IA3 - Few-shot Parameter-Efficient Fine-tuning is better and cheaper than In-Context Learning [2022]
Introduction
ICL이라고 불리는 In-context Learning 방식은 프롬프트된 예제를 인풋에 넣음으로써 downstream task에서 더 잘 작동하게 만들어 주는 방식을 의미함. 특히 ICL은 gradient-based 학습이 필요하지 않기에 단일의 모델에 즉시 다양한 task에서 적용이 가능하다.
ICL의 이러한 이점에도 불구하고 몇몇의 문제점이 존재함
- input-target 쌍의 프롬프트된 데이터가 모델이 prediction을 계산하게 할 때 많은 양의 compute cost가 발생되게 한다
- ICL은 전형적으로 파인튜닝과 비교하여 질낮은 성능을 생산해낸다
- 프롬프트의 정밀한 formatting은 모델의 성능면에서 다양하고 예측불가한 영향을 끼친다
본 연구의 목표는 적은 모델의 파라미터만을 업데이트 함으로써 novel 또는 unseen task에서 효과적인 성능을 가지는 모델을 만드는 것. T0모델과 다양한 T5모델을 파인튜닝하여 사용하였음.
성능을 향상시키기 위해 unlikelihood와 normalization-based loss terms를 추가하였으며 학습된 vector로부터 즉시 activations을 연산할 수 있는 $(IA)^3$ method를 개발하였음. 이는 full-fine-tuning 모델보다 약 1만배에 달하는 파라미터를 덜 학습시킴에도 더 강력한 performance를 얻을 수 있는 방법론임.
Background
Few-shot in-context learning (ICL)
ICL은 레이블이 지정되지 않은 쿼리 예제와 함께 연결되고 프롬프트가 표시된 입력 대상 예제(“샷”이라고 함)를 레이블이 지정되지 않은 쿼리 예제와 함께 제공함으로써 모델을 유도하는 것을 목표로 합니다. ICL의 이점은 파인튜닝 없이 즉시 많은 task에 단일의 모델을 적용할 수 있는 점입니다. 이는 또한 mixed-task batches를 가능하게 만들어주며 데이터 배치의 여러 예시가 서로 다른 컨텍스트를 사용하여 서로 다른 작업에 해당하는 작업도 가능합니다.
이러한 이점에도 불구하고 ICL method는 엄청난 compute cost를 소모함
PEFT
PEFT는 모델을 학습할때 필요 메모리를 급격하게 줄여주는 역할을 함. 추가적으로 PEFT method는 mixed-task batches를 가능하게 만들어 줌. 예를들어, prompt tuning은 단일의 모델을 다양한 task에 단순하게 다른 prompt embedding을 각각의 batch에서 concat함으로써 적용 가능하게 만들어줌. 반면에 re-parameterize하는 PEFT method는 mixed-task batches 작업에 resource가 매우 많이 소모됨.
Adapter들은 효율적으로 모델에 작은 layer를 추가할 수 있으나 결과적으로 매우 적거나 무시할 수 없을 정도로 계산 cost와 memory를 향상시킴. PEFT로부터 발생된 추가적은 cost는 반드시 한 번 performed 하고 그러고나서 inference를 위해 model에 amortized되어 짐. (cost 청구)
그러나 연구진은 fine-tuning과 inference둘 다 모두 고려했을때, PEFT가 급격하게 계산적으로 효율적일 수 있는지 밝혀냈음
Designing the T-Few Recipe
연구진은 PEFT가 ICL의 대안이라고 생각함. 그렇기에 연구진의 목표는 최소한의 gpu memory와 computational cost를 사용하면서 새로운 task에 제한된 레이블로 높은 정확도를 뽑아주는 모델을 만들고 싶어함. 그래서 manual적인 튜닝이나 각 task별로 특화된 조정없이 강력한 performance를 뽑아주는 특정한 모델을 만들길 요함. 연구진의 방법론은 few-shot setting에서 존재하는 현실적인 대한이 될 것으로 믿고 있음.
Model and Datasets
- T0는 T5를 파인튜닝한 모델로 multitask mixture 데이터셋을 사용하였으며 zero-shot generalization을 가능하게 만들기 위해 생성되었음
- Public Pool of Prompts(P3) template 사용
- 실험에 T0-3B 모델 사용
- sentence completion, NLI, RAFT 등 다양한 benchmark 수행할 예정 (few-shot)
Unlikelihood Training and Length Normalization
Few-shot fine-tuning 언어모델의 성능을 향상시키기 위해 2개의 loss term 발견. 연구진은 rank classification을 사용하였고 옳은 선택을 할당하는 모델의 가능성 뿐만 아니라 정답이 아닌 선택을 하는 모델을 할당하는 가능성도 참조하였음. 학습하는 동안 unlikelihood loss를 추가하는것을 고려하였음.
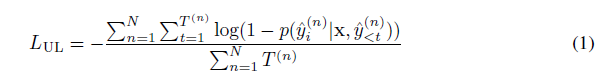
주어진 학습예제를 위한 가능한 target sequences는 특히 multiple-choice task에서 다른 length를 가지고 있음. 그렇기에 가능성에 기반을 둔 각 선택에 대한 rank는 더 짧은 선택에 대해 호의적일 것. 왜냐하면 각 토큰에 모델의 할당된 가능성은 1보다 적거나 같기 때문임. 이 오류를 바로잡기 위해 연구진은 length normalization을 rank classficiation 실행시에 사용하였고 이는 각각의 가능한 답변의 선택에서 모델의 점수를 나눔.
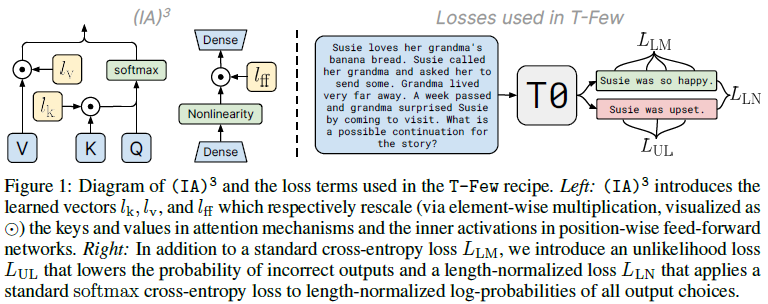
PEFT with $(IA)^3$
Few-shot ICL과의 비교실험
- 메모리 이슈를 피하기 위해 가능한 적은 파라미터를 추가하거나 업데이트 해준다
- 새로운 task에 대해 few-shot 학습이후 강력한 정확도를 달성해야한다
- ICL의 capability이기에 mixed-task batches를 가능하게한다
모델을 독립적이고 더 값싸게 적용하게 하기 위해 직접적으로 activation함수를 수정하는 방법을 사용하여 더 편리한 대안을 제공할 수 있음. Prompt tuning과 prefix tuning 방법론은 학습된 벡터를 활성화함수나 embedding sequence에 합침으로써 동작하고 그러고난후에 activation-modifying PEFT method의 example은 mixed-task batches를 가능하게 만들어 줌. 그러나 이러한 방법가지곤 이상적인 정확도를 얻는 모델을 만들 수 없음. 그렇기에 새로운 PEFT method를 개발하였음.
학습된 vector에 대한 모델 활성화함수의 element-wise multiplication에 대해 연구 진행. 특히 학습된 task-specific vector의 적용 양식에 대해 고려하였음. broadcasting notation. 연구진은 트랜스포머 모델에서 활성화 함수의 각 set을 통해 학습된 rescaling vector를 연구하면서 이것이 꼭 필요하지 않을수도 있다는 것을 발견해냈음. 대신, 우리는 self-attention 메커니즘에 key와 value에 대한 self-attention 및 encoder-decoder attention 메커니즘의 key와 value에 vector를 재조정하고 그리고 position-wise fedd-forward의 중간 activation에 rescaling vector를 도입하는 것으로 충분했음. 이에 연구진은 3개의 학습된 vector를 소개합니다.
$l_k\in R^{d_k}$, $l_v\in R^{d_v}$, $l_{ff}\in R^{d_{ff}}$
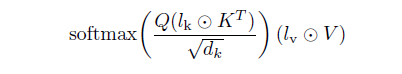
$(IA)^3$는 mixed-task batches를 가능하게 만들어주는데 각각의 sequence의 활성화함수를 연관되어진 학습-task vector를 독립적이며 더 값싸게 연산할 수 있기 때문임. 모델은 단일의 task에서 사용되어질 것이고 모델의 구조는 바뀌지 않은 채로 유지될 것이고 element-wise mulitiplication이 요구되어지지 않기에 $(IA)^3$ 로부터 소개되어진 수정된 모델 또한 영구적으로 가중치 매트릭스를 적용되어질 것임. 이는 EWM이 $(IA)^3$과 행렬곱셈과 함께 항상 같이 발생되에 가능한 형태임. 이러한 케이스의 경우, 연구진의 method는 기존 모델과 비교하여 연산 cost없이 학습될 수 있음.
$(IA)^3$를 평가하기 위해 폭넓은 다양한 적용 method를 셋팅 (9가지)
BitFit: bias parameter만을 업데이트. Adapter는 self-attention 그리고 position FFN이후에 task-specific layer를 접하게 됨Compacter(++): low-rank matrices와 hypercomplex multiplication을 사용함으로써 adapter를 향상Prompt tuning: 모델의 Input data와 concat하여 task-specific prompt embedding을 학습FISH Mask: 인접한 Fisher information을 기반으로 하여 업데이트하기 위해 파라미터들의 subset을 선택Intrinsic SAID: 낮은 차원의 여유공간에서 optimization을 수행prefix-tuning: 모델의 활성화함수를 합친 task-specific vector를 학습LoRA: 파라미터 행렬에 낮은 순위의 업데이트를 할당- 추가적으로 full-fine-tuning baseline 모델과 오직 layer-normalization parameter를 업데이트하는 방법도 포함
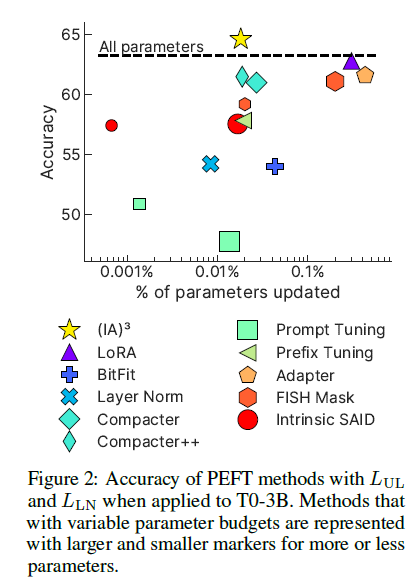
결과가 기존 PEFT 실험과는 조금 다름. 다른 모델과 다른 데이터셋을 사용하기에 불일치에 대해 특정한 가설을 세웠음. 특히 prompt tuning에서 연구진은 validation set performance가 학습중에 변동을 급락한다는 것을 알았고 이는 optimization issue에서 힌트를 얻었음
Pre-training $(IA)^3$
최근 연구에 의하면, prompt tuning에서 prompt embedding은 downstream few-shot task에서 성능을 향상시켜 준다는 것이 밝혀졌음. 사전학습을 위해 연구자는 레이블되지 않은 데이터를 자기지도학습 task에 적용하였고 또한 분리된 task나 multitask mixture로부터 embedding을 사용하는것을 고려하였음. 이에 본 연구진은 사전연구에 착안하여 간단하게 $(IA)^3$로부터 접하게 된 새로운 파라미터들을 사전학습시켰음. (T0 모델 사용) 각각의 개별 downstream taks에서 batch size 16, 10만 step을 통해 사전학습진행.
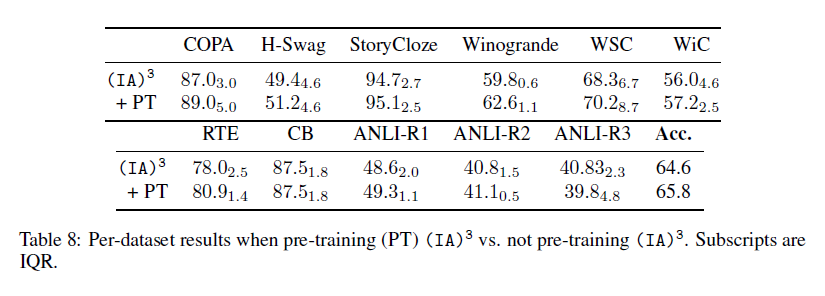
Combining the ingredients
- backbone : T0
- $(IA)^3$ pre-training
- standard LM loss : $L_{LM}$
- unlikelihood loss (incorrect choice) : $L_{UL}$
- length-normalized loss : $L_{LN}$
- train step : 1,000
- batch size : 8
- linear decay schedule with 60-step warmup
- apply to instructive format of prompt template
위 recipe를 매 데이터셋에 수정이나 하이퍼파라미터 수정없이 매 downstream dataset에 정확히 같은 방식으로 적용하였음
Outperforming ICL with T-Few
Performance on T0 tasks
Few-shot 모델이 zero-shot 모델보다 더 성능이 좋지 않았기에 T0 모델과 zero-shot learning에 대해 비교하였음.
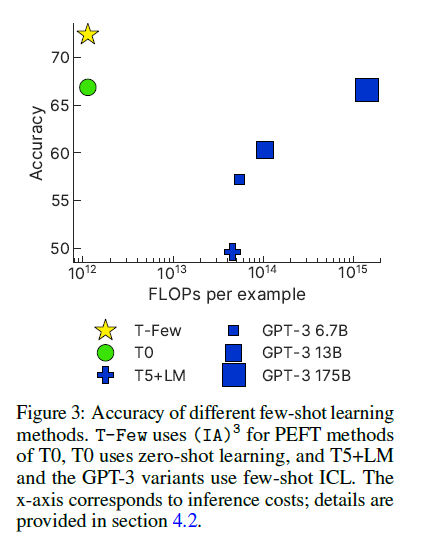
Comparing computational costs
측정 지표 : FLOPs-per-token
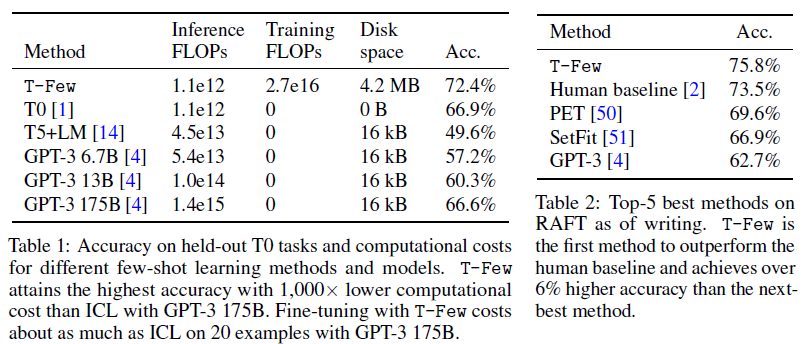
Inference cost. 정확도는 오른 반면에 few-shot ACL은 급격하게 inference cost가 감소되었음. T-Few는 $11e9 \times 103 == 1.1e12$ FLOPs인데 반해 few-shot ICL with GPT-3 175B 모델은 $1.4e15$ FLOPs로 측정되었음. Inference cost 마찬가지로 T-Few에 비해 급격하게 높은 cost가 측정되었음. 같은 세트의 in-context example로 재사용될때 캐싱된 key와 value vector가 ICL의 연산 cost를 줄일 수 있음. 그러나 그러나 이는 단지 약 41% 감소에 불과하며, 이는 GPT-3 ICL 비용을 T-Few만큼 낮추기에는 충분하지 않음.
Training cost. T-Few는 오직 파라미터만을 업데이트하는 방법이기에 training cost만을 발생시킴. En-decoder 11B 모델이 1000step, batch size 8, length 103일때, 요구되는 memory는 $3 \times 11e9 \times 1000 \times 8 \times 103 == 2.7e16$ FLOPs임. 이는 GPT-3 175B을 20개의 예제에서 few-shot ICL을 사용한것만큼의 cost임. 또한 연구진은 T0 모델을 T-Few 방식으로 단일의 데이터셋에서 파인튜닝했을때, A100을 사용하여 30분밖에 소모되지 않았음을 밝혀냈고 Azure 기준으로 2달러밖에 소모되지 않았음.
Storage cost. Single-precision floats를 적재했을때, $(IA)^3$ 로부터 추가된 파라미터는 4.2MB의 공간을 차지함. 대조적으로 ICL method는 오직 토크나이즈된 in-context example만을 적재하며 결과적으로 더 적은 $41 \times 98 \times 32bits = 16kB$ 만큼만을 필요로합니다. 그러나 4.2MB 또한 매우 적은 용량으로 기존 backbone model T0의 checkpoint인 41.5GB보다 훨씬 적은 storage cost입니다.
Memory usage. Inference시에 memory cost는 모델의 파라미터 수에 의해 결정됩니다. T0(with T-Few) 모델보다 더 적은 모델은 GPT-3 6.7B. T-Few는 inference 딴에서 더 적은 memory cost를 발생시킬것. 추가적인 메모리 비용은 Adafactor에서의 gradient acculuator, backpropagation 동안 중간의 활성화함수가 cache를 필요로하기에 T-Few를 학습할 때 발생될 것. 그러나 언급했듯이, T-Few recipe는 단일의 A100 80GB에서도 사용 가능함.
Performance on Real-world Few-shot Tasks (RAFT)
RAFT는 11개의 economically valuable task로 구성되어 있고 that aim to mirror real-world applications. 각각의 RAFT 데이터셋은 오직 50개의 학습 예제가 있으며 validation set은 존재하지 않고 test set은 label이 없음.
이에 연구진은 T-Few를 RAFT를 기존의 prompt 데이터셋을 사용함으로써 적용하였음. 학습 결과는 Table 2에 있음.
Ablation experiments
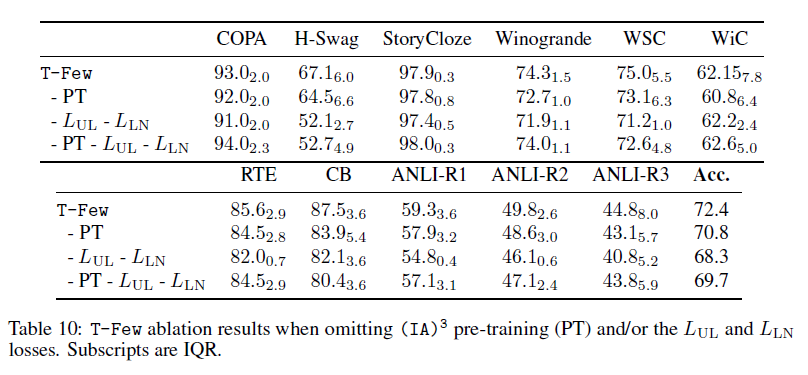
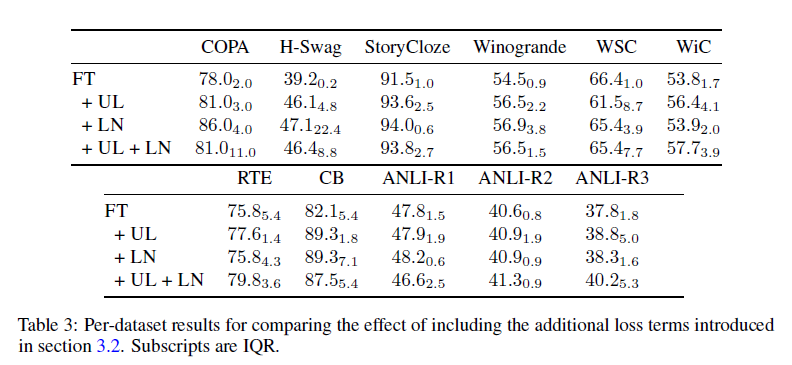
각각의 ingredient가 항상 정확도를 올려주는 건 아니었지만 그래도 꾸준하게 성능을 향상시켜주었음.
Conclusion
$(IA)^3$를 사용하여 오직 적은 양의 파라미터만을 반영하여 full-fine-tuning 모델보다 더 좋은 성능을 뽑아내는 모델을 만들 수 있게 되었음. T-Few는 또한 2개의 추가적인 loss term을 사용하는데 모델이 잘못된 선택에 대해 더 낮은 확률을 출력하도록 유도하고 다른 답안의 길이를 고려함. RAFT benchmark에서 큰 폭의 차이로 좋은 성능을 뽑아냈음. GPT-3 모델(w few-shot ICL)보다 FLOPs 성능이 더 좋았으며 단일의 A100 GPU로 파인튜닝 성공하였음.
의의
- 한계점 - 논문은 classification task에서만 experiments를 진행하였음
- Scaling-law를 정면으로 반박할 수 있는 근거를 제공하는 논문
- LoRA method 이후, 더 낮은 resource로 양질의 Fine-tuning 모델을 생산 가능