ResNeXt - Aggregated Residual Transformations for Deep Neural Networks [2017]
Introduction
모델의 구조를 짜는 것은 많은 레이어를 가질수록 더 어렵게 되어가고 있음. VGG-net은 간단하나 효율적인 구조 전략을 내세웠음. 같은 shape을 가지는 block을 쌓음으로써 구조를 단순화 하였음. 이러한 idea를 차용한게 바로 ResNet으로 같은 topology의 모듈을 쌓은 형태의 모델임. 이 쌓는 행위의 단순한 구조는 하이퍼파라미터를 자유로운 선택을 줄여주며 depth는 신경망에서 essential dimension으로 노출되어짐. 이러한 간단한 구조가 연구진은 특정 데이터셋에서 파라미터가 과도하게 적용되는 위험을 줄여줄 수 있다고 주장. VGG-net과 ResNet의 강건성은 다양한 task에서 이미 증명되어져왔음.
VGG-net과 다른 Inception 모델류는 매우 신중하게 topology를 구성하였음. Inception 모델들은 시간이 흐르는동안 여러번 진화되어졌으나 그 중 가장 중요한 맹점은 바로 split-transform-merge 전략임. Inception 모듈에서 Input은 더 낮은 차원의 embedding으로 쪼개지고(by 1x1 conv), 특정 filter의 set으로부터 변환되고(3x3, 5x5, …), 그러고나서 concat되어짐. 이 아키텍처의 솔루션 공간은 고차원 임베딩에서 작동하는 단일 대형 레이어의 솔루션 공간의 엄격한 하위 공간임을 알 수 있음. Inception 모델의 split-transform-merge의 행위는 크고 밀도가 높은 레이어의 설명력을 제공하지만 계산 복잡도는 상당히 낮음.
좋은 성능에도 불구하고 Inception 모델은 복잡한 요인의 연속을 수반하게 됨. Filter 개수와 사이즈는 각각 개인의 변형에 맞게 되어지며 모듈들은 각각의 stage에 맞게 custom 되어짐. 이러한 구성이 좋은 결과를 내게 될지라도 새로운 데이터셋이나 task에서 Inception 모델이 잘 적용될지 불확실하며 특히 많은 요인들과 하이퍼파라미터가 존재할때 어떻게 될지 미지수.
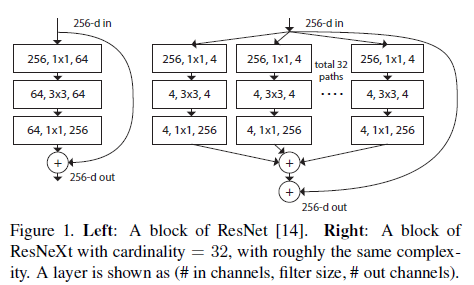
이 논문에선 VGG-net과 ResNet의 layer를 반복하는 전략과 같은 간단한 구조를 제안함과 동시에 split-transform-merge 전략을 쉽게 적용하는 방식에 대해 제안. ResNeXt의 모듈은 transformation의 set을 나타내며 각 낮은 차원의 임베딩에서의 아웃풋은 합계로 집계됨. 연구진은 집계되어지는 transformation들은 모두 같은 toplogy를 가진다는 단순한 아이디어를 추구함. 이 디자인은 특별한 form 없이 어떠한 transformation의 큰 개수가 확장되어지는 걸 가능케 만들어줌.
연구진은 2개의 동등한 형식을 가지는 모델을 만들어냈는데 이는 Inception-ResNet 모듈과 유사하며 다수의 path를 concat하지만 우리의 모듈은 모든 Inception 모듈과 조금 다름. ResNext의 모든 path를 같은 topology를 공유하기에 조사되어지기 위한 요인으로써 path의 개수는 쉽게 고립되어질 수 있음.
우리의 방법은 cardinality(변환 세트의 크기)가 폭과 깊이의 차원 외에 중심적으로 중요한 구체적이고 측정 가능한 차원임을 나타냄. Cardinality의 수를 높이는게 레이어를 더 깊고 넓게 하는것보다 더 효율적이며 정확도를 끌어올리는데 더 효과적인 방법임.
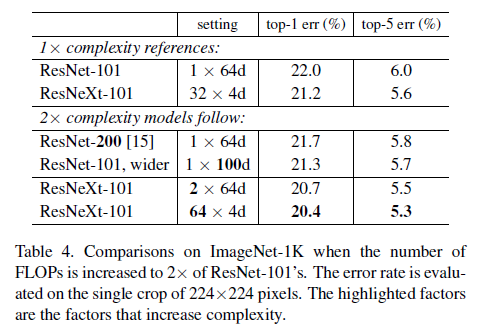
ResNeXt는 ImageNet classification task에서 ResNet-101/152, ResNet-200, Inception-v3, Inception-ResNet-v2 모델을 뛰어넘었음. 특히 ResNeXt-101은 ResNet-200 보다 높은 정확도를 달성했지만 모델의 복잡도는 그의 50% 밖에 되질 않음. 게다가 ResNeXt는 모든 Inception 모델보다 상당히 간단한 디자인임. 이에 연구진은 ResNeXt 모델이 recognition task에서 general한 모델이 되길 기대하고 있음.
Related Work
Multi-branch convolutional networks. Inception 모델은 매 branch가 신중하게 커스터마이즈 된 성공한 다중 branch 구조임. ResNet은 하나의 분기가 Identity Mapping인 2개의 branch 네트워크로 생각할 수 있음. Deep neural decision-forest는 나무패턴화 된 다중 branch 네트워크임.
Grouped convolutions. 2개의 GPU에 model을 분산 처리 가능. Grouped Conv의 특별한 경우는 바로 channel-wise conv임. 이는 group의 수와 channel의 수가 같음. Channel-wise Conv는 분리가능한 Conv의 일부분임.
Compressing convolutional networks. spatial이나 channel level에서의 분해(Decomposition)는 deep convolutional network의 중복을 줄이고, 그것들을 가속화하거나 압축화하기 위해 넓게 적용되어진 방법임. Deep roots: Improving cnn efficiency with hierarchical filter groups에선 연산을 줄이기 위해 이를 “Root-patterned network”라고 표현하였음. 이 method는 낮은 복잡도 + 작은 모델 사이즈와 함께 정확도에 대한 우아한 타협점이라고 보여짐. 대신에 본 연구진의 방법은 경험적으로 더 강한 representational power를 보여주는 구조를 차용했음.
Ensembling. 독립적으로 학습된 네트워크의 집합의 평균은 정확도를 향상시키고 recognition competition 분야에서 더 넓게 적용시키기 위한 효율적은 해결책임. 연구진은 변형의 집합을 집계하는 것을 추가하는 방법. 그러나 이는 ensembling으로써 보기에 조금 애매모호한데, 이 집합의 집계는 비독립적으로 동등하게 학습되었음.
Method
Template
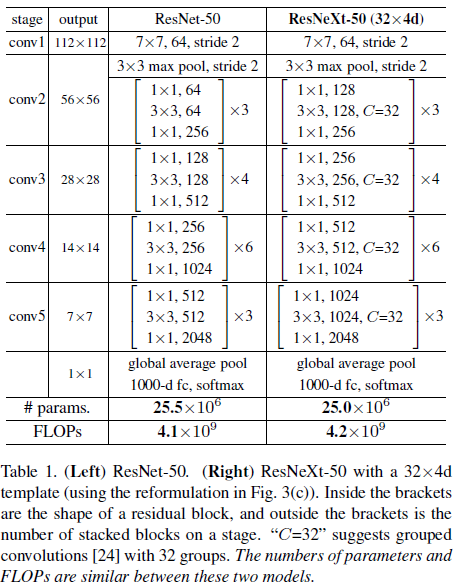
ResNeXt는 VGG/ResNet을 따르는 매우 모듈화된 디자인을 적용. 또한 residual block을 쌓아 구성하였음. 이 block들은 같은 topology를 가지고 있으며 VGG/ResNet으로부터 영감받은 2개의 단순한 규칙의 대상임.
- 만약 같은 크기의 공간 맵을 생산한다면 block은 같은 하이퍼파라미터를 공유한다
- Factor-2로부터 매번 spatial map이 downsampling 할 때, block의 width는 factor-2의 배가 됨
두 번째 rule은 FLOPs 관점에서 연산적인 복잡도를 보장하며 이는 모든 block에서 모두 같음. 오직 template 모듈을 디자인할 필요가 있고, 모든 네트워크에서의 모듈은 그에 맞게 적용되어질 수 있음. 그래서 이 2개의 룰은 design space를 크게 좁혀나가며 몇가지 중요시 되는 관점에 집중할 수 있게 해주었음.
Revisiting Simple Neurons
Aggregated Transformations
위의 단순한 neuron의 분석에 입각하여 연구진은 더 generic한 함수와 함꼐 기초적인 transformation을 대체하는걸 고려하였는데 이는 그 자신으로써 network이 될 수 있음. 차원이 깊이를 향상시키기 위한 Network-to-Network와 대조적으로 연구진은 Network-to-Neuron을 새로운 차원 사이에 확장시켰음.
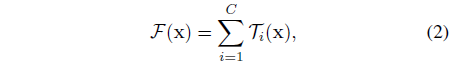
이 연구를 통해 width와 depth의 차원보다 cardinality가 더 효율적이고 필수적으로 적용되어야할 차원임을 밝혀냈음.
본 논문에서 변형 함수를 구성하는 간단한 방법을 고려하였는데 모든 $T_i$는 같은 topology를 가짐. 이는 레이어를 반복하는 VGG-스타일의 모양과 같은 전략을 확장시켰으며 이는 몇몇의 factor를 고립시키는데 효과적이며 어떠한 transformation의 큰 수가 와도 확장할 수 있음. 연구진은 개개인의 transofrmation $T_i$를 bottleneck 모양의 구조에 위치시켰음. (Figure 1 오른쪽 그림 참고). 이 경우에 첫 1x1레이어에서 각각의 $T_i$는 낮은 차원의 임베딩을 리턴시킴.
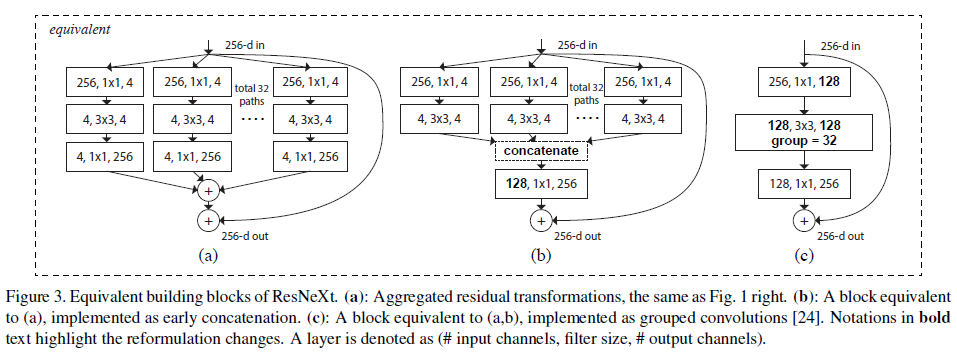
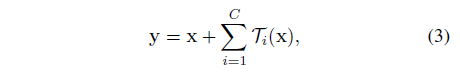
Model Capacity

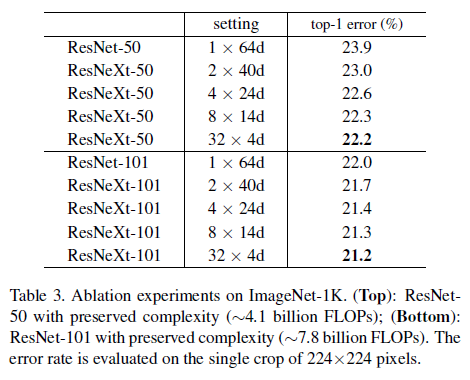
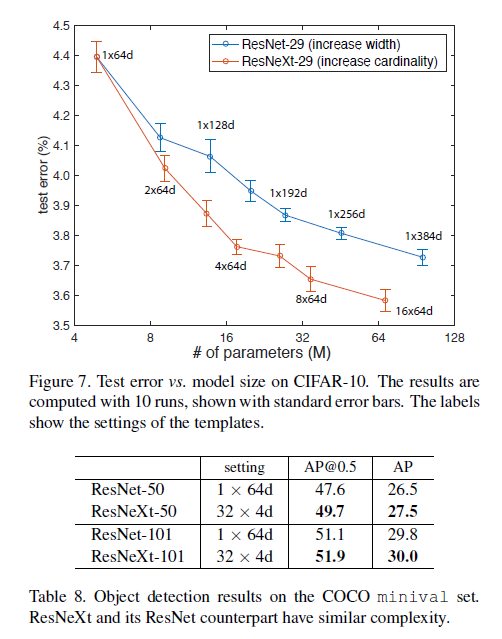
연구진은 파라미터수와 모델의 복잡성을 유지시킬때 ResNeXt 모델의 정확도가 향상한다는 것을 밝혀냈음. 복잡도를 보존하는동안 다른 cardinalities $C$를 평가할 때, 다른 하이퍼파라미터를 수정하는 것을 최소화 하였음. Input과 Ouput의 block으로부터 고립될 수 있기 때문에 bottlenect의 width를 조정하는 것을 선택하였음. 이 전략은 하이퍼파라미터를 변화시키지 않고 cardinality의 impact에 대해 집중할 수 있는걸 도와줄 수 있는 전략임.
기존의 ResNet의 bottlenect block은 $256\times64+3\times3\times64\times64+64\times256\approx70k$ 개의 매개변수를 가짐. Figure 1의 오른쪽에 나와있듯이, bottleneck width $d$와 함께 계산된 매개변수는 $C\times(256\times d+3\times3\times d\times d+d\times256)$.
$C=32$, $d=4$ 일 때, 매개변수는 70K에 근접. Table2는 cardinality $C$와 bottleneck width $d$의 관계를 보여줌.
Template section에서의 2가지 rule 적용으로 인해, ResNet bottleneck block과 ResNeXt는 모든 stage에서 근사등식(approximate equality)가 유효한 상태임.
Implementation details
- Augmentation 일환으로 scale, aspect ratio 적용
- Shorcut 적용
- Conv Downsampling 적용
- 256 mini-batch with SGD
- Weight decay 0.0001, momentum 0.9, learning_rate 0.1
- Center Crop (224, 224)
- Batch-Norm, ReLU func 사용
Experiments
생략
Experiments on ImageNet1K
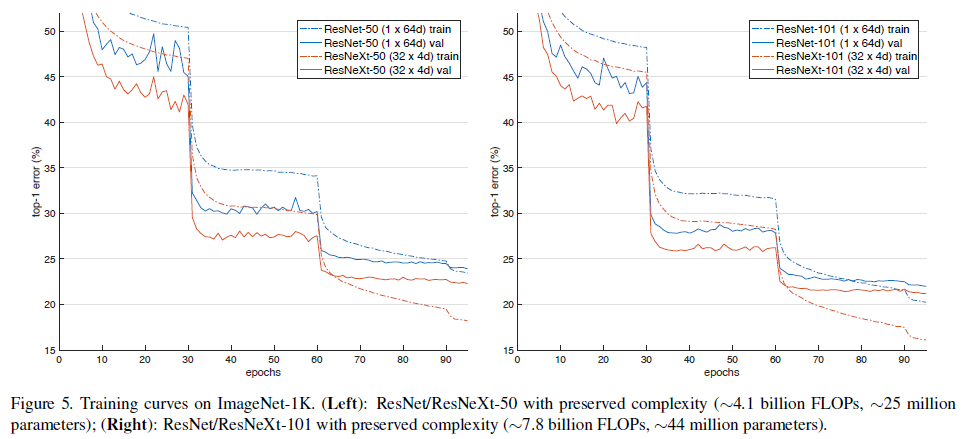
Residual Connections
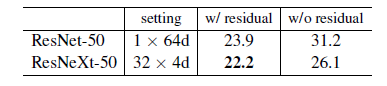
ResNeXt-50 모델에서 shortcut을 제거한 결과 error가 3.9포인트 상승하여 26.1%가 되었음. ResNet-50에선 더 안좋은 결과인 31.2%를 기록하였음. 이 비교실험은 Residual Connection 방법이 Optimization 측면에서 좋은 결과를 나타냄을 암시합니다.
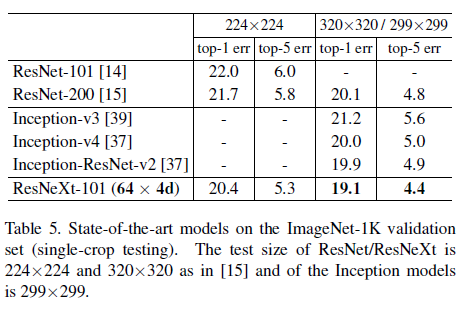
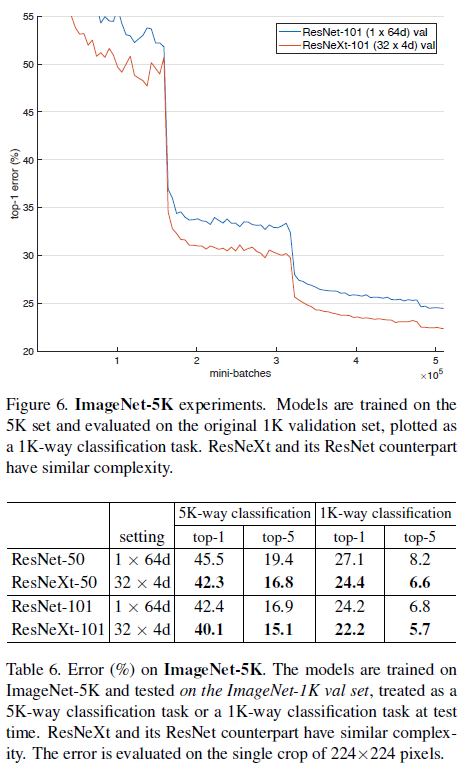
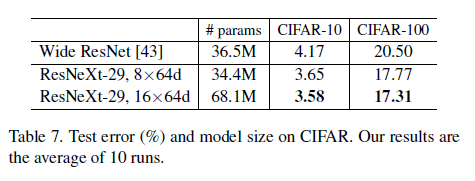
의의
- 사전 연구에서 아이디어를 얻어 Cardinality 개념 도입하여 ResNet을 고도화
- 새로운 차원 확장의 패러다임을 제시