로 지정
- Confidence-score에 따라 내림차순으로 box를 정렬 [0.9, 0.85, 0.81, 0.73, 0.7]
- Confidence-score가 0.9인 box와 나머지 box와의 IoU 값을 조사 [0.85 : 0, 0.81 : 0.44, 0.73 : 0, 0.7 : 0.67]
- IoU threshold 이상인 Confidence-score가 0.81, 0.7인 box는 제거 [0.9, 0.85, 0.73]
- 남은 box에 대해 위의 과정을 반복
- 남아있는 box만 선택
- 남은 box는 Confidence-score가 0.9, 0.85인 box

NMS 알고리즘은 Confidence-score 임계값이 높을수록, IoU 임계값이 낮을수록 많은 box가 제거된다. 위 과정을 통해 겹쳐진 box를 제거하고 최소한의 최적의 B.B를 반환한다. Frankly speaking, 두 박스의 교집합을 합집합으로 나눠준 값이 IoU. 논문에서는 IoU가 0.5보다 크면 동일한 물체를 대상으로 한 박스로 판단하고 NMS를 적용한다.
- Input : 2000개의 B.B
- Process : NMS 알고리즘을 통해 불필요한 box를 제거
- Output : 최적화된 B.B와 class값
R-CNN에서 학습이 나타나는 곳
-
ImageNet으로 Pre-trained 모델을 가져와 Fine-tunning 하는 부분
-
SVM Classifier를 학습시키는 부분
-
Bounding Box Regression 부분
단점
-
R-CNN은 비효율성을 지니고 있다.
-
하나의 이미지에 2000개의 Region이 존재할 때, 각각의 Region마다 이미지를 cropping한 후, CNN을 수행해 2000번의 연산을 진행한다. 따라서 연산량이 많아지고 Detection 속도가 느리다.
-
CPU 기반의 Selective Search를 진행하므로 연산이 많다
-
전체 아키텍처에서 SVM, Regressor 모듈이 CNN과 분리되어있다.
- CNN은 고정되므로 SVM과 BB Regression 결과로 CNN을 업데이트 할 수 없다
- 다시말해 end-to-end방식으로 학습할 수 없다
후에 위의 단점이 개선된 Fast R-CNN, Faster R-CNN이 발표된다.
요약
-
Bounding Box에 대한 proposal을 setting
-
사전학습된 AlexNet을 통해Bounding Box가 있는 이미지를 실행 + SVM을 통해 박스가 내포되어있는 이미지안에 무엇이 있는지 본다
-
객체를 분류한 후 상자에 대해 더 정확한 좌표를 출력하려면 선형 회귀 모델을 통해 상자를 실행한다
-
R-CNN은 2개의 insight를 통해 성능을 뽑아냈다.
-
첫째, 밑에서부터 올라오는 Region Proposal을 찾고 객체에 대해 segment하기 위해 높은 효용성을 지닌 CNN모델을 적용했다는 것이다.
-
둘째, 학습데이터의 label들이 부족할때, 볼륨이 큰 CNN을 학습시켰다는것이다.
-
-
VGG나 ResNet과 같이 ImageNet 데이터셋을 학습시킨 CNN network를 사전학습하였다.
-
Selective Search를 통해 독립적인 관심 Region을 제안한다. 이 Region들은 목표 객체를 포함할 것이고 이들은 모두 다른 사이즈를 가질것입니다.
-
영역 후보들은 CNN이 요구하는
input_shape에 맞게 크기를 고쳐서 Warp되어질 것이다. -
K+1개의 클래스를 위해 warp된 후보영역들에 한해서 CNN을 fine-tunning을 계속한다;추가적인 하나의 클래스는 Background(배경)로 적용할 것이다.(객체가 없다는 전제하에) fine-tunning할 때, 좀더 적은 Learning Rate를 사용할 것이며, 가장 높은 확률값을 지닌 제안된 Region들은 그저 배경에 불과하기 때문에, Mini-batch는 Positive Case(Object)를 Oversampling할 것이다.
-
모든 이미지의 영역을 고려해볼때, CNN을 통한 단방향 전파는 Feature Vector를 뽑아낼 것이다. Feature Vector는 그러고 나서 각각의 독립적인 class를 위해 학습된 binary SVM을 취할것이다. Positive Sample들은 IoU와 threshold >= 0.3과 함께 Region을 제안받을 것이고 Negative Sample들은 다른것과 무관하다.
-
에러를 줄이기위해, 회귀모델은 CNN의 특성들을 사용한 Bounding Box 수정 offset에서 예측된 검출 window를 맞추기 위해 학습되어질 것이다.