ConvNeXt - A ConvNet for the 2020s [2022]
Instruction
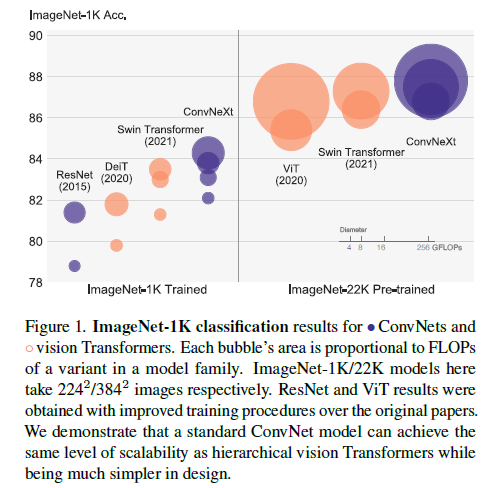
지난 10년간 딥러닝의 ConvNet은 많은 발전을 이루어왔고 아키텍쳐를 디자인하기위한 engineering features는 성공적으로 변화되어져 왔습니다. VGGnet, Inception 등과 같은 많은 ConvNet은 정확도, 효율성 등과 같은 다른 측면에서 집중해왔으며 많은 실용적인 디자인 요소들로부터 유명해졌습니다. CV 분야에서의 ConvNet의 가치는 우연이 아닌게 sliding window 전략과 같은 것들로 인해 고유한 진보가 이루어 질 수 있었습니다. ConvNets은 Inductive bias를 적용시켜 CV의 다양한 task에 잘 적용시켰습니다. ConvNets의 기본값으로 수십년간 이러한 요소들을 사용하여 다양한 task에서 ConvNet의 기조적인 fundamental을 잘 높여왔습니다.
비슷한 시기에, NLP 분야에서 Trasnformer는 RNN을 대체하여 매우 dominant한 백본 아키텍쳐로 대체되는 매우 다른 길을 개척하게 되었습니다. CV와 NLP의 task가 전혀 다른 분야임에도 불구하고, 2020년대에 들어서 이 2개의 줄기는 놀랍게도 융합되어지고 있습니다. 이미지를 sequence of pathches로 나누는 patchify를 제외하고, ViT는 이미지 특정적인 inductive bias를 만들었으며 최초 NLP Transformers에 최소한의 변화만을 꾀하는 연구결과를 내놓았습니다. ConvNet의 inductive bias없이, vanilla VIT는 일반적인 CV 태스트에서 backbone 역할을 하게 되었습니다. 이에 가장 큰 main-thought는 바로 ViT’s global attention design이었고 이는 인풋 사이즈와 관련하여 quadratic-complexity를 갖는 디자인입니다. 이는 ImageNet Classification에 적용되으나 해상도가 높은 이미지에 대해서는 아주 다루기 힘들게 되었습니다.
계층적 트랜스포머는 이 간극을 연결하기 위해 hybrid 접근법을 사용하였습니다. 예를들어 “sliding window”전략은 트랜스포머에서 재사용되어졌으며 이를 통해 ConvNets과 더 면밀하게 작동하는 것을 가능케 해줍니다. Swin Transformers는 처음으로 vision task에서 backbone으로 트랜스포머 모델이 사용되었으며 다양항 CV task에서 SOTA를 달성하였습니다.
이러한 관점에서 CV를 위한 트랜스포머는 많은 성과를 달성하였습니다. 그러나 이러한 시도들은 cyclic shifting과 같은 sliding window self-attention 적용시 나타나는 비싼 cost, 속도가 최적화되긴 했으나 복잡한 디자인이 되었습니다. 반면에 아이러니하게도 ConvNet은 무질서한 방법일지라도 벌써 많은 욕구들을 충족시켜왔습니다. 단지, ConvNet이 트랜스포머 계열 모델보다 뒤쳐지는 것은 많은 task에서의 성능이며 이는 트랜스포머의 multi-head self-attention와 같은 key component 덕분일 것입니다.
지난 10년간 점진적으로 향상되어진 ConvNet들과는 달리 Vision Transformers의 적용은 큰 변화였습니다. 최근 연구에 의하면 system-level의 비교(e.g. Swin-T vs ResNet)는 2개를 비교할때 종종 비교되어지곤 합니다. ConvNets과 계층적 vision transformer들은 동시에 다르거나 비슷하게 될 수도 있습니다. 이 두 모델은 비슷한 inductive bias를 가지나, 매우 다른 학습 절차나 micro-level의 아키텍쳐 디자인을 가집니다. 본 연구진은 ConvNets과 트랜스포머의 아키텍쳐를 조사하였으며 network의 성능에 대해서도 명확히하는 연구를 진행하였습니다. 우리의 연구는 pure ConvNet의 한계를 테스트할 뿐만 아니라 pre-ViT와 post-ViT 사이의 간극을 연결해주는 의도를 가지고 연구를 진행하였습니다.
이에 연구진은 standard-ResNet을 향상된 학습 절차와 함께 연구를 진행하였으며 점차 계층적인 비젼 트랜스포머의 구조르에 대해 아키텍쳐를 현대화 하였습니다.
트랜스포머의 design decision이 ConvNets의 성능에 어떤 영향을 미칠까? 이에 본 연구진은 성능에 기여하는 몇가지 주요한 구성요소들을 발견해 냈습니다.
Modernizing a ConvNet: a Roadmap
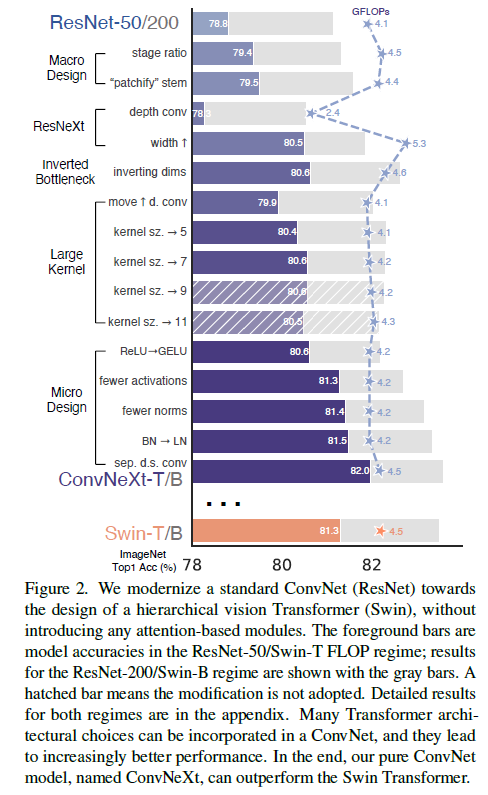
이 실험은 기존의 ConvNet으로써 네트워크의 간단함을 유지하는동안 Swin-T로부터 다른 레벨의 디자인을 따르고 조사하길 지시되었습니다. 첫 시작 모델은 ResNet-50입니다. 첫째로 ViT와 유사한 학습 방식을 통해 학습하였고 기존 ResNet-50 모델과 비교되게 향상된 결과를 얻었습니다. 이 결과는 본 연구의 baseline이 됩니다. 연구진은 design decision의 시리지를 연구하였고 요약한 내용은 다음과 같습니다.
- macro design
- ResNeXt
- Inverted bottleneck
- large kernel size
- 다양한 layer-wise micro design
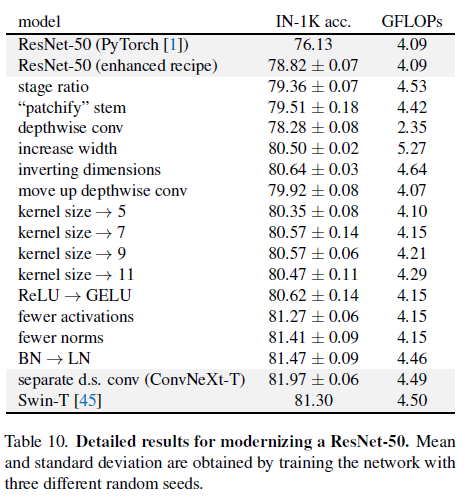
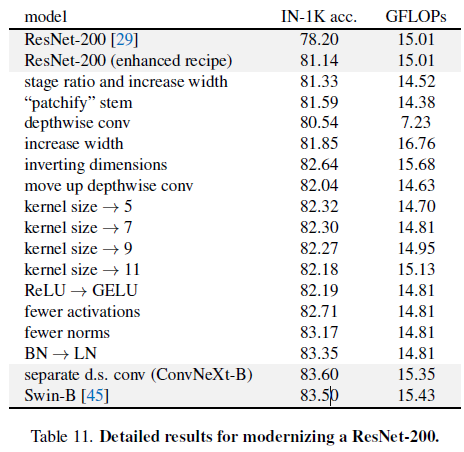
Figure2에 이에 대한 절차와 결과가 나타나며 연구진은 각 스텝의 network modernization을 이루어냈습니다. 네트워크의 복잡성은 최종 성능과 면밀하게 상관적인 관계에 있기 때문에, 탐색 과정에서 FLOP은 대략적으로 제어되지만, 중간 단계에서는 FLOP이 참조 모델보다 높거나 낮을 수 있습니다. 모든 모델들은 ImageNet-1K task에서 학습되거나 평가되었습니다.
Training Techniques
네트워크 구조의 디자인외에도 학습 절차는 또한 궁극적인 성능에 영향을 미칩니다. ViT가 구조적인 design decision과 모듈의 새로운 set을 가져왔을 뿐만 아니라 vision에 있어서 다른 학습 테크닉(AdamW optimizer)을 소개해주었습니다. 이는 대개 최적화 전략이 존재하며 하이퍼파라미터 셋팅과 연관되어있습니다. 따라서 본 연구의 첫번째 단계는 ViT의 학습 절차를 baseline model에 학습하는 것입니다. 최근 연구에 의하면 최산화된 학습 테크닉은 단순한 ResNet-50 모델의 성능을 매우 강화시켜 줄 수 있음이 밝혀졌습니다. 이 연구에서는 DeiT 또는 Swin-T의 학습 테크닉과 비슷한 방법을 취하였습니다. 최초 ResNet의 90 epoch에서 300까지 확장시켰습니다. Mixup, Cutmix, RandAugment, RandomErasing과 같은 데이터 증강 방식을 차용하였으며 AdamW 옵티마이저, Stochastic Depth, Label Smoothing과 같은 regularization 방식도 사용하였습니다. 자세한 하이퍼파라미터는 아래에 명시되어 있습니다.
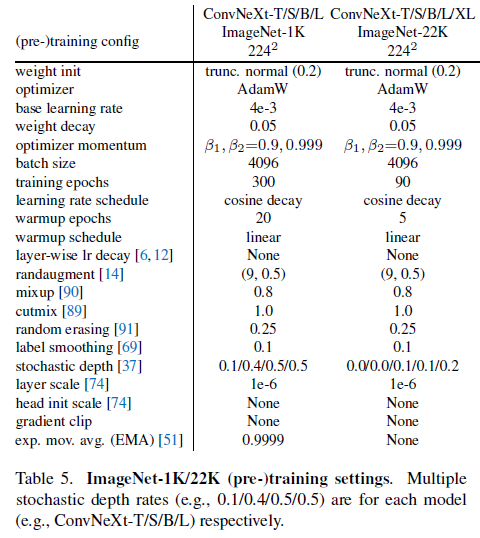
이러한 학습 방식을 통해 ResNet-50 모델은 기존 76.1%에서 2.7% 포인트 상승한 78.8%의 성능을 기록하였습니다. 같은 하이퍼파라미터와 함께 이 고정된 학습 방식을 Modernization 절차로 사용할 것입니다.
Macro Design
연구진은 Swin-T의 매크로 네트워크 디자인을 분석하였습니다. Swin-T는 각 stage가 다른 feature map resolution을 가지기에 multi-stage 디자인을 사용하기 위해 ConvNet을 따릅니다. 여기에 2가지 맹점이 존재합니다.
- The stage compute ratio
- Stem cell structure
Changing stage compute ratio. ResNet에서 기존 디자인의 연산 분포는 대개 실증적입니다. 더 무거운 모델인 Res4 stage는 OJ과 같은 다운스트림 태스크에서 detector head가 14x14 feature plane으로써 작동하는하여 양립함을 의미합니다. 반면에 Swin-T는 동일한 원칙을 따르지만 1:1:3:1의 다른 stage 연산 비율을 가집니다. Swin-L의 비율은 1:1:9:1 입니다. 이 디자인에 참고하여 연구진은 ResNet-50모델을 각 stage에서 block의 개수를 (3, 3, 9, 3)에서 (3, 4, 6, 3)으로 조정하였으며 또한 Swin-T와 함께 FLOPs를 조정하였습니다. 이 방식을 통해 78.8%에서 79.4%로 성능이 향상되었습니다. 특히 연구자들은 철저하게 연산의 분포를 조사하였고 더 최적의 디자인이 있다는 것을 조사하였습니다.
Changing stem to “Patchify”. 전형적으로 stem cell은 Input Image가 어떻게 network의 시작점에서 제공되어질 예정일지에 따라 연결되어집니다. 내재된 위협 때문에, 공동적인 stem cell은 급격하게 Input Image를 적절합 feature map 사이즈에 맞춰 다운샘플링합니다. Vision Transformers에서는 좀 더 공격적으로 “patchify” 전략을 stem cell에 취하는데 이는 큰 커널 사이즈와 non-overlapping convolution에 상응합니다. Swin-T는 유사한 patchify layer를 사용하나, 아키텍쳐의 multi-stage 디자인에 수용하기위해 더 적은 patch size인 4를 적용합니다. 본 연구진은 ResNet-스타일의 stem cell을 4x4 사이즈를 사용한 patchify lyaer와 stride 4를 적용한 convolution layer로 대체하였습니다. 이 결과 성능이 0.1% 향상되었습니다.
ResNeXt-ify
이 파트에서 연구진은 vanilla ResNet보단 FLOPs과 정확도에서 더 좋은 성능을 보이는 ResNeXt의 아이디어를 적용시켰습니다. Grouped Convolution 은 메인 구성요소입니다. 또한 ResNeXt의 guiding principle은 더 많은 그룹과 확장된 width를 사용하는 것 입니다.
본 연구엔 depthwise convolution을 사용하였고 channel의 수와 group의 수가 같을땐 grouped convolution을 적용하였습니다. Depthwise Convolution은 Self-attention의 weighted sum operator와 유사합니다. 이는 매 channel 기반에서 작동합니다. Depthwise conv와 1x1 conv의 결합은 channel 혼합과 공간적인 분리를 초래하며 이는 비전 트랜스포머가 공유하는 속성입니다. 공간 또는 채널 차원에 걸쳐 정보를 혼합하지만 둘 다는 아닙니다. 예상했듯이, FLOPs과 정확도 모두 감소하였습니다. (trade-off 관계)
Inverted Bottleneck
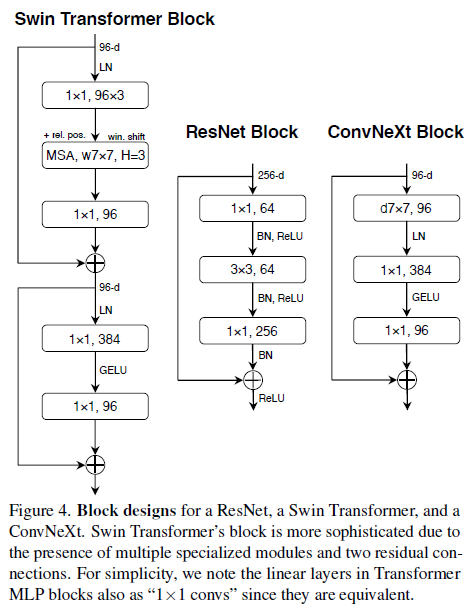
매 Transformer block의 중요한 design은 inverted bottleneck을 만들어내는 것입니다. 흥미롭게도 Transformer 디자인은 ConvNet에서 사용된 expansion ratio값 4와 함께 inverted bottleneck 디자인에 연결되었습니다.
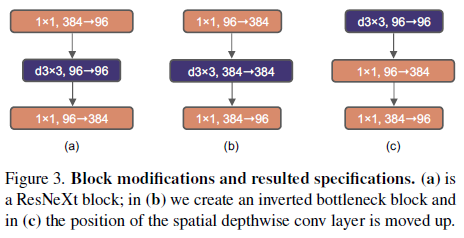
Figure 3의 a -> b. epthwise Convolution 레이어에서 FLOPs 값이 증가함에도 불구하고, 이 변화는 다운샘플링하는 residual block의 shorcut 1x1 컨볼루션 레이어에서 큰 FLOPs의 감소 덕분에 전체 네트워크 FLOPs을 줄여줍니다. 정확도 0.1% 포인트 향상되었으나 ResNet-200, Swin-B 모데에선 0.7% 포인트 상승되었고 FLOPs은 줄었습니다.
Large Kernel Size
Vision Transformer의 가장 특색 있는 측면은 바로 non-local self-attention입니다. 이는 각 레이어가 전역적인 receptive field를 가지는 것을 가능하게 해줍니다. 과거 ConvNet에서 큰 kernel size를 사용하였으나 gold-standard(=Label)는 적은 kenrel-sized(3x3) conv 레이어를 쌓는것이며 이는 현대의 GPUs에서 효율적인 하드웨어 실행방식을 가능하게 해줍니다. 비록 Swin-T가 self-attention block에서 local window를 재소개하였음에도 불구하고 window size는 최소 7x7를 가지며 최대 ResNe(X)t의 kernel size인 3x3보단 커야합니다.
Moving up depthwise conv layer. 큰 kernel을 연구하기 위해, 하나의 필요충분조건은 바로 depthwise conv layer의 위치를 Figure 3 (b) to (c)의 형태로 이동시키는 것입니다. 이는 Transformer에서의 영감을 받아 design decision을 하였습니다. MSA block은 MLP layer전에 대체되었습니다. 연구진은 inverted bottleneck block를 가지고 있기에 이러한 자연스러운 design을 선택하였습니다. 복잡하고 비효율적인 모듈 (e.g., MSA, large kernel size conv)은 더 적은 channels을 가지게 될 것이고, dense 1x1 레이어는 무겁게 실을 것입니다. 이를 통해 FLOPs에서 성능 효과를 보았습니다.
Increasing the kernel size. 3, 5, 7, 9, 11을 가지는 몇몇의 kernel size에서 실험을 진행하였습니다. 해당 네트워크의 성능은 FLOPs은 그대로였고 정확도는 79.9% (3x3 k_s) 에서 80.6% (7x7 k_s) 까지 증가하였습니다. 추가적으로 큰 kernel size를 설정하는 것의 이점은 7x7 사이즈에서 saturation point에 도달하였습니다.
Micro Design
- ReLU 대신 GELU로 대체
- 그간 ConvNet에서 간단하고 효율적인 이유로 ReLU Activation Func이 많이 사용되어왔고 Transformer 원논문에서도 사용.
- GeLU는 ReLU보다 더 부드럽게 변수를 처리해줄 수 있고 최근 많은 연구에서 사용되어지고 있는 추세
- 대체 결과 80.6%로 성능 차이는 없었음
- 더 적은 activation function 사용
- ResNet과 Trasnformer사이의 가장 큰 특별한 점은 Transformer가 더 적은 활성화 함수를 가지고 있다는 것
- Transformer block에 K/Q/V 선형 임베딩 레이어, projection 레이어, MLP block에서 2개의 linear 레이어가 있다고 가정해봤을때 활성화 함수는 MLP block에서 단 1개만 존재합니다. 반면에 ConvNet에선 매 conv layer가 끝날때마다 넣어주는 형태
- 이에 단 한 경우를 제외하고 모든 residual block에서 모든 GELU를 제거하였음
- 결과적으로 0.7% 성능 향상
- 더 적은 normalization lyaer 사용
- Transformer block은 종종 적은 norm-layer를 사용하는데, 여기에 입각하여 연구진은 2개의 BN-layer를 제거하였고 conv 1x1 layer전에 단 1개의 BN-layer만을 남겨놓았음. 이 과정을 통해 성능을 81.4%까지 끌어올렸음.
- 본 연구진은 이 구조가 기존 Transformer보다 더 적은 Norm-layer를 사용한다는 것을 밝혀냈고, 실증적으로 block이 시작할때 1개의 BN-layer를 추가하면 성능이 향상되지 않는다는 것을 밝혀냈음.
- BatchNormalization을 LayerNormalization으로 대체
- Batch-norm은 ConvNet에 있어서 필수적이지만 되게 복잡함. 이에 BN을 대체하려는 많은 연구가 있었지만 vision task에 있어서 굉장히 선호되는 옵션으로 남아있음
- 반면에 간단한 Layer Normalization(LN)은 Transformer에서 사용되어져왔고 결과적으로 좋은 성능을 냈음. 각 residual block에서 LN을 선택
- 결과적으로 81.5%로 성능을 끌어올렸음
- 다운샘플링 레이어를 분리
- ResNet에선 공간적인 다운샘플링은 각 stage에서 residual block의 앞단에 붙여졌고, Swin-T에선 분리된 다운샘플링 레이어는 2개의 stage사이에 추가되어졌음
- 이에 본 연구진은 위의 idea에서 착안하여 공간적인 다운샘플링 2x2 conv layer(strdie 2)를 사용
- 그 결과 정확도도 향상되었고 학습하는 동안 안정성도 향상되었음
필자는 ConvNext가 Swin-T의 shifted window attention과 같이 획기적인 모듈이 아니라 그저 기존에 연구했던 것들을 따로따로 적용시켜 모델을 구성했다는 것을 언급하였습니다.
Empirical Evaluations on ImageNet

Results
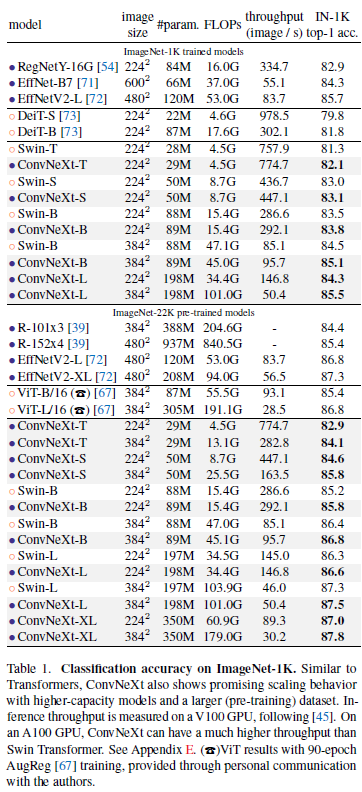
Swin-T 보다 더 간단한 모델을 사용하여 더 좋은 성능을 냈다!
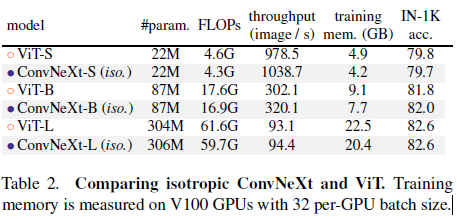
Isotropic ConvNeXt vs. ViT
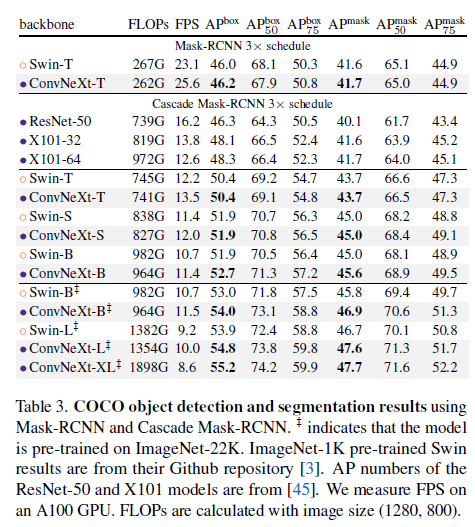
Related Work
Hybrid models. Self-attention과 convolution을 결합하는 하이브리드 모델은 활동적으로 연구되어지고 있습니다. ViT이전엔 긴 길이의 의존성을 잡기 위해 self-attention/non-local moduels를 ConvNet에 augmentation 적용하는 방법에 대해 집중하였습니다. 오리지널 ViT는 하이브리드 구성을 처음 연구했으며, 많은 후속 작업은 명시적 또는 암시적 방식으로 ViT에 컨볼루션 선행을 재도입하는 데 중점을 두었습니다.
Recent convolution-based approaches. ConvMixer, GFNet 등이 있음
Appendix
Robustness Evaluations
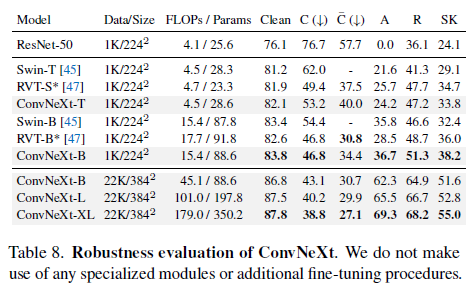
어떠한 특별한 모듈이나 추가된 파인튜닝 절차 없이 Robustness Evaluation에서 좋은 performance를 보여주었음.
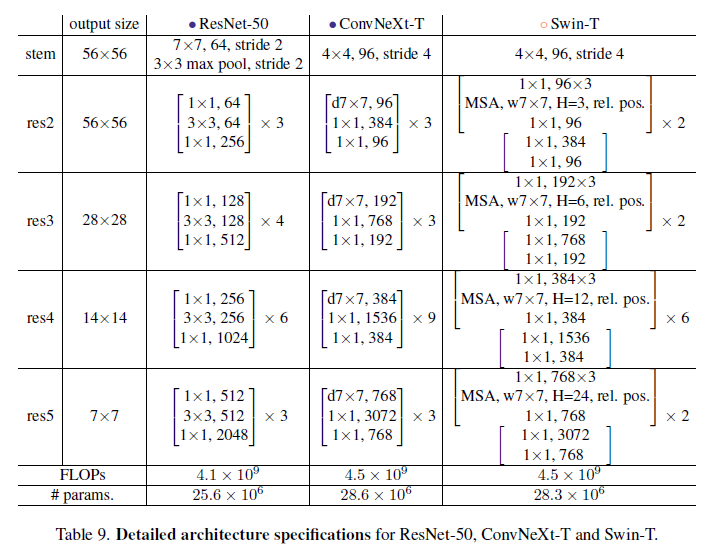
Detailed Architecture
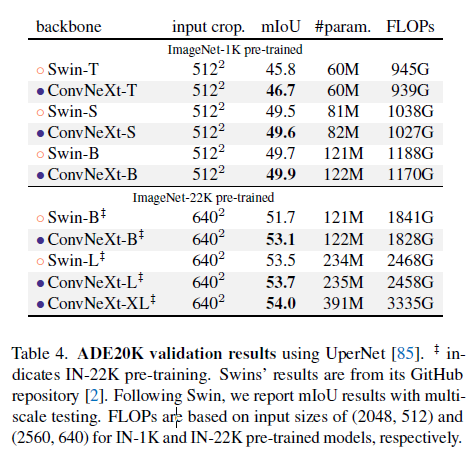
Detailed Results
한계점
순수한 ConvNet 모델인 ConvNeXt는 비젼 트랜스포머보다 다양한 vision task에서 좋은 성능을 내었습니다. 연구진의 목표는 다양한 평가 task를 아우르는 모델이었으나 생각보다 vision task는 정말로 다양합니다. Transformers가 다른 task에 매우 유연한 모델인 반면에 ConvNeXt는 좀 더 특정한 task에 더 잘 맞습니다. 여러 모달리티에 걸친 기능 상호 작용을 모델링하는 데 크로스 어텐션 모듈이 더 적합할 수 있는 예로 들 수 있습니다. 추가적으로 Transformer는 어떤 사물을 나누거나 밀도가 희박하거나 구조화된 아웃풋을 필요로하는 task에서 좀 더 유연하게 작동할 수 있습니다. 이에 연구진은 다양한 task를 충족시켜야 하기 때문에 구조적인 단순함을 선택해야했습니다.
의의
- ConvNet의 재부흥. Attention 모듈을 사용하지 않은 순수하게 Conv-layer를 사용하여 최근 Transformer 계열 모델을 따라잡은 것
- 오히려 활성화함수를 줄임으로써 성능 향상을 꾀하였음
- Simplicity 추구 !