QLORA - Efficient Finetuning of Quantized LLMs [2023]
Introduction
LLM을 finetuning하기에는 resource를 너~무 많이 필요로 함. 16bit로 LLaMA 65B 모델을 파인튜닝 하기 위해서는 780GB의 GPU메모리가 필요. 반면에 양자화 method는 LLM의 필요 메모리를 줄여줄 수 있음.
이에 연구진은 성능 저하 없이 quantized-4bit model 파인튜닝 하는 방법에 대해 소개. QLoRA는 4-bit로 사전학습된 모델을 양자화하기위해 독특한 high-precision technique를 사용하고 난 후에 학습가능한 LoRa 가중치의 적은 양을 추가함.
연구진은 실험에 Guanacon 계열 모델을 사용하였고 단일의 GPU만을 사용하여 학습을 진행한 결과, ChatGPT에 비교할 만한 수치를 얻어낼 수 있었음. 가장 작은 모델은 7B이며 이는 오직 메모리의 5GB만을 사용하여 Vicuna benchmark에서 Alpaca model보다 20% 높은 성능을 보였음.
QLoRA는 성능의 희생 없이 메모리를 줄일 수 있는 방법론에 대한 혁신적인 몇가지의 방법론을 제시함
- 4-bit NormalFloat
- 이론적으로 최적의 양자화 데이터 타입은 4-bit integer와 4-bit float 보다 더 나은 실증적인 결과를 산출
- Double Quantization
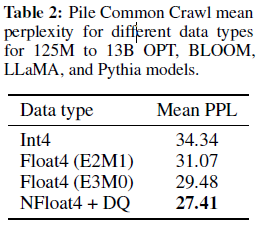
- 파라미터당 평균적으로 0.37bit 절약 가능
- Paged Optimizers
- NVIDIA를 사용하는 것은 메로리를 독립시키는데 이를 통해 긴 sequence를 mini-batch 크기로 처리할 때 나타나는 gradient checkpointing memory spike를 피할 수 있음
연구진은 실험에 1,000개의 모델을 사용하였으며 크기는 80M ~ 65B 파라미터를 가진 모델을 채택하였음.
- 데이터 품질 : OASST1 (9k) 학습 데이터셋이 FLAN v2 (450k)을 능가. chatbot task
- Massive Multitask Language Understanding(MMLU) benchmark performance는 강력한 Vicuna chatbot benchmark performace를 의미하진 않음.
chatbot performace의 확장적인 분석에 대해 연구. 주어진 prompt에 대해 토너먼트 형식으로 성능을 평가하였음. GPT-4 또는 human annotation이 대부분 승리하였음. 토너먼트 결과는 Elo score로 통합되었음. GPT-4와 사람의 평가는 토너먼트에서 모델 성능의 순위에 대체로 일치하지만, 또한 강한 불일치 사례도 발견했습니다. 따라서 저희는 모델 기반 평가가 는 사람 주석에 대한 저렴한 대안을 제공하지만 불확실성 또한 존재한다는 점을 강조합니다.
이에 quantized-Guanaco 모델을 chatbot benchmark에 적용.
Background
Block-wise k-bit Quantization Quantization은 representation딴에서 discretizing an input의 절차로 이를 통해 더 적은 정보를 representation에 많은 정보를 붙잡아 둘 수 있게 합니다. 이는 데이터 타입을 취할때, 더 많은 bit를 가져오고 더 적은 bit에서 변환시키는 것을 의미합니다(32-bit floats » 8bit Integers).
Low-rank Adapters Full-finetune model과 달리 LoRA 파인튜닝 방법은 적은 trainable 파라미터를 사용하여 필요 메모리 자체를 줄이는 방법을 의미합니다. Stochastic gradient descent을 수행하는동안의 기울기는 adapter에서 고정된 사전학습모델 기울기를 거칩니다.
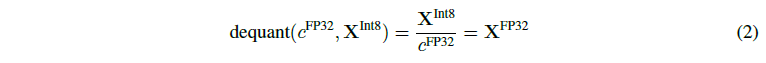
Memory Requirement of Parameter-Efficient Finetuning LoRA가 차지하는 GPU 메모리가 매우 적기 때문에, 전체적인 메모리 향상 없이 더 많은 어댑터를 성능을 향상시키는데 사용할 수 있습니다. 반면에 LoRA는 PEFT 방법을 통해 형성되었기에, 대부분의 LLM 파인튜닝을 위한 메모리 공간은 activation gradient로부터 발생되고 학습되는 LoRA 파라미터로부터 발생되진 않습니다. 대개 FLAN v2 방식을 통해 파인튜닝 할 시에 LoRA는 일반적인 학습에 비해 0.2%의 메모리 만을 사용합니다. 예를 들어, LLaMA 7B 모델을 파인튜닝 할 때, 필요 메모리는 567MB인 반면에 LoRA 파라미터는 오직 26MB만을 떠맡습니다. Gradient Checkpointing은 LoRa 파라미터의 양을 공격적으로 줄이는 것은 단조로운 메모리의 이점을 산출합니다. 이 결과를 통해 연구진은 전반적인 학습 메모리 증가 없이 더 많은 adapter를 사용하였습니다.
QLoRA Finetuning
NF4 Quantization NormalFLoat(NF) 데이터 타입은 Quantile Quantization 방식을 통해 building 하였음. 연산 memory에 대한 한계가 노출되었고 SRAM quantile과 같은 fast quantile approximation algorithms이 나왔지만 그 한계를 벗어나지 못하였음.
Double Quantization DQ는 양자화할때, 추가적인 메모리 소모를 절약해주는 방식으로 4-bit quantization을 진행할 때 적은 blocksize를 필요로하는 동안 또한 엄청난 메모리 비용을 필요로 할 수 있습니다. 예를들어 32-bit와 blocksize 64의 파라미터를 가질때 평균적으로 각 파라미터당 0.5bit을 추가해야합니다. DQ는 quantization constants의 메모리 적재량을 줄여줍니다.
Paged Optimizers offload-CPU 방식이랑 비슷한 메커니즘. Out-of-memory 에러를 방지하여 CPU RAM에 대신 적재시키는 방법.
QLoRA
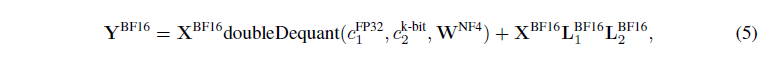
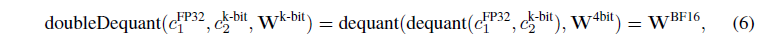
QLoRA vs Standard Finetuning
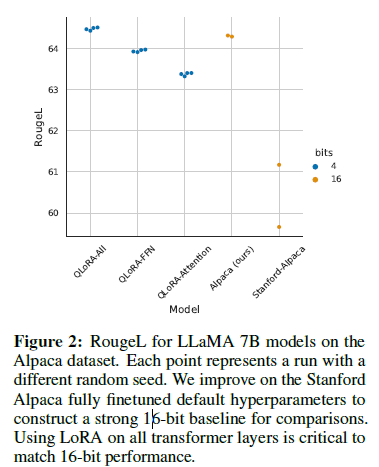
Paged_optimization방식은 큰 batch_size에서 연산 측면에서 효율적으로 작동하지 않는다
- 가장 중요한 LoRA 하이퍼파라미터는 총 사용 LoRA 어댑터 수이며, 모든 선형 트랜스포머 블록의 LoRA 레이어의 LoRA가 전체 미세 조정 성능과 일치해야 함
-
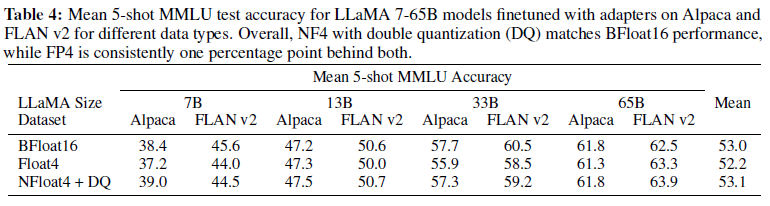
Lora_r하이퍼파라미터의 조정은 성능 향상에 있어 유의미한 결과로 나타나지 않았음 NF4방식이FP4보다 더 좋은 성능을 산출해내었음
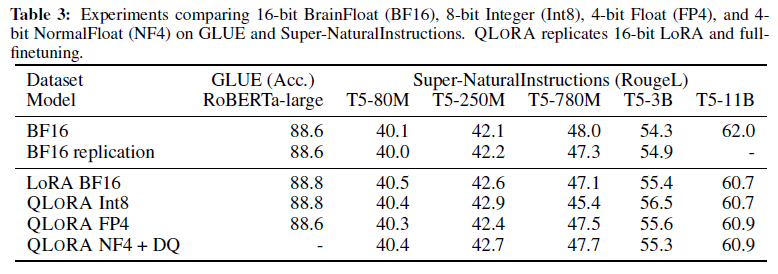
- QLoRA 방식의 모델과 BF16 모델과 비교했을 때, 성능 향상이 없을 수도 있다
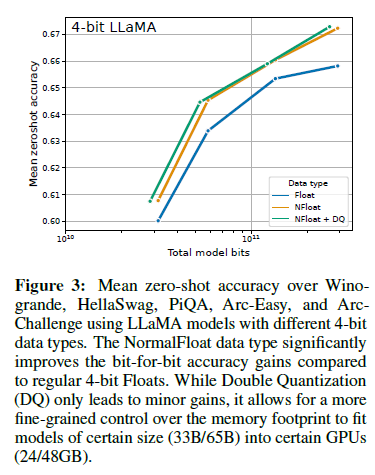
- 양자화 정밀도 관점에서 NF4 방식이 FP4 방식보다 우세하다
- NF4가 포함된 QLoRA는 16비트 전체 파인튜닝 및 16비트 LoRA 파인튜닝 성능과 유사하다
의의
- QLoRA를 통해 full-finetuning 방법론의 성능에 도달할 수 있음
- Guanaco 모델+QLoRA를 통해 Chatbot benchmark에서 SOTA 달성
- 33B, 65B 모델에선 full-finetuning 모델과 비슷한 수준이 되진 못함
etc
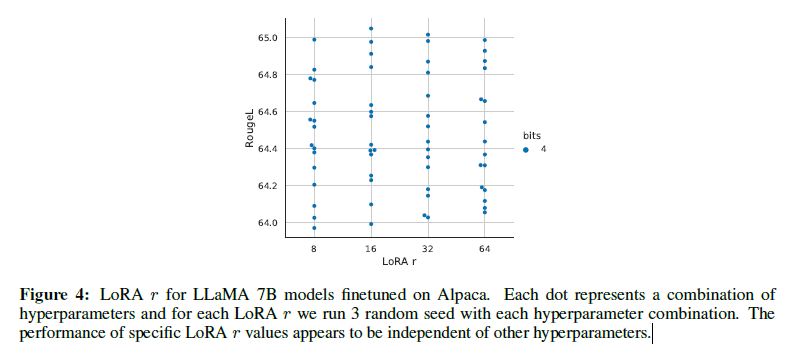
- Figure 4에 의하면
LoRA_r파라미터는 유의미한 성능을 내지 못함. default value 8로 세팅하는게 학습효율성면에서 제일 최적의 선택이 될 수 있겠다 - 13B 모델에서
LoRA_dropout0.1 설정. 모델 사이즈 커질때마다 0.05씩 증가 - 데이터셋 사이즈보단 데이터 품질에 중점을 둬라