(LLM-University) 1-2. Keyword Search
cohere - LLM University
Querying the Wikipedia Dataset Using Keyword Matching
Weaviate vector database와 cohere api를 사용하여 keyword search 알고리즘을 구현한 결과는 아래와 같습니다.
- Simple query: “Who discovered penicillin?”
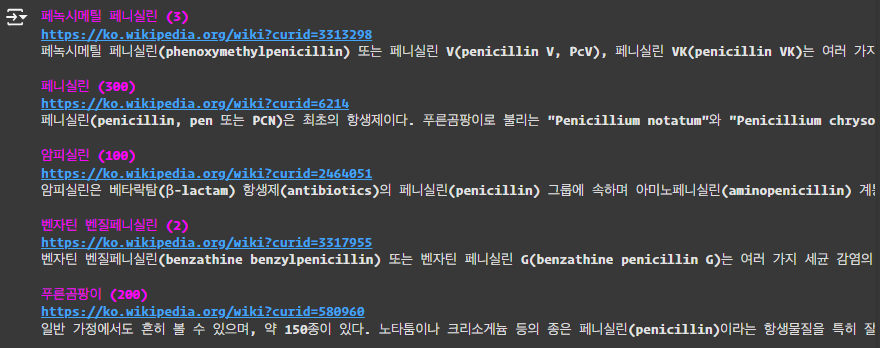
- Hard query: “Who was the first person to win two Nobel prizes?”

첫번째 simple query에 대한 유사한 vector 데이터값들은 잘 찾은 것(Weaviate vector database에 페니실린을 개발한 사람에 대한 데이터가 없는것으로 보임)으로 보이지만 두번째 hard query에 대해선 전혀 관계가 없는 vector 데이터값을 찾은것으로 나타납니다.
Conclusion
Keyword search는 벡터데이터베이스에 상응하는 양질의 query엔 좋은 결과값을 산출하지만 “Who was the first person to win two Nobel prizes?” query와 같은 벡터데이터베이스에 상응하지못한 경우엔 전혀 좋지 못한 결과값을 산출할 수도 있습니다.
Keyword search는 단어들을 기준으로 결과값을 매칭하기에 문장의 의미를 활용하진 못합니다. 이는 다음과 같은 문장에 대해선 더 어려운 과제로 인식할 수 있습니다.
“Who was the first person to win two Nobel prizes”
아마도 “first”, “person”, “win”, “two”와 같은 단어들을 포함되고 쿼리와 관련이 없는 article이 있을 수 있습니다. 게다가 벡터데이터베이스엔 “노벨상 수상”에 대한 article이 충분히 많을수있으나 “노벨상 수상을 2회나 거머쥔 Marie Curie”에 대한 article이 충분히 존재하지 않을수도 있습니다.
문장과 문장사이의 실제 의미에 대해 이해하고 단어가 아닌 그 의미에 따라 일치시킬 수 있는 semantic search, 서로 가장 관련성이 높은 문장과 문서 쌍을 표시할 수 있는 re-ranker와 같은 알고리즘을 통해 가장 적합한 문서를 도출할 수 있습니다.