ELMO - Deep contextualized word representations [2018]
ELMO
기존 word2vec, Glove 등에 비해 context 정보를 반영하는 Pre-training 방법을 제시합니다. 여러층의 BiLSTM을 이용해 Language Model을 하며, 만들어진 hidden-state를 적절하게 조합해 새로운 word representation을 만들어냅니다.
- 사전 훈련된 모델을 사용한다
- 사전훈련된 문맥을 고려하는 문맥반영 언어모델(Contextualized Language Model)
- Representation은 문장 내 각 token이 전체입력 시퀀스의 함수인 representation을 할당받는 점에서 전통적인 단어임베딩과 다르다
- 이를 위해 이어붙여진 언어모델로 학습된 BiLSTM으로부터 얻은 vector를 사용
- 복잡한 형태를 가지는 데이터(word)를 모델링
- 다양성을 가지는 언어(polysemy=동음이의어)도 catch 가능
다소 복잡한 특징을 가지는 데이터에 대해 모델링을 하고, polysemy와 같은 다양성에 대해 나타나는 언어들에 대해 각각 다른 Embedding vector를 구성가능합니다. 즉, 단어를 임베딩하기전에 전체 문장을 고려하여 임베딩을 할 수 있는 것입니다.
Context Matters

눈이란 단어에 대해 2가지 해석이 가능합니다.
- 신체기관 중 하나인
eye의 뜻을 가지는 단어인 눈 - 겨울철 나타나는 기상현상
snow의 뜻을 가지는 단어인 눈
ELMO는 한 단어가 가지는 다른 뜻에 대한 정보를 모델링할 수 있습니다. 그 후, contextualized word-embedding vector가 도출될 것입니다. 이는 단어가 가지는 각기 다른 의미에 대해 embedding 할 것이고, 그 후, context의 문장에 전달될 것입니다.
특징
- 각각의 토큰은 representation을 할당받는데, 이는 전체 입력문장의 함수입니다.
- BiLSTM을 사용해 언어모델을 학습시켰습니다. 이를 통해, 도출되는 내부 레이어에서의 hidden vector들을 결합하는 방식을 차용했습니다.
- 기존의 방법들과는 다르게 Top level의 LSTM정보만을 이용하지 않고, 각 level의 hidden state들을 조합하여 새로운 단어 representation을 만들어냅니다.
Mechanism
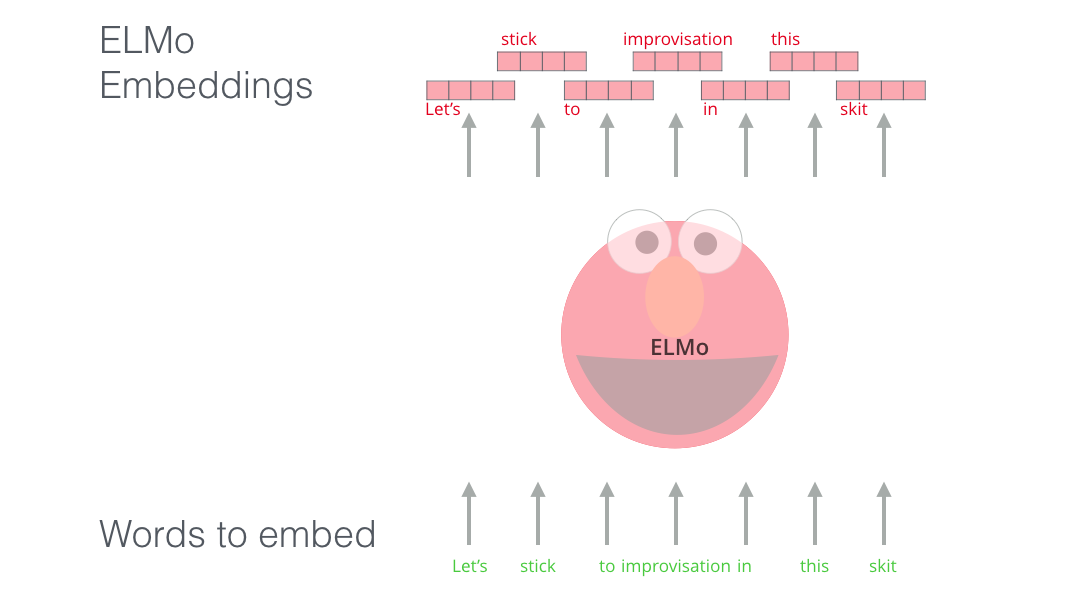
단어 각각에 ELMO를 적용시켜 embedded vector를 산출합니다.
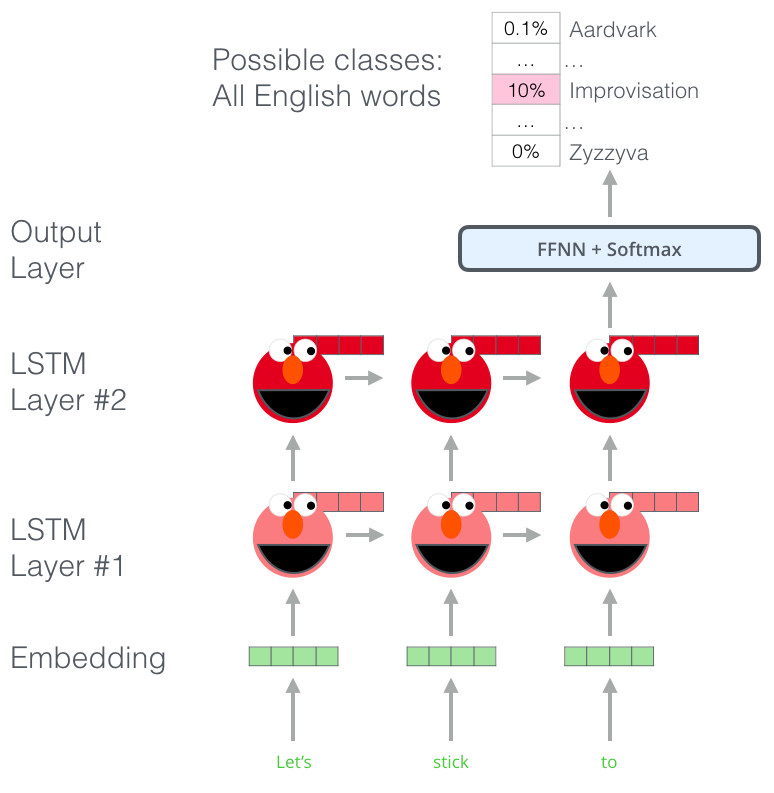
A step in the pre-training process of ELMo: Given “Let’s stick to” as input, predict the next most likely word? a language modeling task. When trained on a large dataset, the model starts to pick up on language patterns. It’s unlikely it’ll accurately guess the next word in this example. More realistically, after a word such as “hang”, it will assign a higher probability to a word like “out” (to spell “hang out”) than to “camera”.
ELMO는 기본적으로 sequence의 단어속에서 다음 단어를 예측하는 언어모델입니다. 각각의 입력 임베딩벡터는 2개의 LSTM layer를 거쳐 10%의 확률값을 가지는 Improvisation을 최종 예측합니다.또한 언어모델이 다음단어의 정보를 가지고 있지않기때문에 step을 통해 BiLSTM을 학습시킬 것입니다.
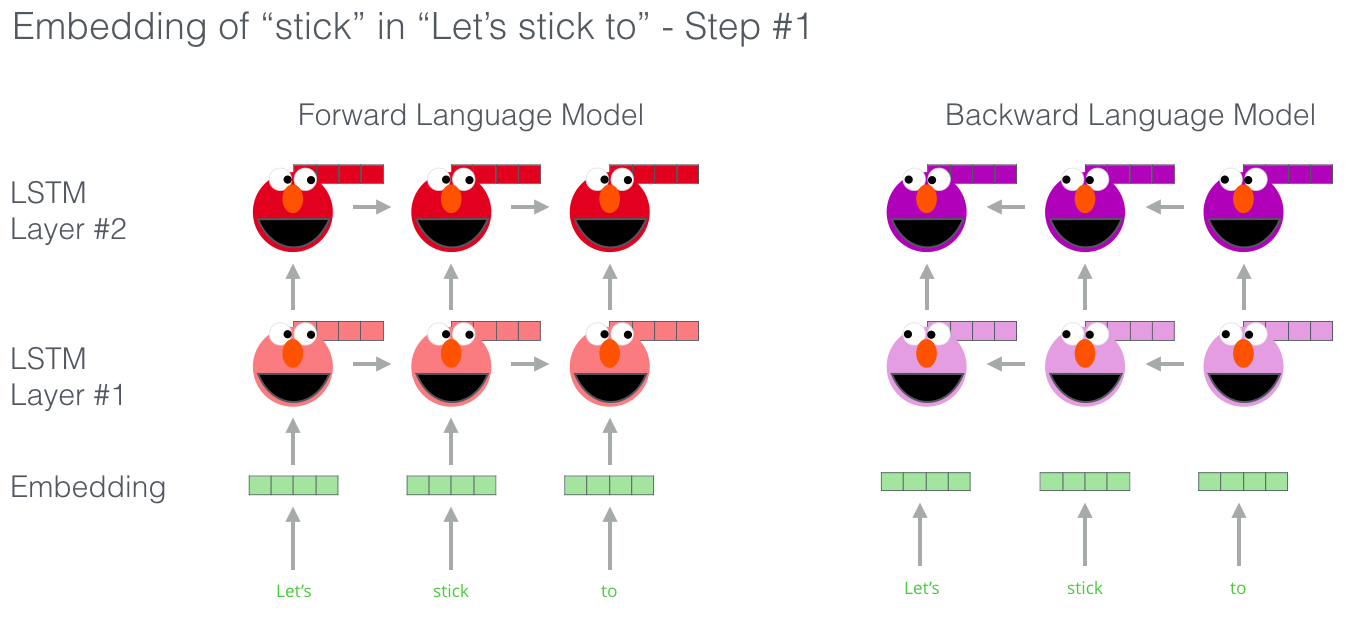
ELMO는 Bi-directional LSTM을 통해 학습하기 때문에 Forward LM, Backward LM 둘다 학습합니다.
- Forward LM : 앞방향, 순차적으로 학습시키는 모델
- Backward LM : 뒤쪽 단어부터 역방향으로 학습시키는 모델
그룹화시킨 hidden state를 통해 문맥을 반영한 embedding을 제시하는데 이는 가중합을 위해 concat할 예정입니다.
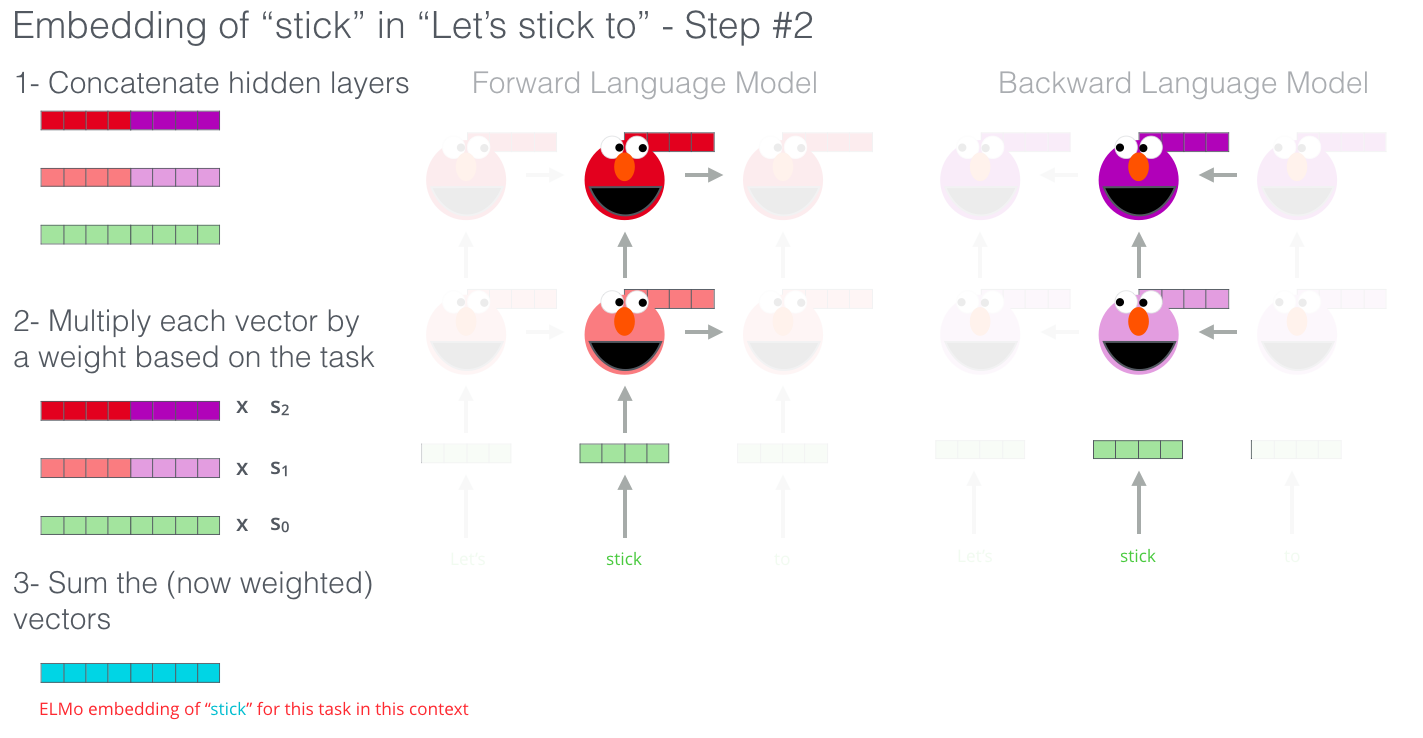
두 가지 LM을 통해 나타난 ELMO의 vector는 두 모델에서의 시점이 같아야합니다.
동일한 level에 있는 embedding 값(hidden state 값)을 concat하여 Concatenate hidden layer를 도출해냅니다.
또한 task에 대해 적절합 가중합($s_0$, $s_1$, $s_2$)을 계산해 최종 embedding 값을 도출해냅니다.
layer를 weighting시키는 방법엔 두가지가 있습니다. 첫째, task에 맞게 적절하게 조정하는 방법. 둘째, 모두 똑같은 가중치로 설정해주는 방법.
Experiments
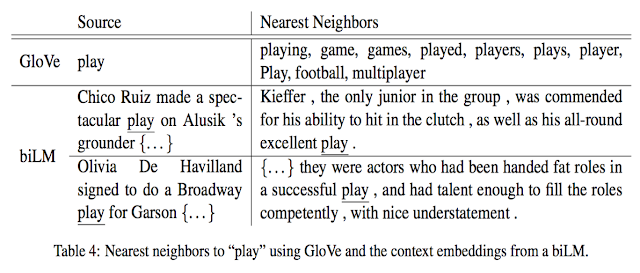
Glove를 통해 얻은 play에 대한 벡터와 ELMO를 통해 얻은 play에 대한 벡터를 비교한 표입니다.
Glove는 단어의 representation이 고정되어 있기때문에 play처럼 여러 뜻을 가지고 있는 단어의 경우, 여러 의미를 단어 representation에 담기 어렵습니다.
하지만 ELMO의 경우, LSTM의 이전 step에 입력된 단어에 따라 현재단어에 해당하는 projection vector들이 변하기 때문에 context에 따라 얻어지는 play에 대한 벡터가 다릅니다.
첫번째 source문장을 통해 얻어진 play의 벡터는 운동경기에 대한 의미를 나타내어야 하는데, nearest neighbor를 구해봤을 때, 두 play의 의미가 비슷하다는 것을 알 수 있습니다. 반면, 두 번째 source문장은 연극에 대한 의미를 반영하는 것을 볼 수 있습니다.